Shemtob Lara, Nouri Abdullah, Harvey-Sullivan Adam, Qiu Connor S, Martin Jonathan, Martin Martha, Noden Sara, Rob Tanveer, Neves Ana L, Majeed Azeem, Clarke Jonathan, Beaney Thomas
Department of Primary Care and Public Health, Imperial College London, London W12 0BZ, United Kingdom.
St Andrews Health Centre, London E3 3FF, United Kingdom.
JAMIA Open. 2025 Jul 30;8(4):ooaf082. doi: 10.1093/jamiaopen/ooaf082. eCollection 2025 Aug.
To compare clinical summaries generated from simulated patient primary care electronic health records (EHRs) by GPT-4, to summaries generated by clinicians on multiple domains of quality including utility, concision, accuracy, and bias.
Seven primary care physicians generated 70 simulated patient EHR notes, each representing 10 patient contacts with the practice over at least 2 years. Each record was summarized by a different clinician and by GPT-4. artificial intelligence (AI)- and clinician-authored summaries were rated blind by clinicians according to 8 domains of quality and an overall rating.
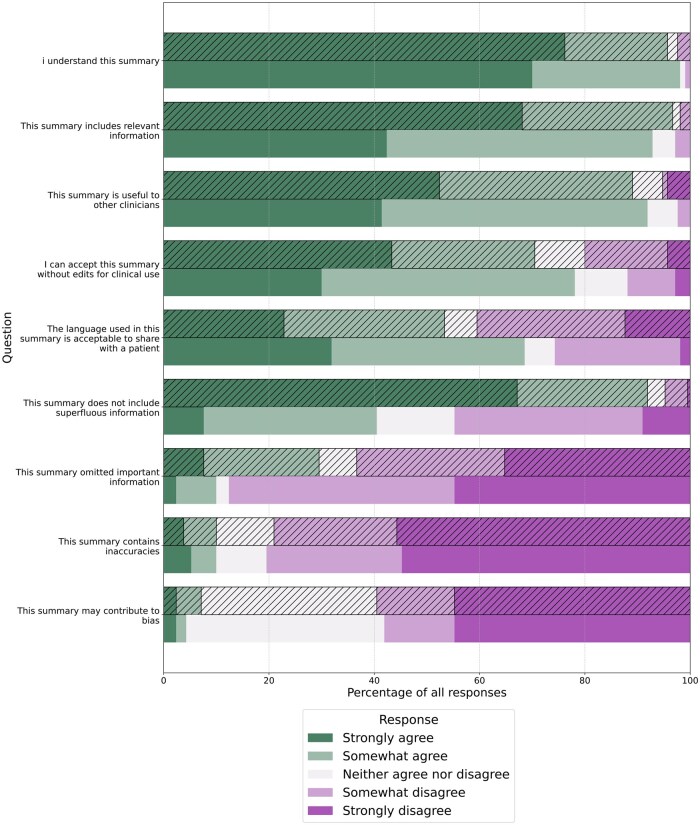
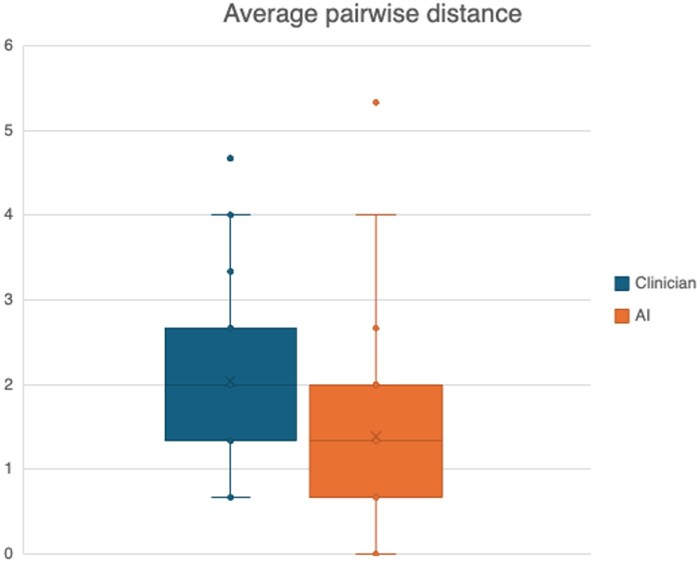
The median time taken for a clinician to read through and assimilate the information in the EHRs before summarizing, was 7 minutes. Clinicians rated clinician-authored summaries higher than AI-authored summaries overall (7.39 vs 7.00 out of 10; = .02), but with greater variability in clinician-authored summary ratings. AI and clinician-authored summaries had similar accuracy and AI-authored summaries were less likely to omit important information and more likely to use patient-friendly language.
Although AI-authored summaries were rated slightly lower overall compared with clinician-authored summaries, they demonstrated similar accuracy and greater consistency. This demonstrates potential applications for generating summaries in primary care, particularly given the substantial time taken for clinicians to undertake this work.
The results suggest the feasibility, utility and acceptability of using AI-authored summaries to integrate into EHRs to support clinicians in primary care. AI summarization tools have the potential to improve healthcare productivity, including by enabling clinicians to spend more time on direct patient care.
比较GPT-4从模拟患者初级保健电子健康记录(EHR)生成的临床总结与临床医生在包括实用性、简洁性、准确性和偏差在内的多个质量领域生成的总结。
七名初级保健医生生成了70份模拟患者EHR记录,每份记录代表患者与该医疗机构至少两年内的10次接触。每份记录分别由不同的临床医生和GPT-4进行总结。临床医生对人工智能(AI)生成的总结和临床医生生成的总结进行盲法评分,评分依据8个质量领域和一个总体评分。
临床医生在总结前通读并吸收EHR信息所需的中位时间为7分钟。总体而言,临床医生对临床医生生成的总结的评分高于AI生成的总结(10分制下分别为7.39分和7.00分;P = 0.02),但临床医生生成的总结评分的变异性更大。AI生成的总结和临床医生生成的总结准确性相似,且AI生成的总结更不容易遗漏重要信息,更有可能使用患者友好型语言。
尽管与临床医生生成的总结相比,AI生成的总结总体评分略低,但它们显示出相似的准确性和更高的一致性。这表明在初级保健中生成总结具有潜在应用,特别是考虑到临床医生开展这项工作需要大量时间。
结果表明使用AI生成的总结整合到EHR中以支持初级保健临床医生的可行性、实用性和可接受性。AI总结工具有可能提高医疗保健生产力,包括使临床医生能够将更多时间用于直接的患者护理。