Khajehnejad Moein, Habibollahi Forough, Loeffler Alon, Paul Aswin, Razi Adeel, Kagan Brett J
Cortical Labs, Melbourne, Australia.
Turner Institute for Brain and Mental Health, Monash University, Clayton, Australia.
Cyborg Bionic Syst. 2025 Aug 4;6:0336. doi: 10.34133/cbsystems.0336. eCollection 2025.
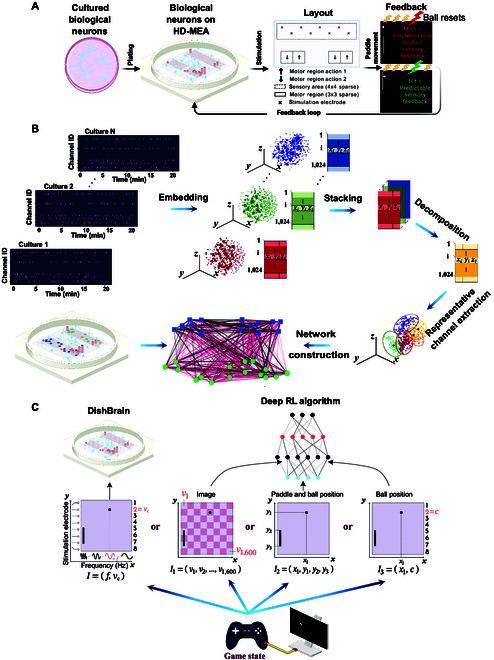
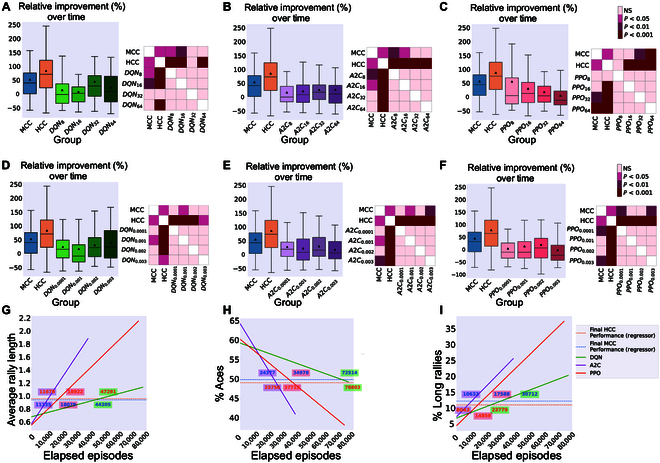
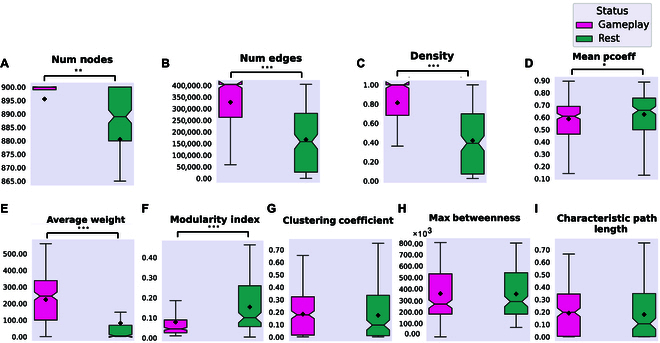
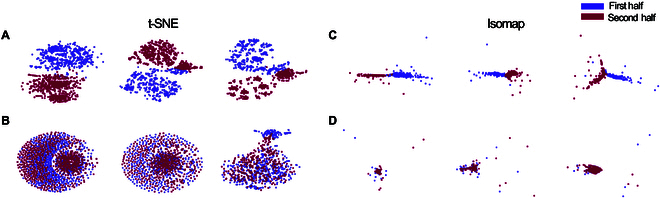
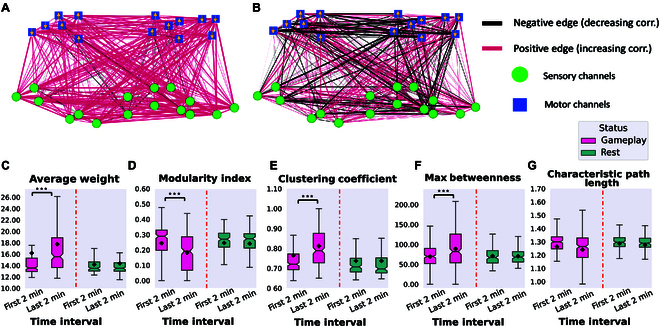
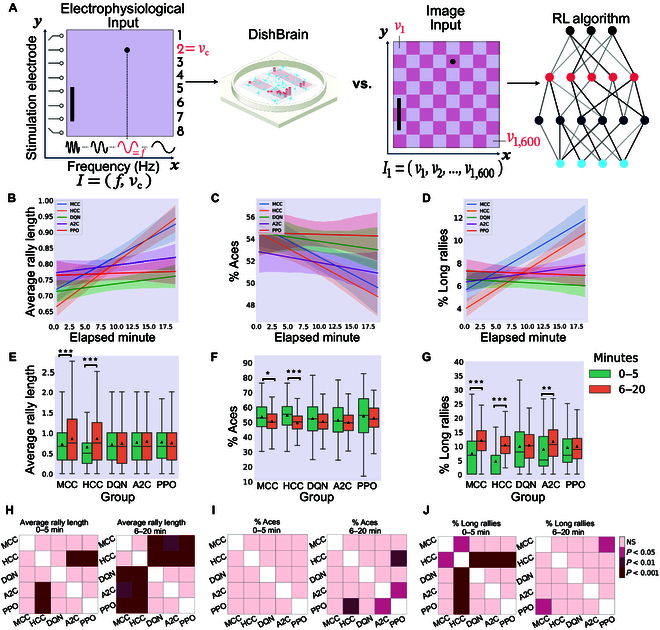
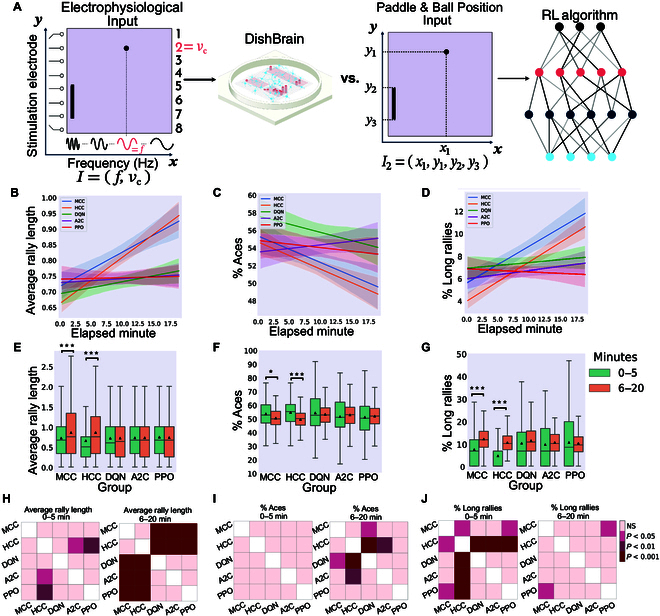
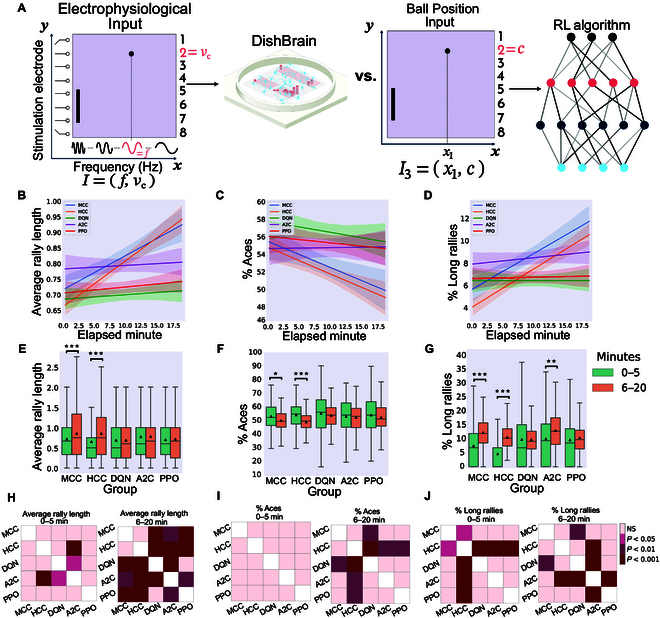
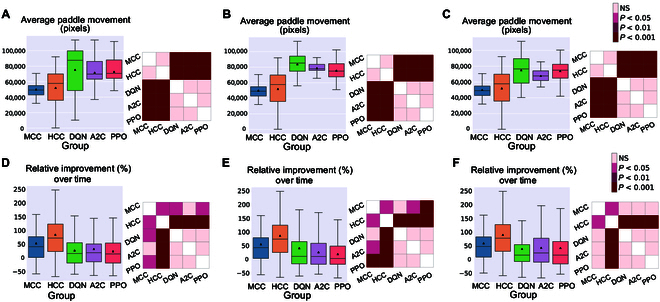
In this study, we investigate the complex network dynamics of in vitro neural systems using DishBrain, which integrates live neural cultures with high-density multi-electrode arrays in real-time, closed-loop game environments. By embedding spiking activity into lower-dimensional spaces, we distinguish between spontaneous activity (Rest) and Gameplay conditions, revealing underlying patterns crucial for real-time monitoring and manipulation. Our analysis highlights dynamic changes in connectivity during Gameplay, underscoring the highly sample efficient plasticity of these networks in response to stimuli. To explore whether this was meaningful in a broader context, we compared the learning efficiency of these biological systems with state-of-the-art deep reinforcement learning (RL) algorithms (Deep Q Network, Advantage Actor-Critic, and Proximal Policy Optimization) in a simplified Pong simulation. Through this, we introduce a meaningful comparison between biological neural systems and deep RL. We find that when samples are limited to a real-world time course, even these very simple biological cultures outperformed deep RL algorithms across various game performance characteristics, implying a higher sample efficiency.
在本研究中,我们使用DishBrain研究体外神经系统的复杂网络动力学,该系统在实时闭环游戏环境中将活神经培养物与高密度多电极阵列集成在一起。通过将尖峰活动嵌入低维空间,我们区分了自发活动(静止)和游戏状态,揭示了对实时监测和操纵至关重要的潜在模式。我们的分析突出了游戏过程中连接性的动态变化,强调了这些网络在响应刺激时具有高度样本高效的可塑性。为了探索这在更广泛的背景下是否有意义,我们在简化的乒乓模拟中,将这些生物系统的学习效率与最先进的深度强化学习(RL)算法(深度Q网络、优势演员-评论家算法和近端策略优化算法)进行了比较。通过这样做,我们在生物神经系统和深度强化学习之间进行了有意义的比较。我们发现,当样本限于真实世界的时间进程时,即使是这些非常简单的生物培养物在各种游戏性能特征方面也优于深度强化学习算法,这意味着更高的样本效率。