IRHS, Agrocampus-Ouest, INRAE, Université d'Angers, SFR 4207 QuaSaV, 49071 Beaucouzé, France.
Laboratoire de Mathématiques et Modélisation d'Evry (LaMME), Université d'Evry Val d'Essonne, Université Paris-Saclay, UMR CNRS 8071, ENSIIE, USC INRAE, 23 bvd de France, CEDEX, 91037 Evry Paris, France.
Genes (Basel). 2020 Sep 4;11(9):1046. doi: 10.3390/genes11091046.
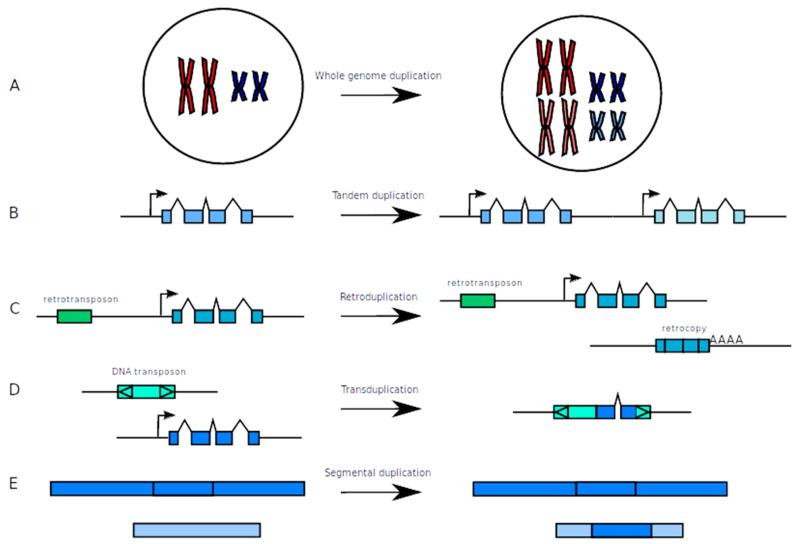
Gene duplication is an important evolutionary mechanism allowing to provide new genetic material and thus opportunities to acquire new gene functions for an organism, with major implications such as speciation events. Various processes are known to allow a gene to be duplicated and different models explain how duplicated genes can be maintained in genomes. Due to their particular importance, the identification of duplicated genes is essential when studying genome evolution but it can still be a challenge due to the various fates duplicated genes can encounter. In this review, we first describe the evolutionary processes allowing the formation of duplicated genes but also describe the various bioinformatic approaches that can be used to identify them in genome sequences. Indeed, these bioinformatic approaches differ according to the underlying duplication mechanism. Hence, understanding the specificity of the duplicated genes of interest is a great asset for tool selection and should be taken into account when exploring a biological question.
基因复制是一种重要的进化机制,它为生物体提供了新的遗传物质,从而为获得新的基因功能提供了机会,这对物种形成等重大事件有着重要的影响。人们已经知道了各种允许基因复制的过程,并且不同的模型解释了复制后的基因如何在基因组中得以保留。由于其特殊的重要性,在研究基因组进化时,识别复制基因是必不可少的,但由于复制基因可能会遇到各种命运,因此这仍然是一个挑战。在这篇综述中,我们首先描述了允许形成复制基因的进化过程,但也描述了可以用于在基因组序列中识别它们的各种生物信息学方法。事实上,这些生物信息学方法因潜在的复制机制而异。因此,了解感兴趣的复制基因的特异性是选择工具的重要资产,在探索生物学问题时应予以考虑。