Goovaerts Pierre
BioMedware, Inc., Ann Arbor, MI, USA.
Int J Health Geogr. 2006 Feb 9;5:7. doi: 10.1186/1476-072X-5-7.
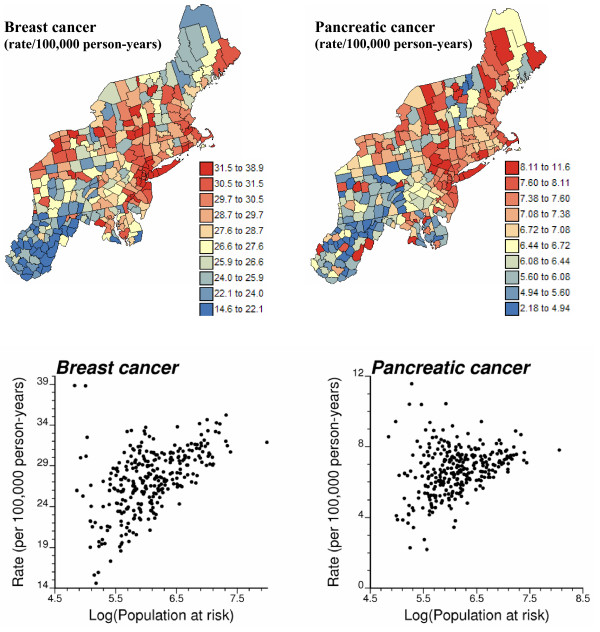
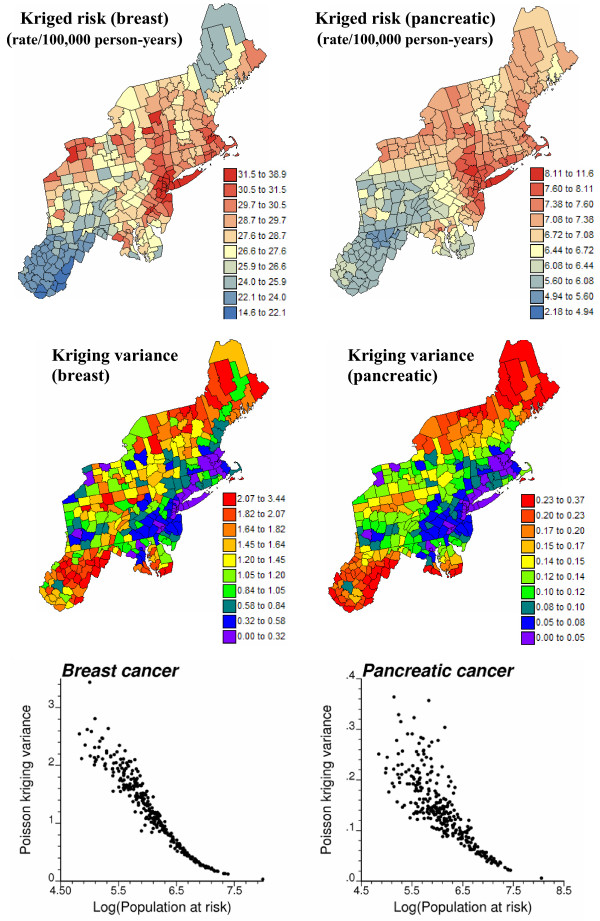
Smoothing methods have been developed to improve the reliability of risk cancer estimates from sparsely populated geographical entities. Filtering local details of the spatial variation of the risk leads however to the detection of larger clusters of low or high cancer risk while most spatial outliers are filtered out. Static maps of risk estimates and the associated prediction variance also fail to depict the uncertainty attached to the spatial distribution of risk values and does not allow its propagation through local cluster analysis. This paper presents a geostatistical methodology to generate multiple realizations of the spatial distribution of risk values. These maps are then fed into spatial operators, such as in local cluster analysis, allowing one to assess how risk spatial uncertainty translates into uncertainty about the location of spatial clusters and outliers. This novel approach is applied to age-adjusted breast and pancreatic cancer mortality rates recorded for white females in 295 US counties of the Northeast (1970-1994). A public-domain executable with example datasets is provided.
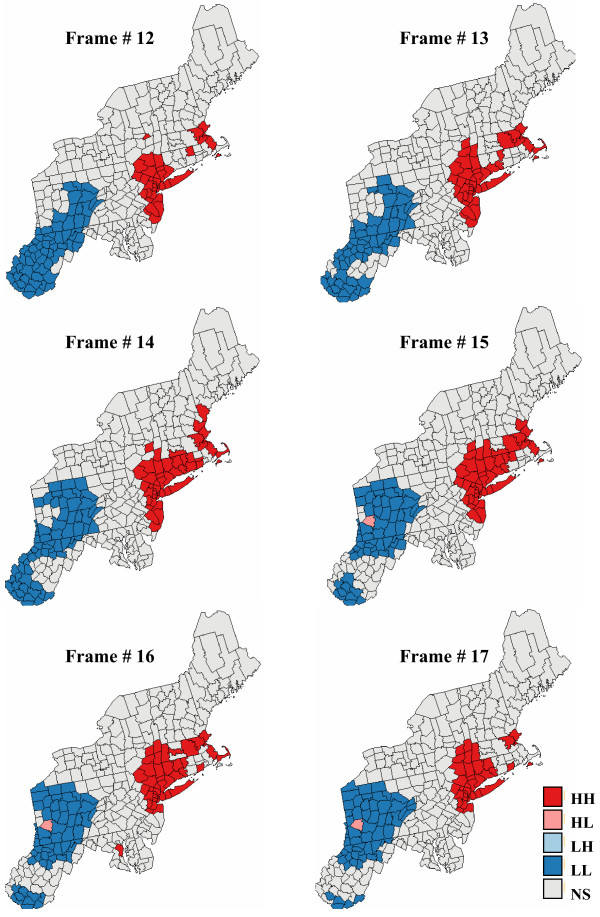
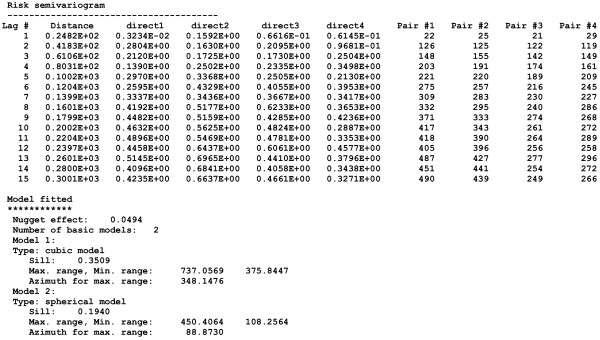
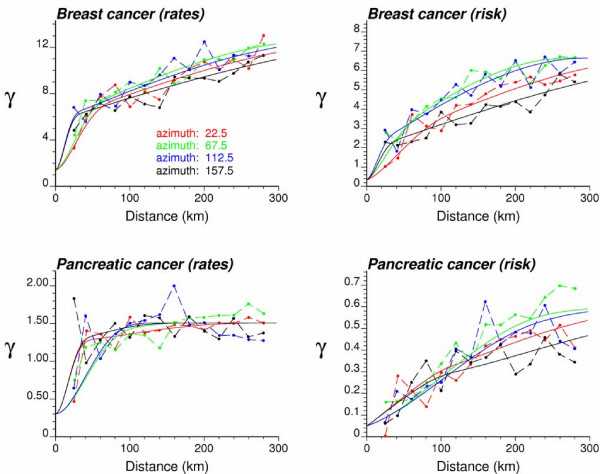
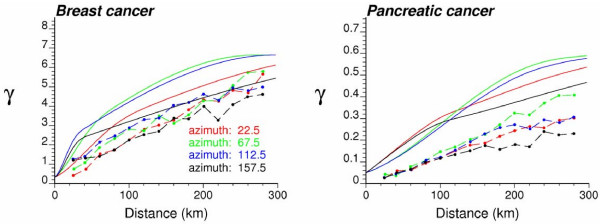
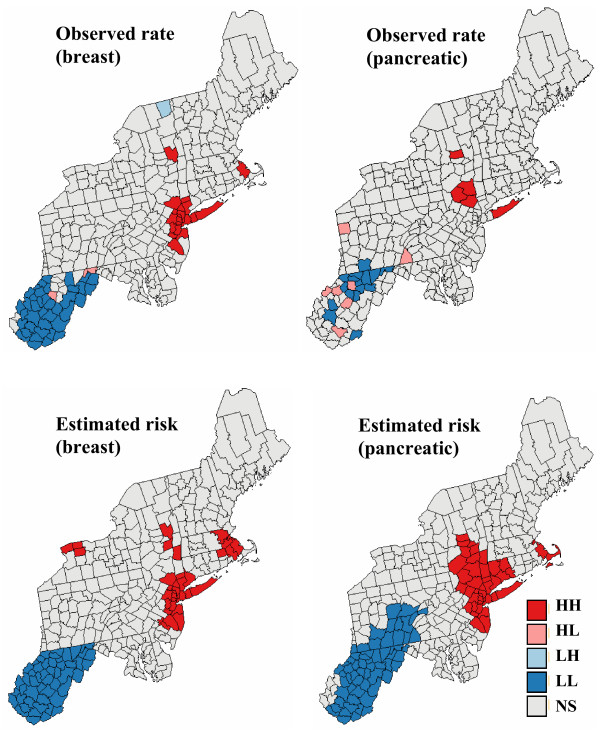
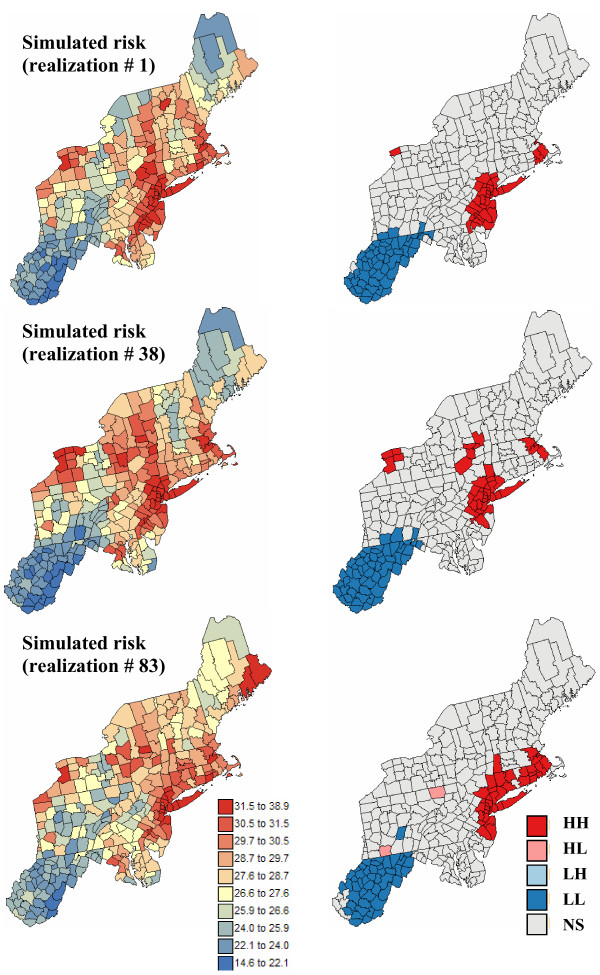
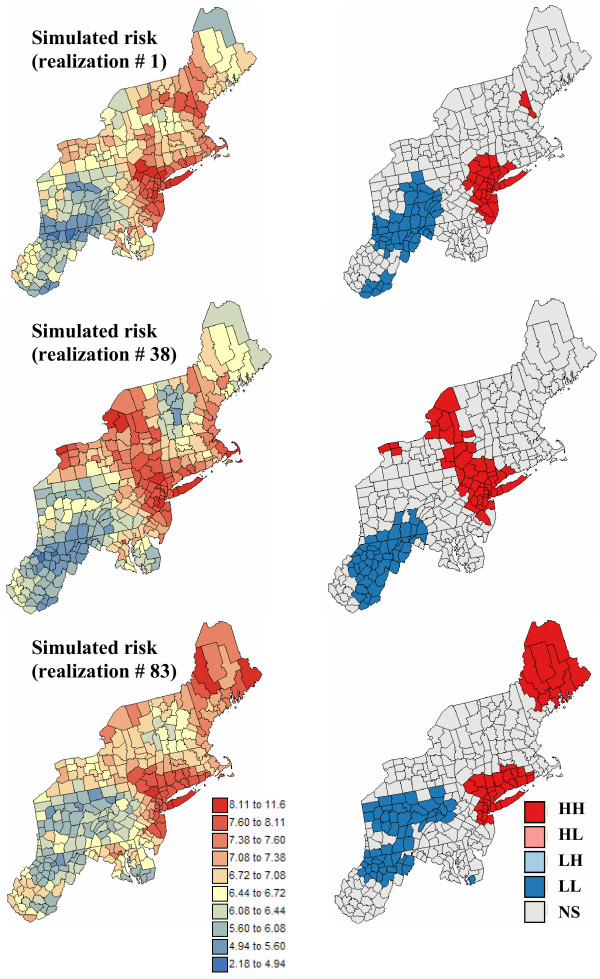
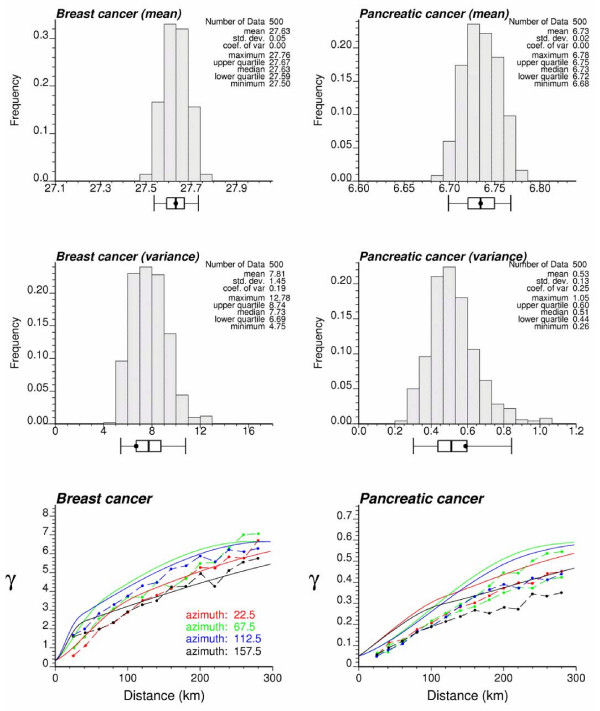
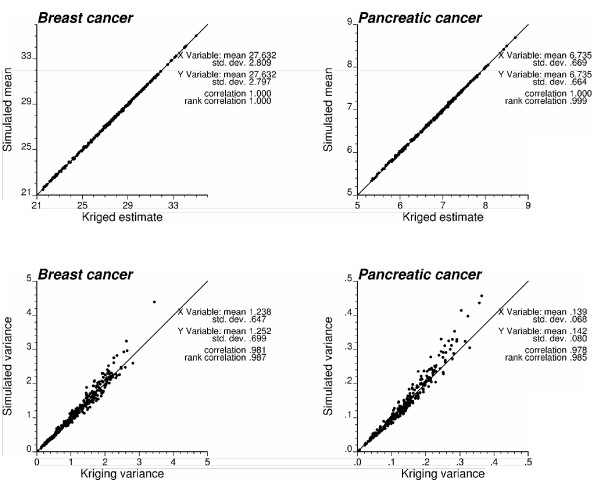
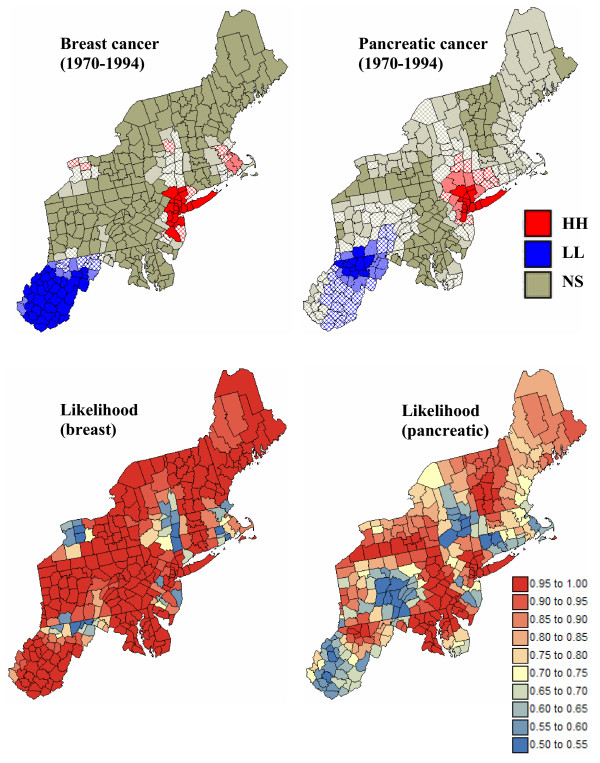
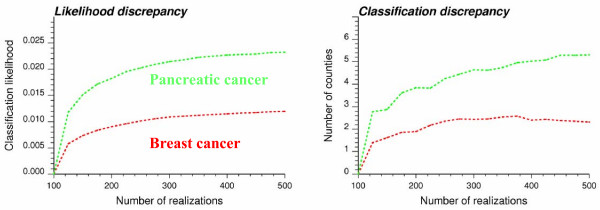
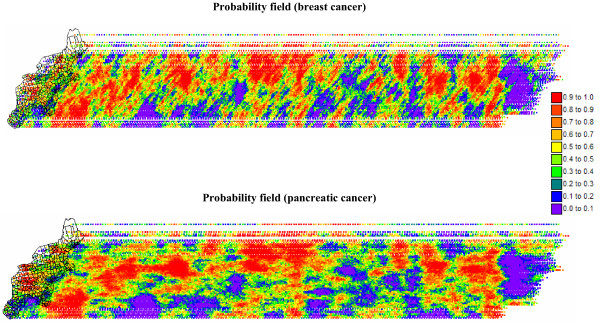
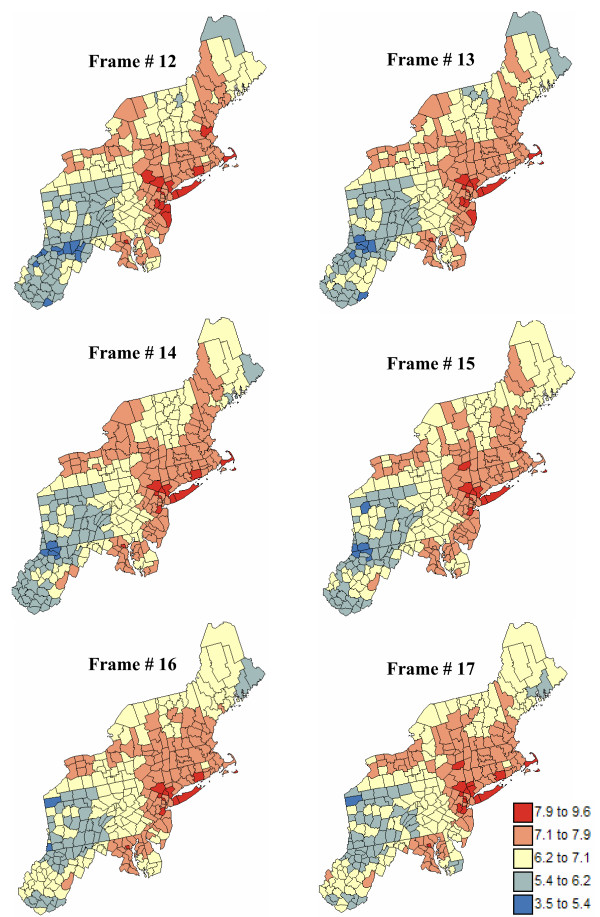
Geostatistical simulation generates risk maps that are more variable than the smooth risk map estimated by Poisson kriging and reproduce better the spatial pattern captured by the risk semivariogram model. Local cluster analysis of the set of simulated risk maps leads to a clear visualization of the lower reliability of the classification obtained for pancreatic cancer versus breast cancer: only a few counties in the large cluster of low risk detected in West Virginia and Southern Pennsylvania are significant over 90% of all simulations. On the other hand, the cluster of high breast cancer mortality in Niagara county, detected after application of Poisson kriging, appears on 60% of simulated risk maps. Sensitivity analysis shows that 500 realizations are needed to achieve a stable classification for pancreatic cancer, while convergence is reached for less than 300 realizations for breast cancer.
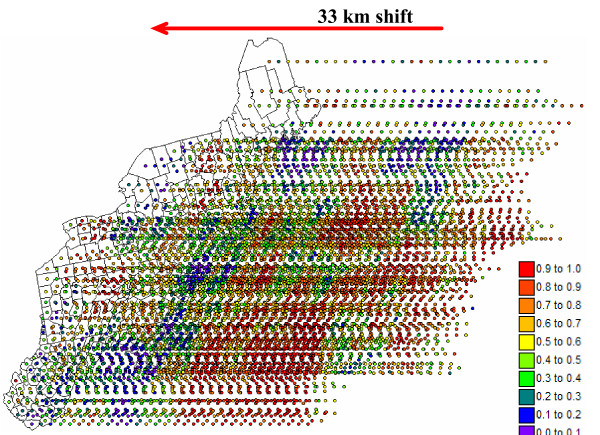
The approach presented in this paper enables researchers to generate a set of simulated risk maps that are more realistic than a single map of smoothed mortality rates and allow the propagation of cancer risk uncertainty through local cluster analysis. Coupled with visualization and querying capabilities of geographical information systems, animated display of realizations can highlight areas that depart consistently from the general behavior observed across the region, guiding further investigation and control activities.
已开发出平滑方法,以提高从人口稀少的地理区域得出的癌症风险估计的可靠性。然而,对风险空间变化的局部细节进行滤波会导致检测到更大的低风险或高风险集群,而大多数空间异常值会被滤除。风险估计的静态地图以及相关的预测方差也无法描绘风险值空间分布所附带的不确定性,并且不允许其通过局部聚类分析进行传播。本文提出了一种地质统计学方法,用于生成风险值空间分布的多个实现。然后将这些地图输入到空间算子中,例如在局部聚类分析中,从而使人们能够评估风险空间不确定性如何转化为空间集群和异常值位置的不确定性。这种新颖的方法应用于美国东北部295个县(1970 - 1994年)白人女性的年龄调整后乳腺癌和胰腺癌死亡率。提供了一个带有示例数据集的公共领域可执行文件。
地质统计学模拟生成的风险地图比通过泊松克里金法估计的平滑风险地图更具变异性,并且能更好地再现由风险半变异函数模型捕获的空间模式。对模拟风险地图集进行局部聚类分析,可以清晰地看到胰腺癌与乳腺癌分类可靠性的差异:在西弗吉尼亚州和宾夕法尼亚州南部检测到的低风险大集群中,只有少数几个县在所有模拟中超过90%是显著的。另一方面,在应用泊松克里金法后检测到的尼亚加拉县高乳腺癌死亡率集群出现在60%的模拟风险地图上。敏感性分析表明,胰腺癌需要500次实现才能达到稳定分类,而乳腺癌不到300次实现就可达到收敛。
本文提出的方法使研究人员能够生成一组比单一平滑死亡率地图更现实的模拟风险地图,并允许癌症风险不确定性通过局部聚类分析进行传播。结合地理信息系统的可视化和查询功能,实现的动态显示可以突出那些与整个区域观察到的一般行为持续不同的区域,指导进一步的调查和控制活动。