Cid Victor H, Mork James
National Library of Medicine, Bethesda, Maryland, US.
ArXiv. 2025 Jun 3:arXiv:2506.03321v1.
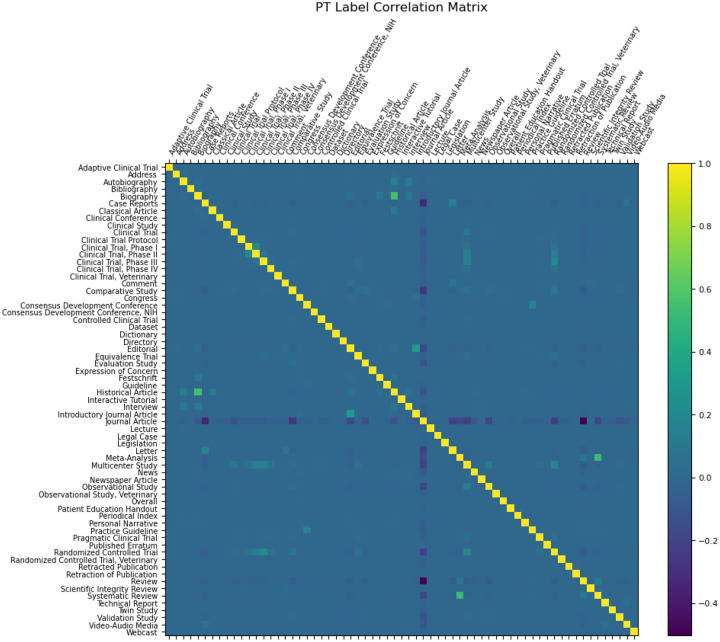
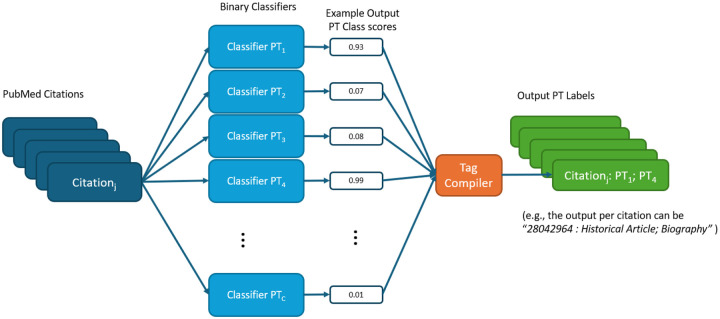
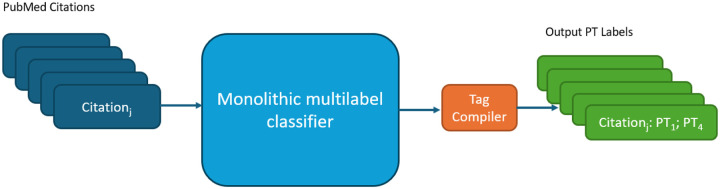
We investigated the feasibility of predicting Medical Subject Headings (MeSH) Publication Types (PTs) from MEDLINE citation metadata using pre-trained Transformer-based models BERT and DistilBERT. This study addresses limitations in the current automated indexing process, which relies on legacy NLP algorithms. We evaluated monolithic multi-label classifiers and binary classifier ensembles to enhance the retrieval of biomedical literature. Results demonstrate the potential of Transformer models to significantly improve PT tagging accuracy, paving the way for scalable, efficient biomedical indexing.
我们研究了使用预训练的基于Transformer的模型BERT和DistilBERT从MEDLINE引文元数据预测医学主题词(MeSH)出版类型(PTs)的可行性。本研究解决了当前自动索引过程中依赖传统自然语言处理算法的局限性。我们评估了整体多标签分类器和二元分类器集成,以增强生物医学文献的检索。结果表明,Transformer模型有潜力显著提高PT标签的准确性,为可扩展、高效的生物医学索引铺平了道路。