Akao Takeshi, Sano Motoaki, Yamada Osamu, Akeno Terumi, Fujii Kaoru, Goto Kuniyasu, Ohashi-Kunihiro Sumiko, Takase Kumiko, Yasukawa-Watanabe Makoto, Yamaguchi Kanako, Kurihara Yoko, Maruyama Jun-ichi, Juvvadi Praveen Rao, Tanaka Akimitsu, Hata Yoji, Koyama Yasuji, Yamaguchi Shotaro, Kitamoto Noriyuki, Gomi Katsuya, Abe Keietsu, Takeuchi Michio, Kobayashi Tetsuo, Horiuchi Hiroyuki, Kitamoto Katsuhiko, Kashiwagi Yutaka, Machida Masayuki, Akita Osamu
National Research Institute of Brewing, 3-7-1 Kagamiyama, Higashi-Hiroshima, Hiroshima 739-0046, Japan.
DNA Res. 2007 Apr;14(2):47-57. doi: 10.1093/dnares/dsm008. Epub 2007 May 31.
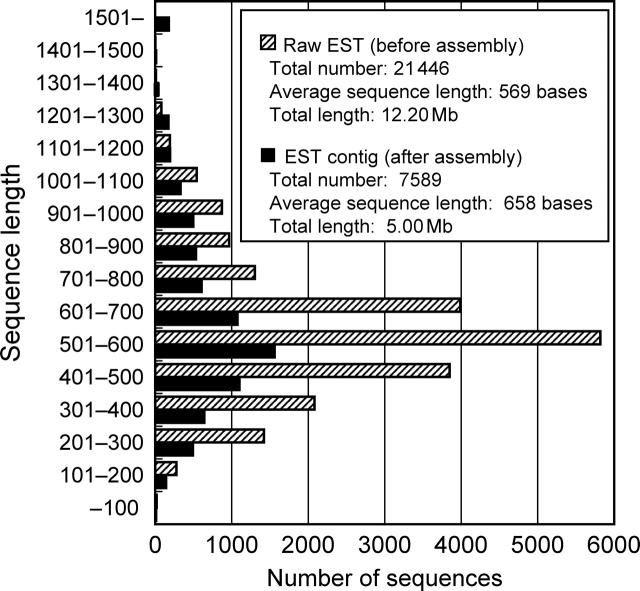
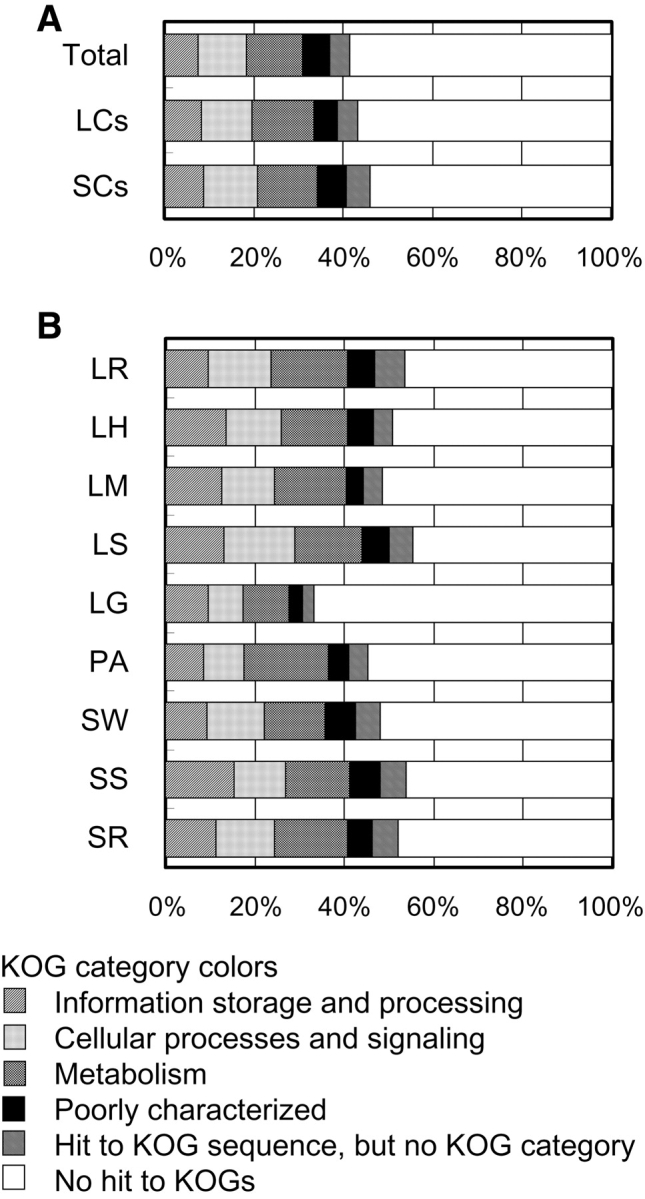
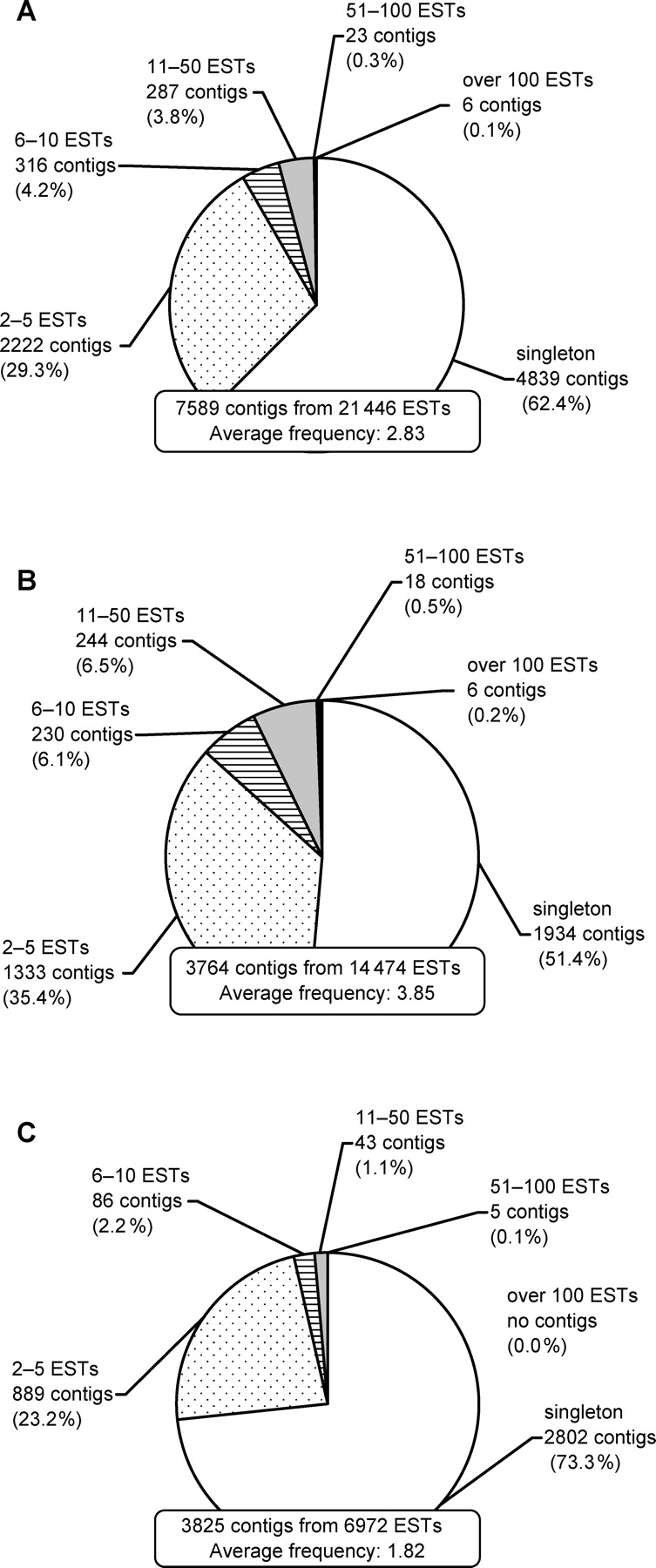
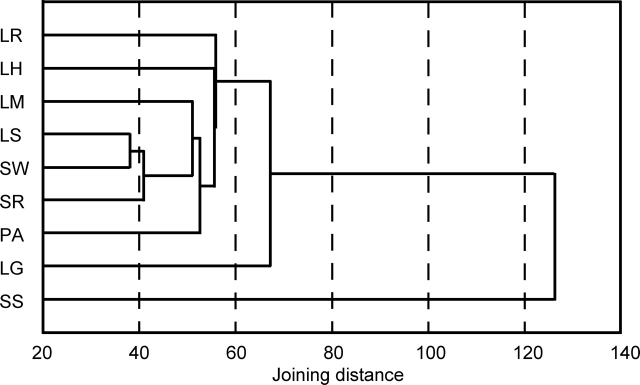
We performed random sequencing of cDNAs from nine biologically or industrially important cultures of the industrially valuable fungus Aspergillus oryzae to obtain expressed sequence tags (ESTs). Consequently, 21 446 raw ESTs were accumulated and subsequently assembled to 7589 non-redundant consensus sequences (contigs). Among all contigs, 5491 (72.4%) were derived from only a particular culture. These included 4735 (62.4%) singletons, i.e. lone ESTs overlapping with no others. These data showed that consideration of culture grown under various conditions as cDNA sources enabled efficient collection of ESTs. BLAST searches against the public databases showed that 2953 (38.9%) of the EST contigs showed significant similarities to deposited sequences with known functions, 793 (10.5%) were similar to hypothetical proteins, and the remaining 3843 (50.6%) showed no significant similarity to sequences in the databases. Culture-specific contigs were extracted on the basis of the EST frequency normalized by the total number for each culture condition. In addition, contig sequences were compared with sequence sets in eukaryotic orthologous groups (KOGs), and classified into the KOG functional categories.
我们对具有工业价值的米曲霉的9种具有生物学或工业重要性的培养物的cDNA进行了随机测序,以获得表达序列标签(EST)。结果,积累了21446条原始EST,并随后组装成7589条非冗余共有序列(重叠群)。在所有重叠群中,5491条(72.4%)仅来自特定培养物。其中包括4735条(62.4%)单拷贝序列,即不与其他序列重叠的单个EST。这些数据表明,将在各种条件下培养的培养物作为cDNA来源能够有效地收集EST。对公共数据库进行的BLAST搜索显示,2953条(38.9%)EST重叠群与具有已知功能的已存序列显示出显著相似性,793条(10.5%)与假定蛋白质相似,其余3843条(50.6%)与数据库中的序列无显著相似性。基于每种培养条件下总数标准化后的EST频率提取特定培养物重叠群。此外,将重叠群序列与真核直系同源组(KOG)中的序列集进行比较,并分类到KOG功能类别中。