Chen Xianfeng, Laudeman Thomas W, Rushton Paul J, Spraggins Thomas A, Timko Michael P
Department of Microbiology, University of Virginia Health System, Charlottesville, VA 29908, USA.
BMC Bioinformatics. 2007 Apr 19;8:129. doi: 10.1186/1471-2105-8-129.
Cowpea [Vigna unguiculata (L.) Walp.] is one of the most important food and forage legumes in the semi-arid tropics because of its ability to tolerate drought and grow on poor soils. It is cultivated mostly by poor farmers in developing countries, with 80% of production taking place in the dry savannah of tropical West and Central Africa. Cowpea is largely an underexploited crop with relatively little genomic information available for use in applied plant breeding. The goal of the Cowpea Genomics Initiative (CGI), funded by the Kirkhouse Trust, a UK-based charitable organization, is to leverage modern molecular genetic tools for gene discovery and cowpea improvement. One aspect of the initiative is the sequencing of the gene-rich region of the cowpea genome (termed the genespace) recovered using methylation filtration technology and providing annotation and analysis of the sequence data.
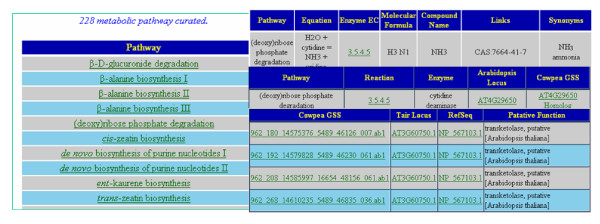
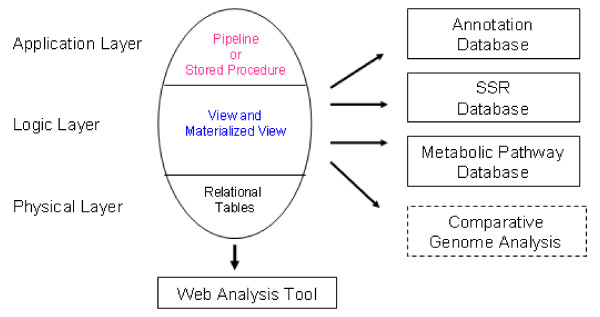
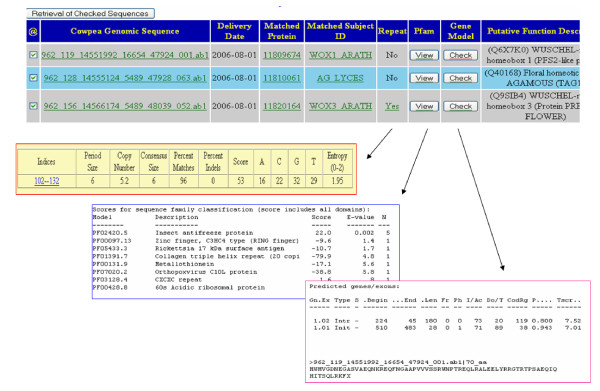
CGKB, Cowpea Genespace/Genomics Knowledge Base, is an annotation knowledge base developed under the CGI. The database is based on information derived from 298,848 cowpea genespace sequences (GSS) isolated by methylation filtering of genomic DNA. The CGKB consists of three knowledge bases: GSS annotation and comparative genomics knowledge base, GSS enzyme and metabolic pathway knowledge base, and GSS simple sequence repeats (SSRs) knowledge base for molecular marker discovery. A homology-based approach was applied for annotations of the GSS, mainly using BLASTX against four public FASTA formatted protein databases (NCBI GenBank Proteins, UniProtKB-Swiss-Prot, UniprotKB-PIR (Protein Information Resource), and UniProtKB-TrEMBL). Comparative genome analysis was done by BLASTX searches of the cowpea GSS against four plant proteomes from Arabidopsis thaliana, Oryza sativa, Medicago truncatula, and Populus trichocarpa. The possible exons and introns on each cowpea GSS were predicted using the HMM-based Genscan gene predication program and the potential domains on annotated GSS were analyzed using the HMMER package against the Pfam database. The annotated GSS were also assigned with Gene Ontology annotation terms and integrated with 228 curated plant metabolic pathways from the Arabidopsis Information Resource (TAIR) knowledge base. The UniProtKB-Swiss-Prot ENZYME database was used to assign putative enzymatic function to each GSS. Each GSS was also analyzed with the Tandem Repeat Finder (TRF) program in order to identify potential SSRs for molecular marker discovery. The raw sequence data, processed annotation, and SSR results were stored in relational tables designed in key-value pair fashion using a PostgreSQL relational database management system. The biological knowledge derived from the sequence data and processed results are represented as views or materialized views in the relational database management system. All materialized views are indexed for quick data access and retrieval. Data processing and analysis pipelines were implemented using the Perl programming language. The web interface was implemented in JavaScript and Perl CGI running on an Apache web server. The CPU intensive data processing and analysis pipelines were run on a computer cluster of more than 30 dual-processor Apple XServes. A job management system called Vela was created as a robust way to submit large numbers of jobs to the Portable Batch System (PBS).
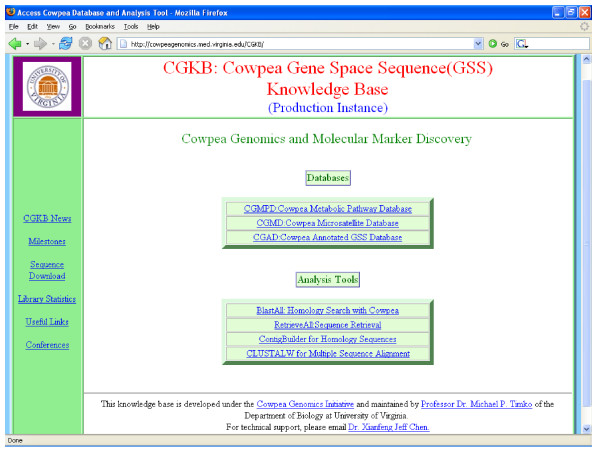
CGKB is an integrated and annotated resource for cowpea GSS with features of homology-based and HMM-based annotations, enzyme and pathway annotations, GO term annotation, toolkits, and a large number of other facilities to perform complex queries. The cowpea GSS, chloroplast sequences, mitochondrial sequences, retroelements, and SSR sequences are available as FASTA formatted files and downloadable at CGKB. This database and web interface are publicly accessible at http://cowpeagenomics.med.virginia.edu/CGKB/.
豇豆[Vigna unguiculata (L.) Walp.]是半干旱热带地区最重要的食用豆类和饲料豆类之一,因其具有耐旱能力且能在贫瘠土壤上生长。它主要由发展中国家的贫困农民种植,80%的产量来自热带西非和中非的干燥稀树草原。豇豆在很大程度上是一种未得到充分开发的作物,可用于应用植物育种的基因组信息相对较少。由英国慈善组织柯克豪斯信托基金资助的豇豆基因组计划(CGI)的目标是利用现代分子遗传工具进行基因发现和豇豆改良。该计划的一个方面是对使用甲基化过滤技术回收的豇豆基因组富含基因区域(称为基因空间)进行测序,并对序列数据进行注释和分析。
CGKB,即豇豆基因空间/基因组知识库,是在CGI项目下开发的注释知识库。该数据库基于通过对基因组DNA进行甲基化过滤分离得到的298,848条豇豆基因空间序列(GSS)的信息。CGKB由三个知识库组成:GSS注释和比较基因组学知识库、GSS酶和代谢途径知识库以及用于分子标记发现的GSS简单序列重复(SSR)知识库。对GSS的注释采用基于同源性的方法,主要使用BLASTX比对四个公共的FASTA格式蛋白质数据库(NCBI GenBank蛋白质数据库、UniProtKB - Swiss - Prot、UniprotKB - PIR(蛋白质信息资源库)和UniProtKB - TrEMBL)。通过将豇豆GSS与来自拟南芥、水稻、蒺藜苜蓿和毛果杨的四个植物蛋白质组进行BLASTX搜索来进行比较基因组分析。使用基于隐马尔可夫模型(HMM)的Genscan基因预测程序预测每个豇豆GSS上可能的外显子和内含子,并使用HMMER软件包针对Pfam数据库分析注释GSS上的潜在结构域。注释后的GSS还被赋予了基因本体注释术语,并与来自拟南芥信息资源库(TAIR)知识库的228条经过整理的植物代谢途径进行整合。使用UniProtKB - Swiss - Prot ENZYME数据库为每个GSS赋予推定的酶功能。还使用串联重复序列查找器(TRF)程序对每个GSS进行分析,以识别用于分子标记发现的潜在SSR。原始序列数据、处理后的注释和SSR结果存储在使用PostgreSQL关系数据库管理系统以键值对方式设计的关系表中。从序列数据和处理结果中获得的生物学知识在关系数据库管理系统中表示为视图或物化视图。所有物化视图都建立了索引以便快速数据访问和检索。数据处理和分析管道使用Perl编程语言实现。Web界面使用运行在Apache Web服务器上的JavaScript和Perl CGI实现。CPU密集型数据处理和分析管道在由30多个双处理器苹果XServe组成的计算机集群上运行。创建了一个名为Vela的作业管理系统,作为向便携式批处理系统(PBS)提交大量作业的可靠方式。
CGKB是一个针对豇豆GSS的集成且经过注释的资源,具有基于同源性和基于HMM的注释、酶和途径注释、GO术语注释、工具包以及大量用于执行复杂查询的其他功能。豇豆GSS、叶绿体序列线粒体序列、反转录元件和SSR序列以FASTA格式文件提供,可在CGKB上下载。该数据库和Web界面可通过http://cowpeagenomics.med.virginia.edu/CGKB/公开访问。