Mahdavi Mahmoud A, Lin Yen-Han
Department of Chemical Engineering, University of Saskatchewan, Saskatoon, SK, Canada.
BMC Bioinformatics. 2007 Jul 23;8:262. doi: 10.1186/1471-2105-8-262.
Many crucial cellular operations such as metabolism, signalling, and regulations are based on protein-protein interactions. However, the lack of robust protein-protein interaction information is a challenge. One reason for the lack of solid protein-protein interaction information is poor agreement between experimental findings and computational sets that, in turn, comes from huge false positive predictions in computational approaches. Reduction of false positive predictions and enhancing true positive fraction of computationally predicted protein-protein interaction datasets based on highly confident experimental results has not been adequately investigated.
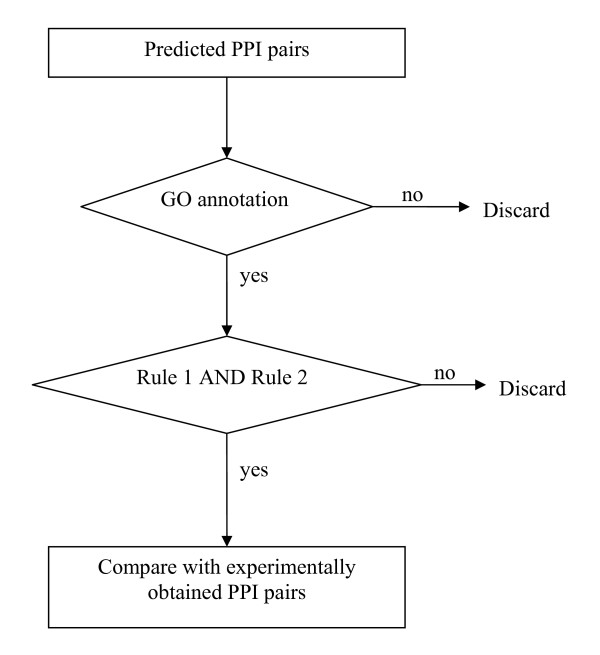
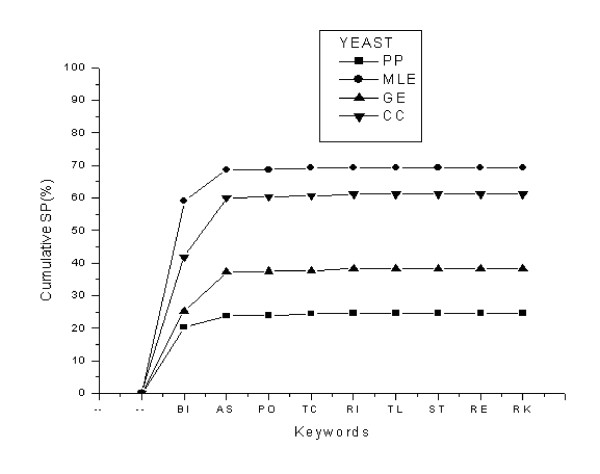
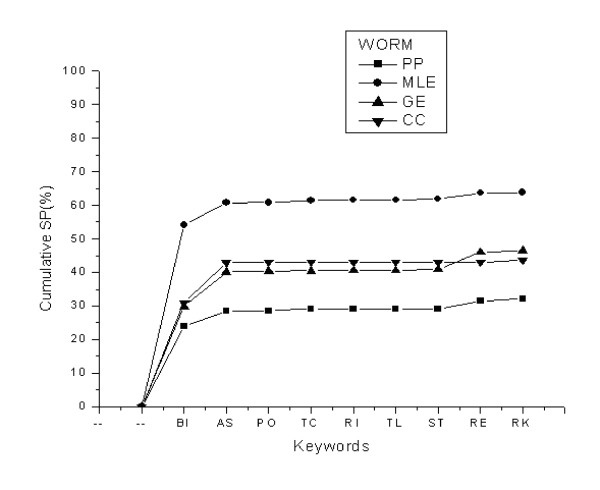
Gene Ontology (GO) annotations were used to reduce false positive protein-protein interactions (PPI) pairs resulting from computational predictions. Using experimentally obtained PPI pairs as a training dataset, eight top-ranking keywords were extracted from GO molecular function annotations. The sensitivity of these keywords is 64.21% in the yeast experimental dataset and 80.83% in the worm experimental dataset. The specificities, a measure of recovery power, of these keywords applied to four predicted PPI datasets for each studied organisms, are 48.32% and 46.49% (by average of four datasets) in yeast and worm, respectively. Based on eight top-ranking keywords and co-localization of interacting proteins a set of two knowledge rules were deduced and applied to remove false positive protein pairs. The 'strength', a measure of improvement provided by the rules was defined based on the signal-to-noise ratio and implemented to measure the applicability of knowledge rules applying to the predicted PPI datasets. Depending on the employed PPI-predicting methods, the strength varies between two and ten-fold of randomly removing protein pairs from the datasets.
Gene Ontology annotations along with the deduced knowledge rules could be implemented to partially remove false predicted PPI pairs. Removal of false positives from predicted datasets increases the true positive fractions of the datasets and improves the robustness of predicted pairs as compared to random protein pairing, and eventually results in better overlap with experimental results.
许多关键的细胞操作,如新陈代谢、信号传导和调控,都基于蛋白质-蛋白质相互作用。然而,缺乏可靠的蛋白质-蛋白质相互作用信息是一个挑战。缺乏可靠蛋白质-蛋白质相互作用信息的一个原因是实验结果与计算集之间的一致性较差,而这又源于计算方法中大量的假阳性预测。基于高度可信的实验结果减少假阳性预测并提高计算预测的蛋白质-蛋白质相互作用数据集的真阳性率尚未得到充分研究。
利用基因本体论(GO)注释来减少计算预测产生的假阳性蛋白质-蛋白质相互作用(PPI)对。以实验获得的PPI对作为训练数据集,从GO分子功能注释中提取了八个排名靠前的关键词。这些关键词在酵母实验数据集中的敏感性为64.21%,在蠕虫实验数据集中为80.83%。将这些关键词应用于每个研究生物体的四个预测PPI数据集时,其特异性(一种恢复能力的度量)在酵母和蠕虫中分别为48.32%和46.49%(四个数据集的平均值)。基于八个排名靠前的关键词和相互作用蛋白质的共定位,推导并应用了一组两条知识规则来去除假阳性蛋白质对。基于信噪比定义了规则提供的改进度量“强度”,并用于衡量知识规则对预测PPI数据集的适用性。根据所采用的PPI预测方法,强度在从数据集中随机去除蛋白质对的两到十倍之间变化。
基因本体论注释以及推导的知识规则可用于部分去除错误预测的PPI对。从预测数据集中去除假阳性会增加数据集的真阳性率,并与随机蛋白质配对相比提高预测对的稳健性,最终导致与实验结果有更好的重叠。