Saebø Per Eystein, Andersen Sten Morten, Myrseth Jon, Laerdahl Jon K, Rognes Torbjørn
Centre for Molecular Biology and Neuroscience, Institute of Medical Microbiology, University of Oslo and Rikshospitalet-Radiumhospitalet, HF NO-0027 Oslo, Norway.
Nucleic Acids Res. 2005 Jul 1;33(Web Server issue):W535-9. doi: 10.1093/nar/gki423.
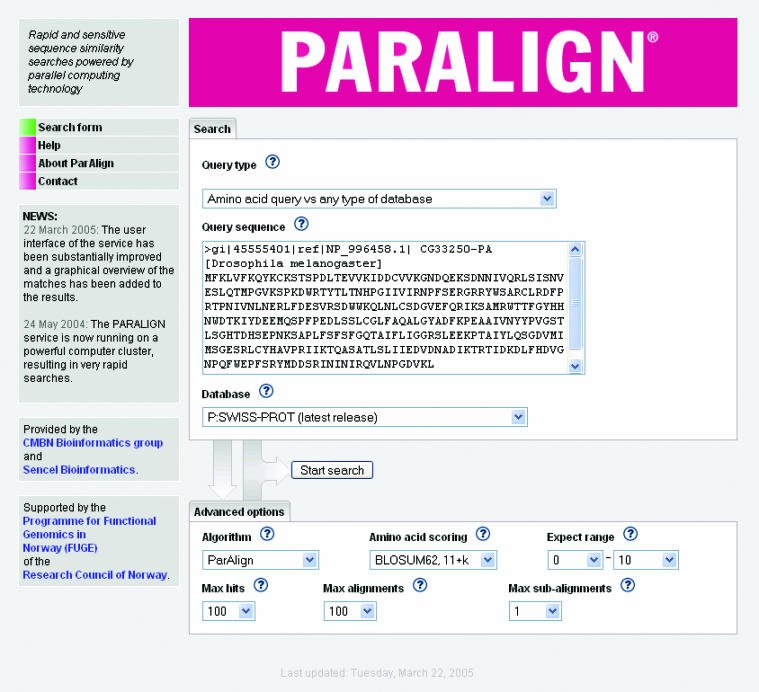
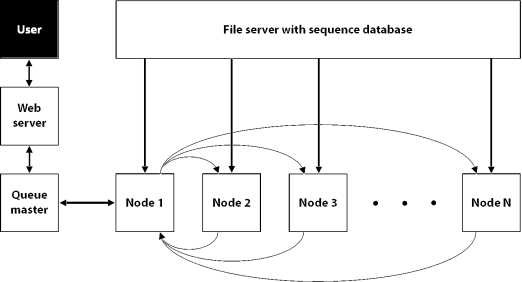
PARALIGN is a rapid and sensitive similarity search tool for the identification of distantly related sequences in both nucleotide and amino acid sequence databases. Two algorithms are implemented, accelerated Smith-Waterman and ParAlign. The ParAlign algorithm is similar to Smith-Waterman in sensitivity, while as quick as BLAST for protein searches. A form of parallel computing technology known as multimedia technology that is available in modern processors, but rarely used by other bioinformatics software, has been exploited to achieve the high speed. The software is also designed to run efficiently on computer clusters using the message-passing interface standard. A public search service powered by a large computer cluster has been set-up and is freely available at www.paralign.org, where the major public databases can be searched. The software can also be downloaded free of charge for academic use.
PARALIGN是一种快速且灵敏的相似性搜索工具,用于在核苷酸和氨基酸序列数据库中识别远缘相关序列。它实现了两种算法,即加速的史密斯-沃特曼算法和PARALIGN算法。PARALIGN算法在灵敏度上与史密斯-沃特曼算法相似,而在蛋白质搜索方面与BLAST一样快。利用了现代处理器中可用的一种称为多媒体技术的并行计算技术形式,其他生物信息学软件很少使用这种技术来实现高速运行。该软件还设计为使用消息传递接口标准在计算机集群上高效运行。已经建立了一个由大型计算机集群提供支持的公共搜索服务,可在www.paralign.org上免费使用,在该网站可以搜索主要的公共数据库。该软件也可免费下载供学术使用。