Shoaib Muhammad, Husnain Ghassan, Khan Muhsin, Ghadi Yazeed Yasin, Lim Sangsoon
Department of Computer Science, CECOS University of IT and Emerging Sciences, Peshawar, 25100, Pakistan.
Department of Computer Science, Iqra National University, Peshawar, 25100, Pakistan.
Sci Rep. 2025 Sep 26;15(1):33122. doi: 10.1038/s41598-025-18353-8.
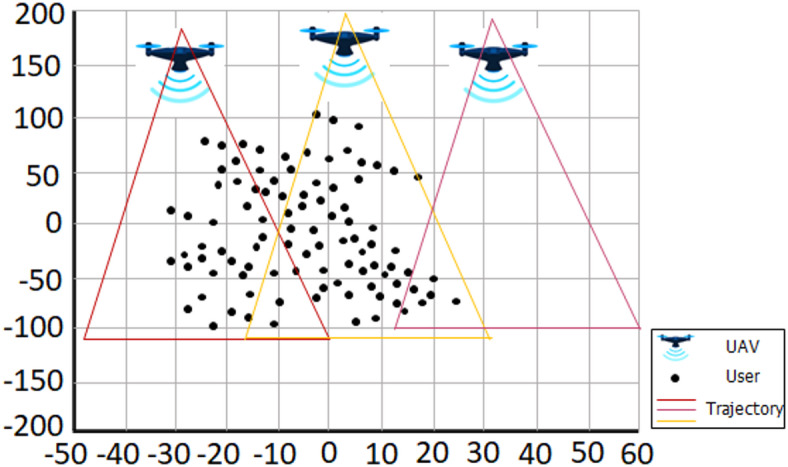
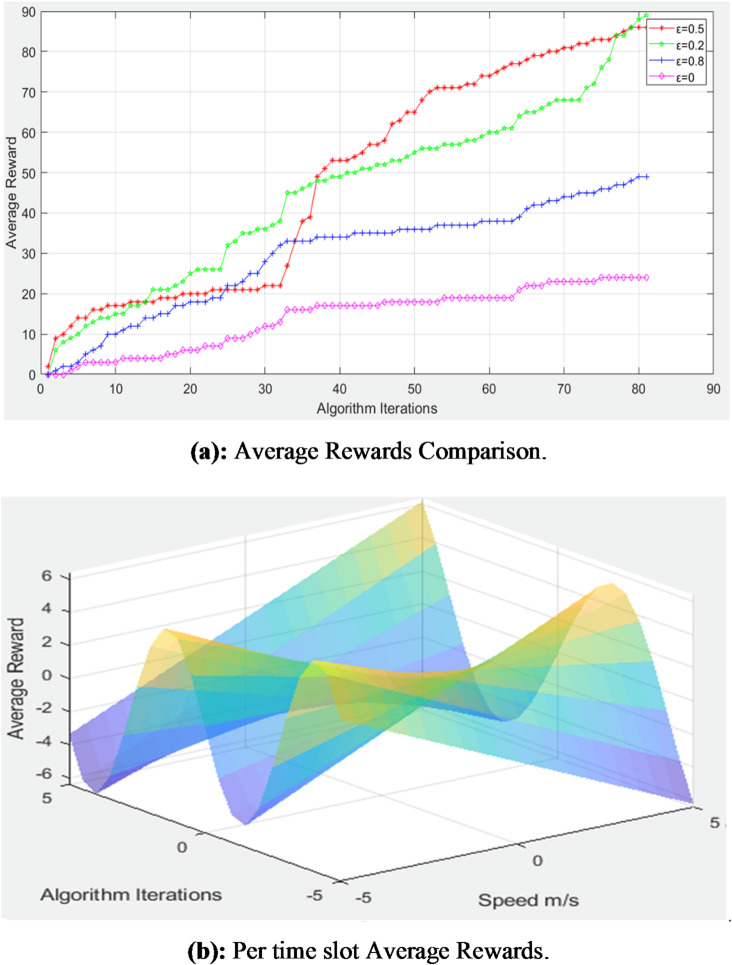
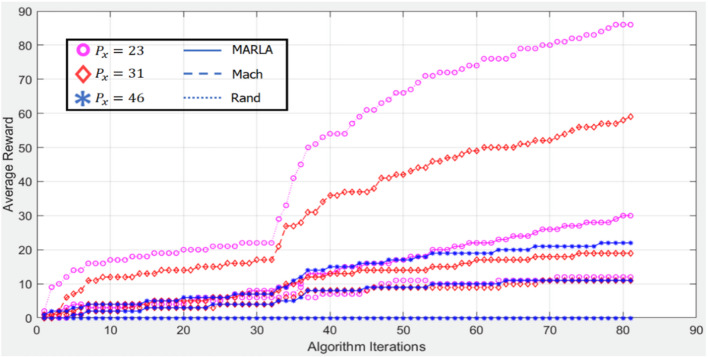
Unmanned aerial vehicles (UAVs) used as aerial base stations (ABS) can provide economical, on-demand wireless access. This research investigates dynamic resource allocation in multi-UAV-enabled communication systems with the aim of maximizing long-term rewards. More specifically, without exchanging information with other UAVs, every UAV chooses its communicating users, power levels, and sub-channels to establish communication with a ground user. In the proposed work, the dynamic scheme-based resource allocation is investigated of communication networks made possible by many UAVs to achieve the highest possible performance level over time. Specifically, each UAV selects its connected users, battery power, and communication channel independently, without exchanging information across multiple UAVs. This allows each UAV to connect with ground users. To model the unpredictability of the environment, we present the problem of long-term allocation of system resources as a stochastic game to maximize the anticipated reward. Each UAV in this game plays the role of a learnable agent, and the system solution for resource allocation matches the actions made by the UAV. Afterward, we built a framework called reward-based multi-agent learning (RMAL), in which each agent uses learning to identify its best strategies based on local observations. RMAL is an acronym for ″reward-based multi-agent learning″. We specifically offer an agent-independent strategy where each agent decides algorithms separately but cooperates on a common Q-learning-based framework. The performance of the suggested RMAL-based resource allocation method may be enhanced by employing the right development and exploration parameters, according to the simulation findings. Secondly, the proposed RMAL algorithm provides acceptable performance over full information exchange between UAVs. Doing so achieves a satisfactory compromise between the increase in performance and the additional burden of information transmission.
用作空中基站(ABS)的无人机(UAV)可以提供经济、按需的无线接入。本研究调查了多无人机通信系统中的动态资源分配,旨在最大化长期奖励。更具体地说,在不与其他无人机交换信息的情况下,每架无人机选择其通信用户、功率水平和子信道,以与地面用户建立通信。在这项拟议的工作中,研究了由多架无人机实现的通信网络基于动态方案的资源分配,以便随着时间的推移实现尽可能高的性能水平。具体而言,每架无人机独立选择其连接的用户、电池电量和通信信道,而不跨多架无人机交换信息。这使得每架无人机能够与地面用户建立连接。为了模拟环境的不可预测性,我们将系统资源的长期分配问题表示为一个随机博弈,以最大化预期奖励。此博弈中的每架无人机都扮演一个可学习智能体的角色,资源分配的系统解决方案与无人机采取的行动相匹配。之后,我们构建了一个名为基于奖励的多智能体学习(RMAL)的框架,其中每个智能体基于局部观测使用学习来识别其最佳策略。RMAL是“基于奖励的多智能体学习”的首字母缩写。我们特别提供了一种与智能体无关的策略,其中每个智能体分别决定算法,但在一个基于Q学习的通用框架上进行协作。根据仿真结果,通过采用合适的开发和探索参数,可以提高所建议的基于RMAL的资源分配方法的性能。其次,所提出的RMAL算法在无人机之间进行完全信息交换时提供了可接受的性能。这样做在性能提升和信息传输的额外负担之间达成了令人满意的折衷。