Quevillon E, Silventoinen V, Pillai S, Harte N, Mulder N, Apweiler R, Lopez R
European Bioinformatics Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge CB10 1SD, UK.
Nucleic Acids Res. 2005 Jul 1;33(Web Server issue):W116-20. doi: 10.1093/nar/gki442.
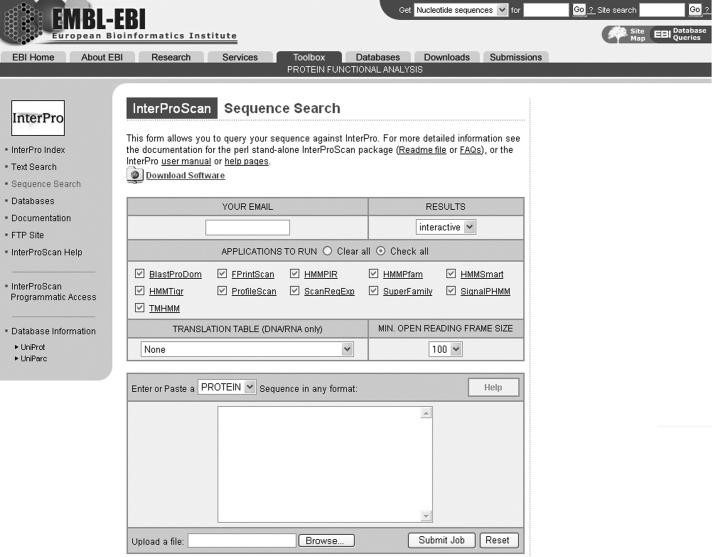
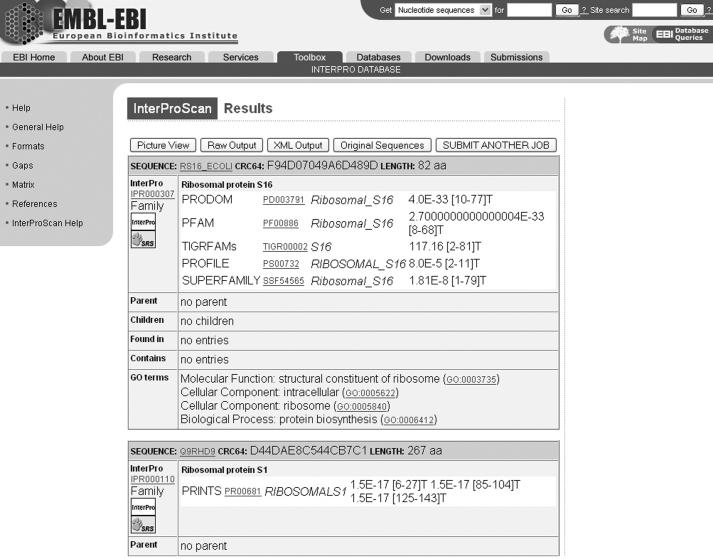
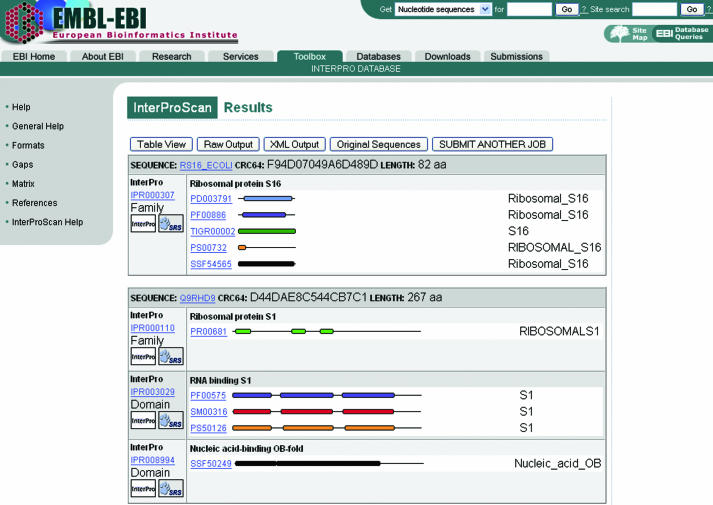
InterProScan [E. M. Zdobnov and R. Apweiler (2001) Bioinformatics, 17, 847-848] is a tool that combines different protein signature recognition methods from the InterPro [N. J. Mulder, R. Apweiler, T. K. Attwood, A. Bairoch, A. Bateman, D. Binns, P. Bradley, P. Bork, P. Bucher, L. Cerutti et al. (2005) Nucleic Acids Res., 33, D201-D205] consortium member databases into one resource. At the time of writing there are 10 distinct publicly available databases in the application. Protein as well as DNA sequences can be analysed. A web-based version is accessible for academic and commercial organizations from the EBI (http://www.ebi.ac.uk/InterProScan/). In addition, a standalone Perl version and a SOAP Web Service [J. Snell, D. Tidwell and P. Kulchenko (2001) Programming Web Services with SOAP, 1st edn. O'Reilly Publishers, Sebastopol, CA, http://www.w3.org/TR/soap/] are also available to the users. Various output formats are supported and include text tables, XML documents, as well as various graphs to help interpret the results.
InterProScan [E.M.兹多布诺夫和R.阿普维勒(2001年),《生物信息学》,第17卷,第847 - 848页]是一种将来自InterPro [N.J.马尔德、R.阿普维勒、T.K.阿特伍德、A.白罗什、A.贝特曼、D.宾斯、P.布拉德利、P.博尔克、P.布赫尔、L.塞鲁蒂等人(2005年),《核酸研究》,第33卷,D201 - D205页]联盟成员数据库的不同蛋白质特征识别方法整合为一个资源的工具。在撰写本文时,该应用中有10个不同的公开可用数据库。蛋白质序列和DNA序列均可进行分析。学术机构和商业组织可通过欧洲生物信息研究所的网站(http://www.ebi.ac.uk/InterProScan/)访问基于网络的版本。此外,用户还可以使用独立的Perl版本和SOAP网络服务 [J.斯内尔、D.蒂德韦尔和P.库尔琴科(2001年),《使用SOAP编写网络服务》,第1版。O'Reilly出版社,加利福尼亚州塞巴斯托波尔,http://www.w3.org/TR/soap/]。它支持多种输出格式,包括文本表格、XML文档以及各种有助于解释结果的图表。