TITAN问世:哈佛团队打造病理学“通才”模型,33万张全切片读懂癌症语言
学术资讯

在计算病理学的世界里,人工智能(AI)早已不是新鲜事。从自动识别肿瘤区域到辅助癌症分级,AI工具正在以前所未有的速度重塑诊断流程。长期以来,业界的主流策略是将巨大的病理切片切割成成千上万个微小的“感兴趣区域”(ROIs),就像通过无数个锁孔去观察一个庞大的世界,试图通过拼接碎片来理解全貌。这种基于图块(Patch-based)的基础模型在捕捉局部组织结构和细胞形态方面确实表现出色。
然而,临床诊断的真相往往隐藏在“森林”而非“树木”之中。
一张全切片图像(Whole-Slide Image, WSI)的分辨率往往高达十亿像素级,其中不仅包含细胞的微观细节,更蕴含着组织结构、微环境以及病灶分布的宏观逻辑。单纯依赖图块嵌入,往往难以捕捉这种长距离的上下文信息。更棘手的是,面对罕见病或缺少标注数据的临床困境,现有的模型往往显得捉襟见肘。如何让AI不仅能“看清”局部,更能像资深病理学家一样“读懂”整张切片,甚至理解与之对应的复杂的临床病理报告,成为了当前计算病理学面临的一道鸿沟。
为了跨越这道鸿沟,来自哈佛医学院麻省总医院布里格姆分院(Mass General Brigham)的研究团队在《Nature Medicine》上发表了最新重磅研究,提出了一种名为 TITAN (Transformer-based pathology Image and Text Alignment Network) 的多模态全切片基础模型。这项研究不仅利用了数十万张全切片图像进行预训练,更创新性地引入了生成式AI作为“副驾驶”,通过合成精细的形态学描述,让模型学会了人类的诊断语言。
TITAN 的诞生并非一蹴而就,它代表了病理学基础模型从“单模态视觉”向“多模态视觉-语言”的范式转变。研究团队构建了一个庞大的内部数据集 Mass-340K,包含来自20个不同器官、涵盖多种染色和扫描仪类型的335,645张全切片图像。这为TITAN提供了极具多样性的“学习素材”。
TITAN 的核心是一个基于 Transformer 的视觉编码器(ViT),但它的训练策略展现了精妙的层级递进设计。如图[1]所示,TITAN 的预训练过程就像是一个医学生的进阶之路,分为三个精心设计的阶段:
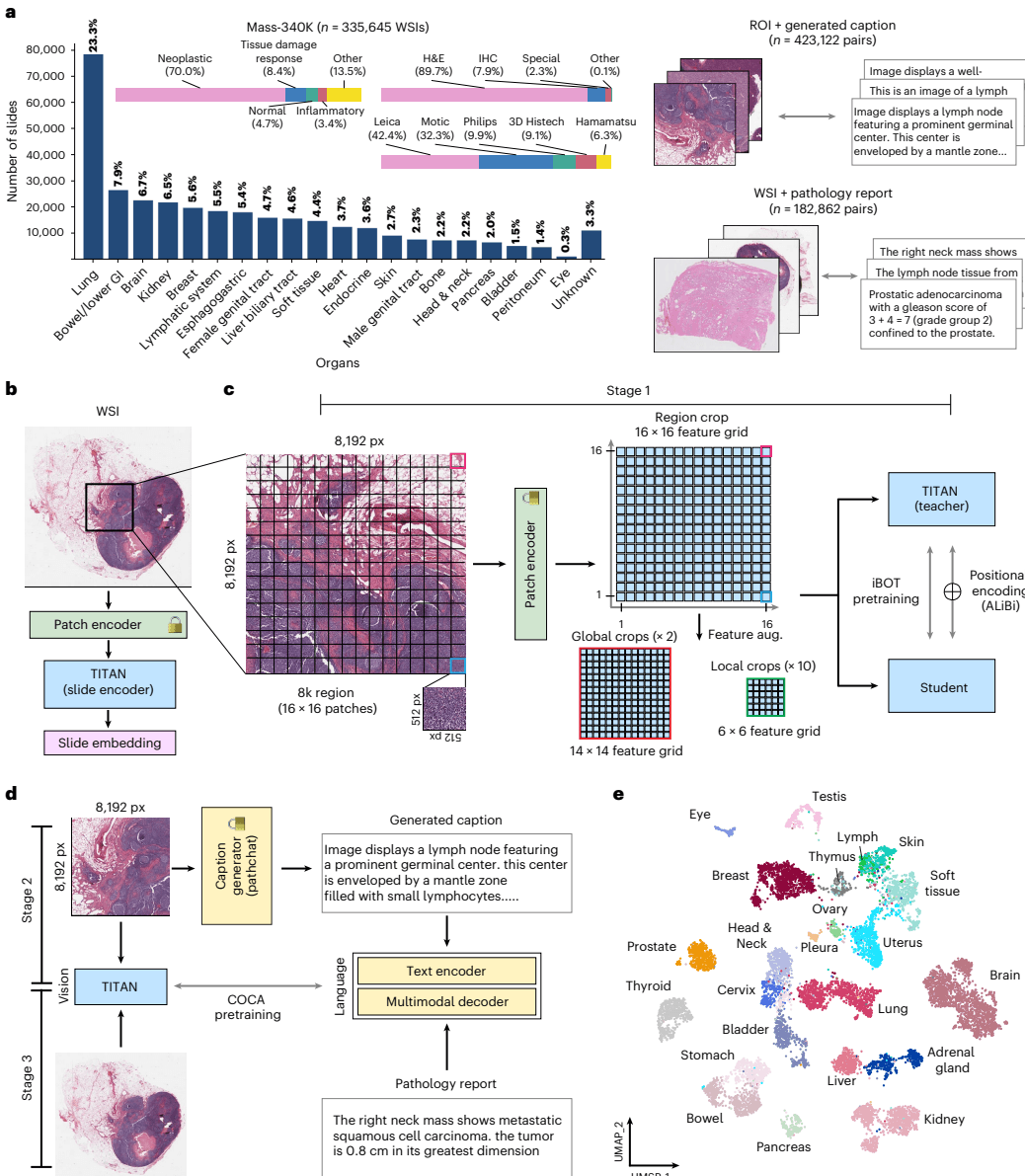
从图[1]的架构中我们可以清晰地看到,TITAN 摒弃了传统的将切片视为“一袋特征”(bag of features)的做法,而是通过 Transformer 显式地建模了长距离的上下文关系。为了处理全切片那惊人的尺寸,研究人员采用了一种“短练长测”(Train Short, Test Long)的策略:在预训练时使用 8192 x 8192 像素的区域裁剪(Region Crops),而在推理时利用带有线性偏差的注意力机制(ALiBi)外推至整张全切片。这种设计既保证了计算效率,又保留了模型对全局信息的掌控能力。
通过这一系列复杂的“特训”,TITAN 不再是一个只会数细胞的工具,而是一个能够理解病理语义、具备多模态交互能力的“通才”。接下来,我们将看到这位“通才”在各项严苛测试中的惊人表现。
为了检验 TITAN 的成色,研究团队将其置于一场“诸神之战”中,与当前最顶尖的病理基础模型——包括 PRISM、GigaPath 和 CHIEF——进行了全方位的正面交锋。结果表明,TITAN 不仅在性能上全面领跑,更在效率上实现了反超。
“参数更少,性能更强”是 TITAN 给出的第一份答卷。 在深度学习领域,通常认为模型越大越好,但 TITAN 打破了这一迷信。从图[2]中我们可以看到,尽管 TITAN(4850万参数)和其视觉版本 TITAN_v(4210万参数)的参数量仅为竞争对手 PRISM(9900万参数)和 GigaPath(8630万参数)的一半左右,但它们在各项任务中的平均表现却稳居榜首。这证明了 TITAN 独特的预训练策略——尤其是结合了高分辨率区域裁剪和多模态对齐——比单纯堆砌参数更为有效。
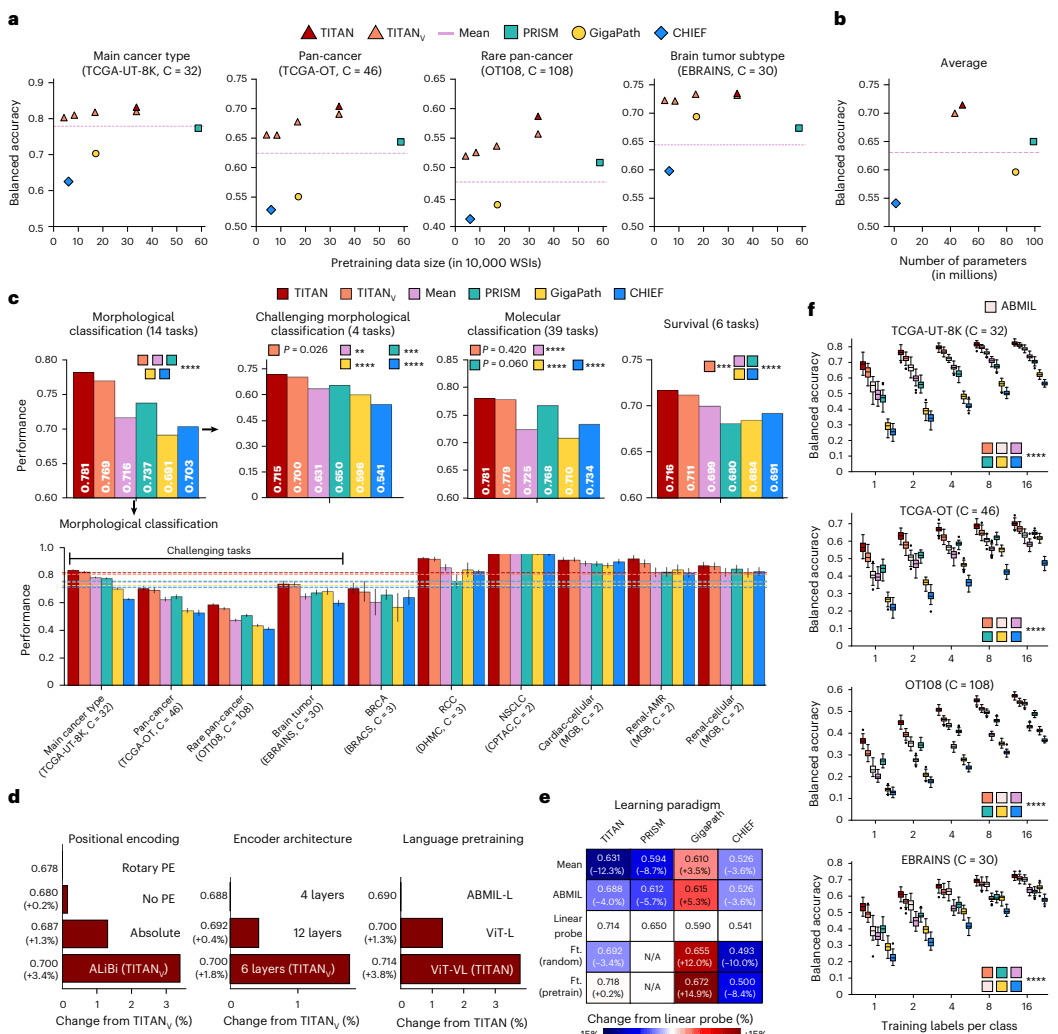
在具体的临床任务上,TITAN 展现出了令人惊叹的全面性:
更为关键的是,TITAN 在“少样本学习”(Few-Shot Learning)场景下展现出了统治级的实力。
临床现实中,罕见病往往面临样本极度匮乏的困境。如图[2]f所示,在仅提供极少量样本(例如每个类别仅1个或几张切片)的情况下,TITAN 的表现令人印象深刻。特别是在极具挑战性的 OT108 罕见癌症分类任务中,当仅使用1个样本(1-shot)进行训练时,TITAN 的性能甚至超过了许多使用了更多样本的监督学习模型(如 ABMIL)。这意味着,对于那些发病率极低、数据稀缺的罕见肿瘤,TITAN 能够成为病理医生强有力的辅助工具,无需海量标注数据即可快速上手。
如果说之前的测试展示了 TITAN 敏锐的“视觉”,那么其多模态能力则赋予了它表达的“嘴巴”和理解的“大脑”。得益于第二阶段(ROI与合成描述对齐)和第三阶段(全切片与临床报告对齐)的训练,TITAN 打通了像素与自然语言之间的壁垒,实现了真正意义上的图文互通。
零样本分类(Zero-Shot Classification):未见其人,先闻其声。
在传统的AI诊断中,模型必须先学习带有标签的数据才能识别特定的疾病。然而,TITAN 具备了“零样本”分类的能力。这意味着,即使从未在训练集中见过某种具体的癌症亚型,只要给它一个文本描述(例如“具有乳头状结构的肾细胞癌”),它就能通过理解文本与图像特征的匹配度来做出诊断。
如图[3]a所示,研究人员将诊断标签转换为文本提示(Prompts),TITAN 就能在巨大的特征空间中寻找与这些描述最接近的切片。测试结果令人咋舌:在涵盖13个不同难度的亚型分类任务中,TITAN 的表现全面碾压了同样具备多模态能力的 PRISM 模型。如图[3]b所示,在多类别分类任务中,TITAN 的平衡准确率平均领先 PRISM 高达 56.52%!特别是在极度复杂的 EBRAINS 脑肿瘤分类(30个类别)中,TITAN 的准确率几乎是 PRISM 的两倍。这得益于 TITAN 在预训练阶段摄取了海量精细的形态学描述,使其对病理特征的理解细致入微。
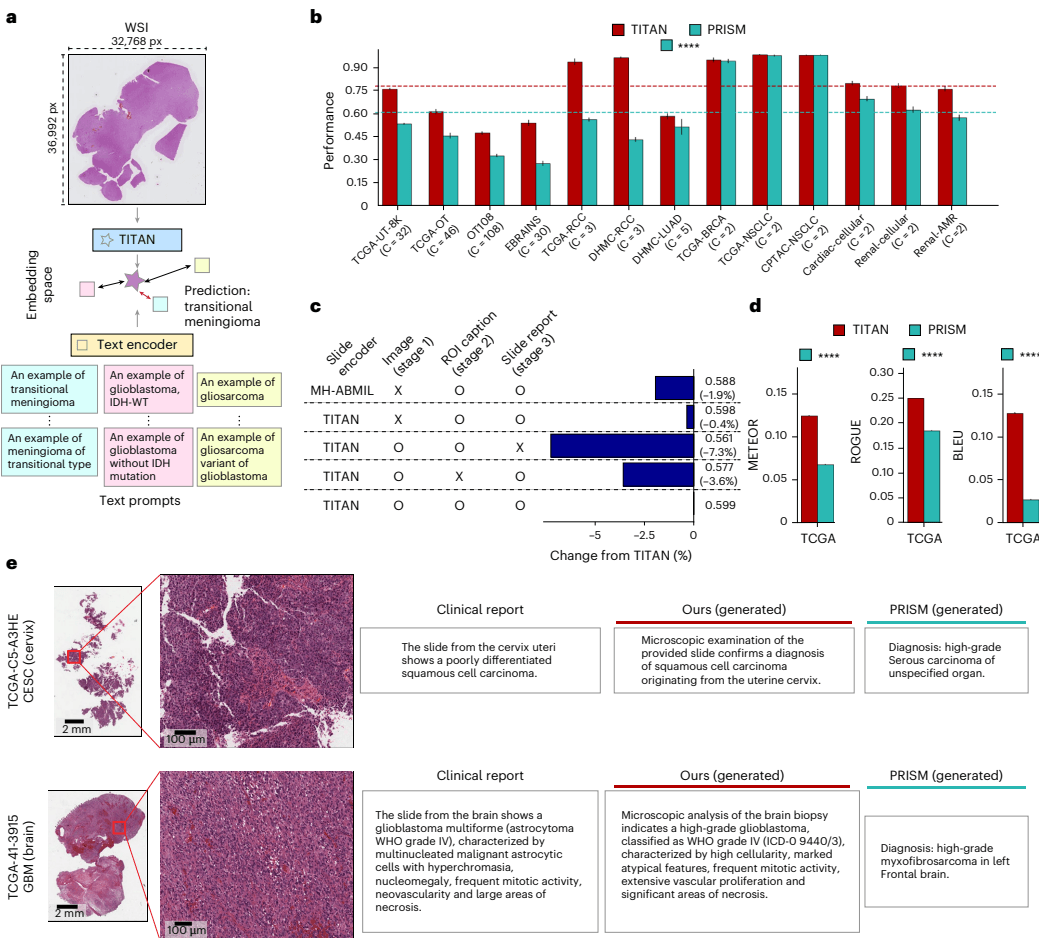
自动报告生成:AI病理医生的“书写”初体验。
更令人兴奋的是,TITAN 还能像病理医生一样撰写诊断报告。这不仅仅是简单的分类标签输出,而是生成包含组织部位、诊断结果、肿瘤分级甚至微观形态描述的完整文本。
从图[3]e中我们可以直观地看到 TITAN 与竞品生成的报告对比。面对一张胶质母细胞瘤(GBM)的切片,临床报告描述了“明显的核异型性”、“血管增生”和“坏死”等特征。TITAN 生成的报告不仅准确识别了“胶质母细胞瘤,WHO IV级”,还精准地描述了“血管增生”和“坏死区域”等关键形态学证据。相比之下,PRISM 生成的报告则显得离题万里,错误地将其诊断为“转移性肉瘤”。
这种“言之有物”的能力,使得 TITAN 不再是一个黑盒模型。医生不仅可以看到诊断结果,还能通过阅读AI生成的描述,验证AI的判断依据,极大地增强了临床应用的可解释性和信任度。
对于病理医生而言,遇到罕见或疑难病例就像侦探遇到了棘手的悬案。此时,如果能从历史数据库中迅速找到形态相似的确诊病例作为参考,将是破案的关键。TITAN 强大的特征提取能力,使其变身为一个高效的“以图搜图”引擎,即使是在数据极度稀缺的罕见癌症领域,也能精准锁定目标。
罕见癌症检索:在数万样本中精准定位。
为了测试这一能力,研究团队构建了一个极具挑战性的“罕见癌症检索”任务。他们混合了常见的癌症类型和发病率极低的罕见癌症(如副神经节瘤、肾上腺皮质癌等),构建了一个庞大的数据库。如图[4]a所示,TITAN 在检索准确率(Accuracy@K)上大幅领先于其他所有模型。这意味着,当输入一张罕见的癌症切片时,TITAN 推荐的前几张相似切片中,包含正确诊断的概率最高。
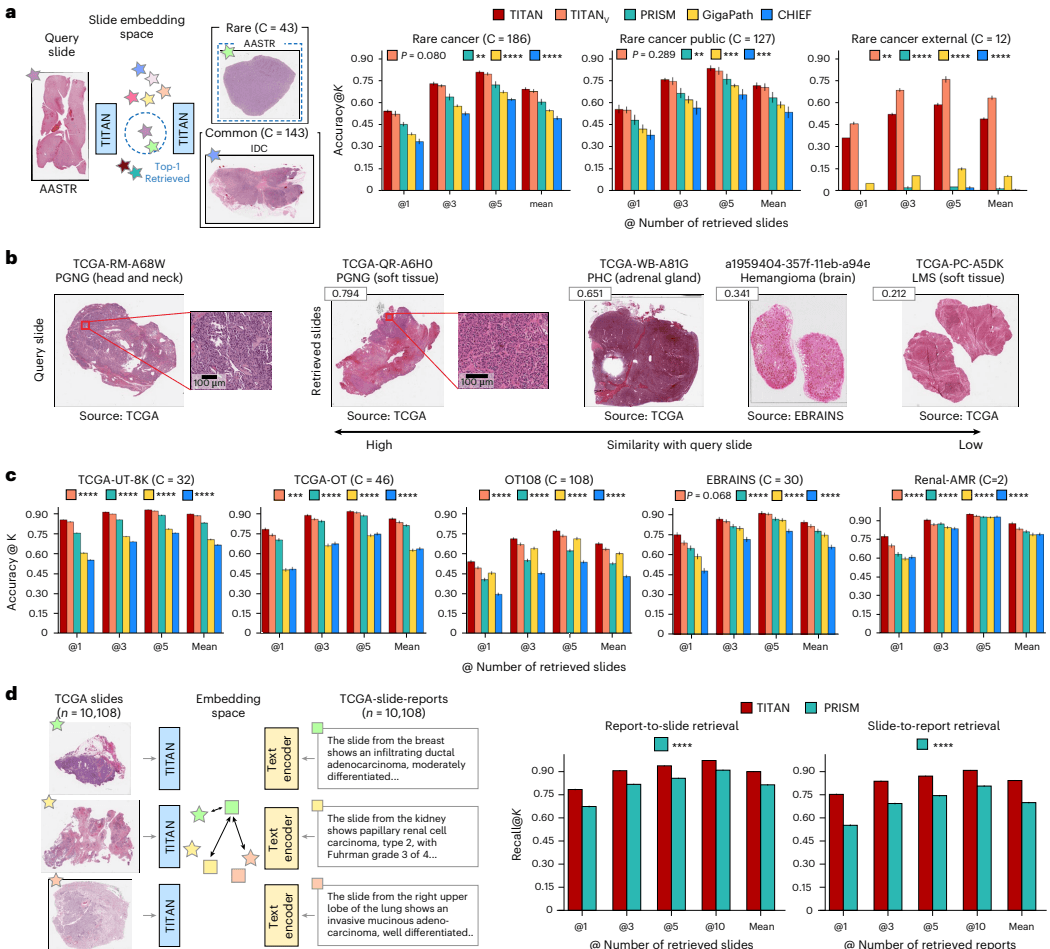
一个生动的例子展示在图[4]b中:当查询一张来自软组织的“副神经节瘤”切片时,TITAN 检索到的最相似切片(相似度0.794)准确地命中了两例同类型的副神经节瘤,甚至还检索到了一例“嗜铬细胞瘤”(相似度0.651)。这非常耐人寻味,因为嗜铬细胞瘤和副神经节瘤在病理形态和生物学行为上确实高度相关。这表明 TITAN 不仅是在做简单的像素匹配,而是真正捕捉到了疾病潜在的生物学联系。
更令人振奋的是,在跨机构的外部验证集(Rare-Cancer-External)上,TITAN 展现出了极强的鲁棒性。面对来自日本一家医院、使用不同染色和扫描设备的数据,TITAN 依然能够准确检索,性能并未像其他模型那样大幅衰减。这对于AI模型的临床落地至关重要,因为它证明了 TITAN 能够克服不同医院间的数据差异。
跨模态检索:用文字搜索切片,用切片搜索报告。
除了“以图搜图”,TITAN 还实现了“图文互搜”。医生可以输入一段描述(如“伴有印戒细胞特征的胃癌”),系统就能瞬间从数据库中调出符合描述的切片;反之,输入一张切片,系统也能推荐与之匹配的历史病理报告。如图[4]d所示,在 TCGA 数据集上,TITAN 在图文双向检索的召回率上均显著优于 PRISM。这种能力为构建下一代智能病理数据库铺平了道路,让沉睡的历史数据变成了触手可及的知识宝库。
TITAN 的出现,标志着计算病理学正在迈向一个全新的阶段。它不再满足于在单一任务上与其竞争对手通过微弱的优势一决高下,而是试图通过构建一个对病理图像和语言有深刻理解的通用基础模型,来一站式解决分类、预后、检索和报告生成等多种临床需求。
当然,TITAN 并非完美无缺。其基于 Transformer 的长上下文外推能力虽然强大,但在处理极端尺寸的切片时仍可能面临挑战;此外,如何进一步消除不同医疗中心之间的数据偏见,也是未来需要持续优化的方向。但毫无疑问,TITAN 为我们展示了一个令人憧憬的未来:AI 将成为病理医生身边最博学、最敏锐的“全能助手”,共同为精准医疗保驾护航。
本文由超能文献AI辅助创作,内容仅供学术交流参考,不代表任何医学建议。
分享

覆盖104项研究的综合分析显示,92%的研究证实超加工食品与慢性病相关。这场由跨国食品公司主导的饮食革命,正在成为21世纪最严重的公共卫生威胁之一。

从数年到数周,AI正在重新定义癌症免疫治疗的时间表。丹麦与美国科学家开发的AI平台,能快速设计出"分子钥匙",让患者自身的T细胞精准识别并摧毁肿瘤细胞。

Nature发表的盲测研究显示,谷歌医疗AI AMIE在159个临床场景中诊断准确率、沟通能力均优于全科医生。但文字对话模式的局限性提醒我们:这不是真实医疗的全貌。

Stanford Medicine追踪108人数年,分析13.5万种分子,发现衰老并非匀速过程,而是在44岁和60岁出现两次剧烈波动,心血管、代谢、免疫系统均受影响。