Anderson Abraham, Hudson Matthew, Chen Wenqiong, Zhu Tong
Torrey Mesa Research Institute, Syngenta Research and Technology, 3115 Merryfield Row, San Diego, CA 92121, USA.
BMC Genomics. 2003 Jul 10;4(1):26. doi: 10.1186/1471-2164-4-26.
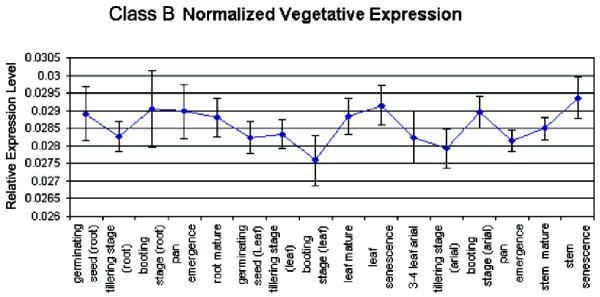
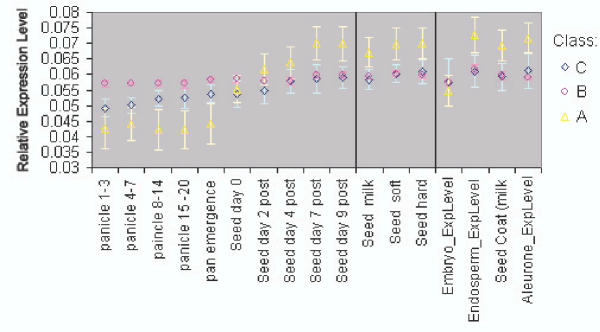
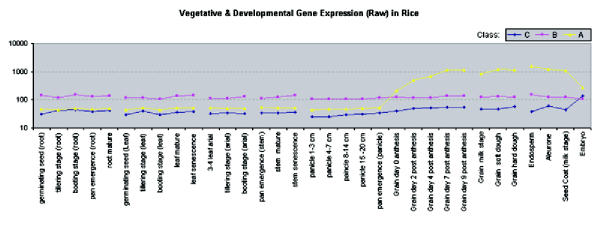
In order to identify rice genes involved in nutrient partitioning, microarray experiments have been done to quantify genomic scale gene expression. Genes involved in nutrient partitioning, specifically grain filling, will be used to identify other co-regulated genes, and DNA binding proteins. Proper identification of the initial set of bait genes used for further investigation is critical. Hierarchical clustering is useful for grouping genes with similar expression profiles, but decreases in utility as data complexity and systematic noise increases. Also, its rigid classification of genes is not consistent with our belief that some genes exhibit multifaceted, context dependent regulation.
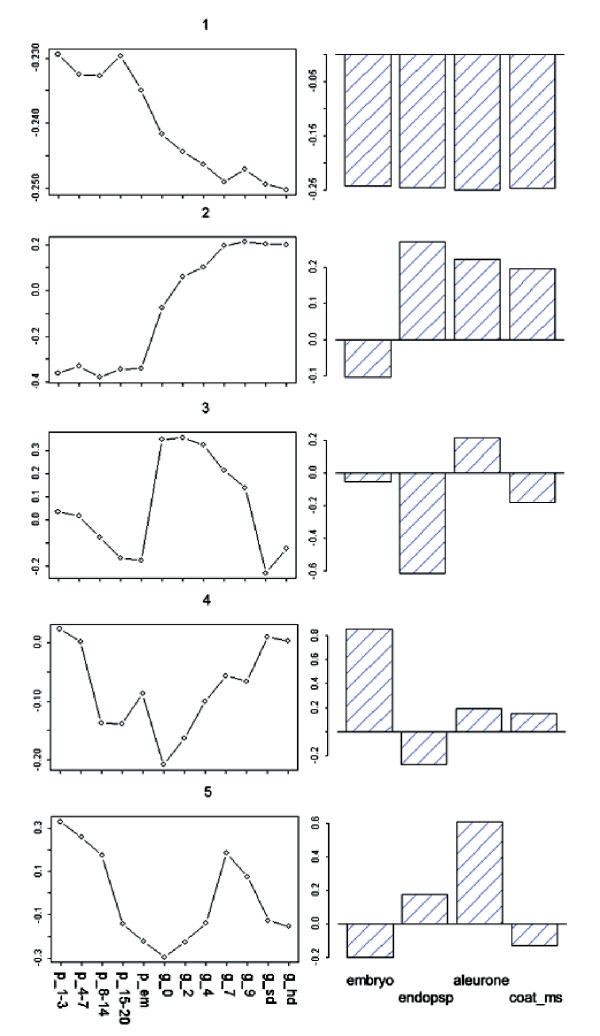
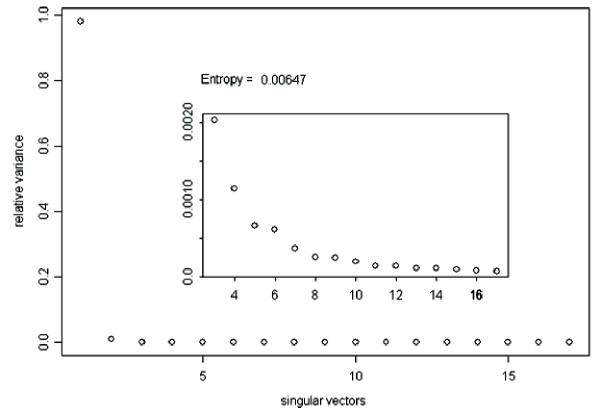
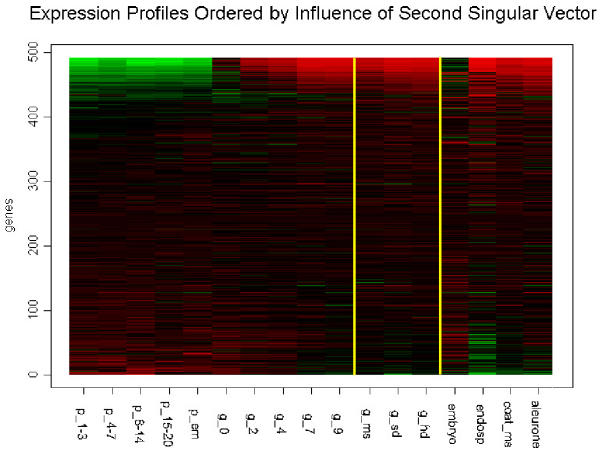
Singular value decomposition (SVD) of microarray data was investigated as a method to complement current techniques for gene expression pattern recognition. SVD's usefulness, in finding likely participants in grain filling, was measured by comparison with results obtained previously via clustering. 84 percent of these known grain-filling genes were re-identified after detailed SVD analysis. An additional set of 28 genes exhibited a stronger grain-filling pattern than those grain-filling genes that were unselected. They also had upstream sequence containing motifs over-represented among grain filling genes.
The pattern-based perspective that SVD provides complements to widely used clustering methods. The singular vectors provide information about patterns that exist in the data. Other aspects of the decomposition indicate the extent to which a gene exhibits a pattern similar to those provided by the singular vectors. Thus, once a set of interesting patterns has been identified, genes can be ranked by their relationship with said patterns.
为了鉴定参与养分分配的水稻基因,已开展微阵列实验以量化基因组规模的基因表达。参与养分分配,特别是籽粒灌浆的基因,将用于鉴定其他共调控基因以及DNA结合蛋白。正确鉴定用于进一步研究的初始诱饵基因集至关重要。层次聚类有助于将具有相似表达谱的基因分组,但随着数据复杂性和系统噪声的增加,其效用会降低。此外,其对基因的严格分类与我们认为某些基因表现出多方面、依赖上下文的调控这一观点不一致。
研究了微阵列数据的奇异值分解(SVD)作为补充当前基因表达模式识别技术的一种方法。通过与先前通过聚类获得的结果进行比较,衡量了SVD在寻找可能参与籽粒灌浆的基因方面的效用。经过详细的SVD分析后,重新鉴定出了这些已知籽粒灌浆基因中的84%。另外一组28个基因表现出比那些未被选中的籽粒灌浆基因更强的籽粒灌浆模式。它们还具有上游序列,其中包含在籽粒灌浆基因中过度富集的基序。
SVD提供的基于模式的视角补充了广泛使用的聚类方法。奇异向量提供了有关数据中存在的模式的信息。分解的其他方面表明基因表现出与奇异向量提供的模式相似的模式的程度。因此,一旦确定了一组有趣的模式,就可以根据基因与所述模式的关系对其进行排序。