Zou Yongji, Ahsan Mian Umair, Chan Joe, Meng Wen, Gao Shou-Jiang, Huang Yufei, Wang Kai
Center for Cellular and Molecular Therapeutics, Children's Hospital of Philadelphia, 3501 Civic Center Boulevard, Philadelphia, PA 19104, United States.
Bioengineering Graduate Program, University of Pennsylvania, Skirkanich Hall 210 South 33rd Street, Philadelphia, PA 19104, United States.
Brief Bioinform. 2025 Jul 2;26(4). doi: 10.1093/bib/bbaf404.
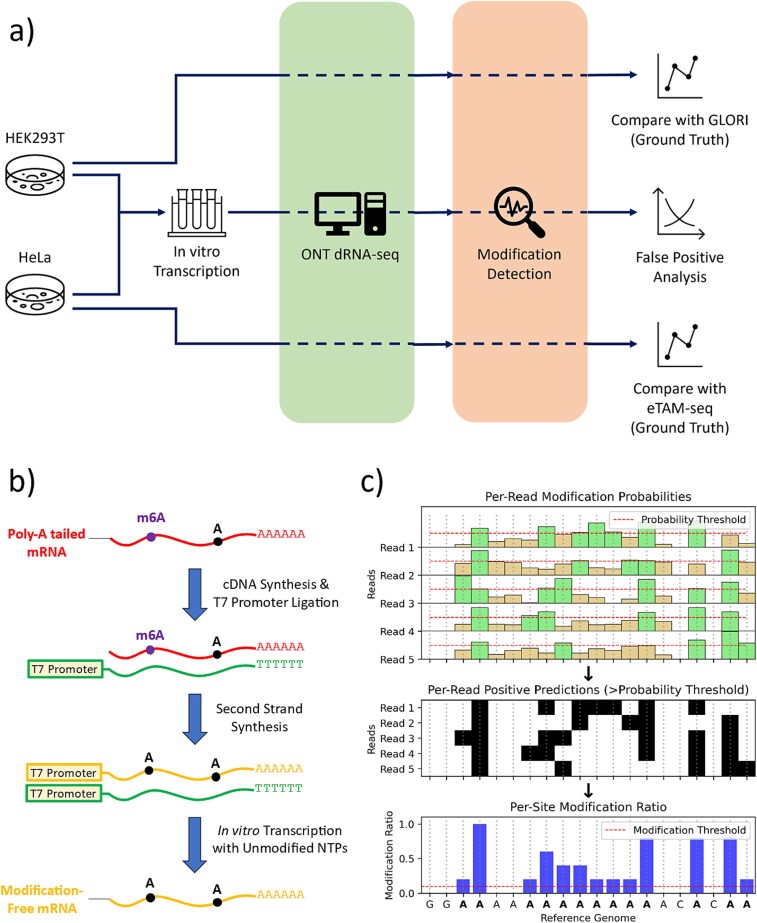
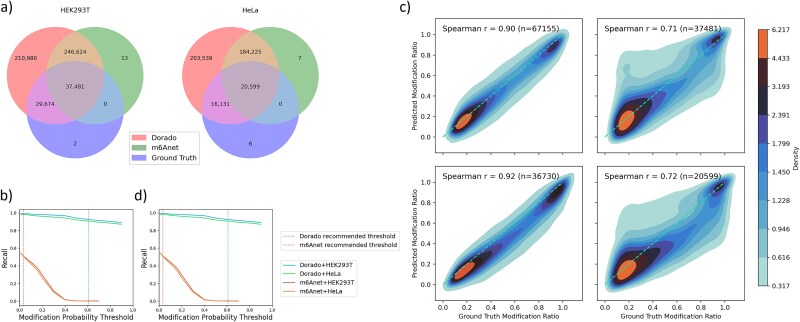
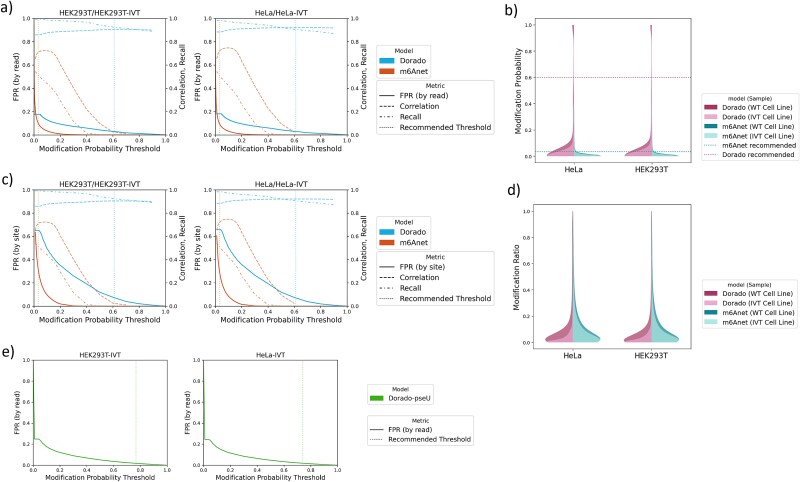
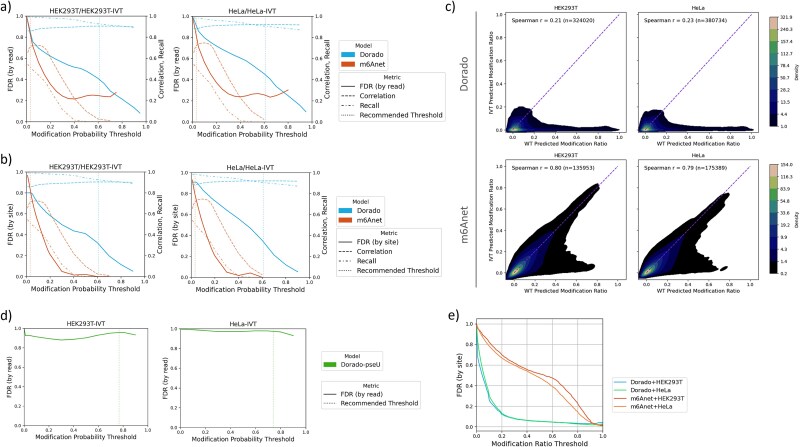
Direct RNA sequencing from Oxford Nanopore Technologies has become a valuable method for studying RNA modifications such as N6-methyladenosine (m6A) and pseudouridine (pseU). Recent advancements in the RNA004 chemistry substantially reduce sequencing errors compared to previous chemistries, promising enhanced accuracy for epitranscriptomic analysis. Here we benchmark the performance of two RNA modification detection models for RNA004 data, Dorado and m6Anet, using two wild-type (WT) cell lines (HEK293T and HeLa), with respective ground truths from GLORI and eTAM-seq, and in vitro transcribed (IVT) RNA as negative controls. We found that for m6A sites with ≥10% modification ratio and ≥ 10X coverage, Dorado has higher recall (0.92) than m6Anet (0.51). Among true positive predictions, there are high correlations of m6A modification stoichiometry (correlation coefficient of 0.89 for Dorado-truth and ~ 0.72 for m6Anet-truth). However, combined assessment of WT and IVT datasets show that while the per-site false positive rate can be lower (8% for Dorado and ~ 33% for m6Anet), both tools can have high per-site false discovery rate of m6A (40% for Dorado and ~ 80% for m6Anet), or for pseU (95% for Dorado). Motif analysis reveals that both tools exhibit high heterogeneity of false positive calls across sequence contexts. There is also a substantial overlap of false positive calls between the two IVT samples, suggesting a filtering strategy by compiling a set of low-confidence sites from diverse IVT samples. Our analysis highlights key strengths and limitations of the current generation of m6A detection algorithms and offers insights into optimizing thresholds and interpretability.
来自牛津纳米孔技术公司的直接RNA测序已成为研究RNA修饰(如N6-甲基腺苷(m6A)和假尿苷(pseU))的一种有价值的方法。与之前的化学方法相比,RNA004化学的最新进展大幅降低了测序错误,有望提高表观转录组分析的准确性。在这里,我们使用两种野生型(WT)细胞系(HEK293T和HeLa),以GLORI和eTAM-seq的各自真实数据为基准,以及以体外转录(IVT)RNA作为阴性对照,对用于RNA004数据的两种RNA修饰检测模型Dorado和m6Anet的性能进行了评估。我们发现,对于修饰率≥10%且覆盖度≥10X的m6A位点,Dorado的召回率(0.92)高于m6Anet(0.51)。在真阳性预测中,m6A修饰化学计量存在高度相关性(Dorado与真实数据的相关系数约为0.89,m6Anet与真实数据的相关系数约为0.72)。然而,对WT和IVT数据集的综合评估表明,虽然每个位点的假阳性率可能较低(Dorado约为8%,m6Anet约为33%),但两种工具在m6A(Dorado约为40%,m6Anet约为80%)或pseU(Dorado约为95%)的每个位点假发现率可能都很高。基序分析表明,两种工具在不同序列背景下的假阳性调用都表现出高度异质性。两个IVT样本之间的假阳性调用也有大量重叠,这表明通过从不同的IVT样本中汇编一组低置信度位点的过滤策略。我们的分析突出了当前一代m6A检测算法的关键优势和局限性,并为优化阈值和可解释性提供了见解。