Department of Genetics, Stanford University, Stanford, CA 94305-5120, USA.
Database (Oxford). 2012 Mar 20;2012:bas001. doi: 10.1093/database/bas001. Print 2012.
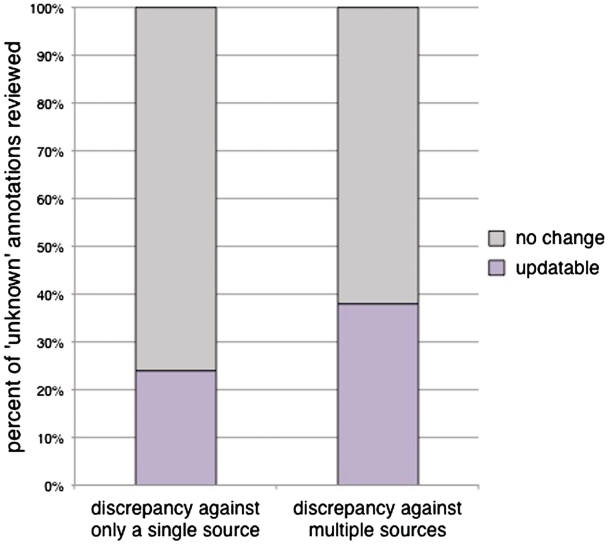
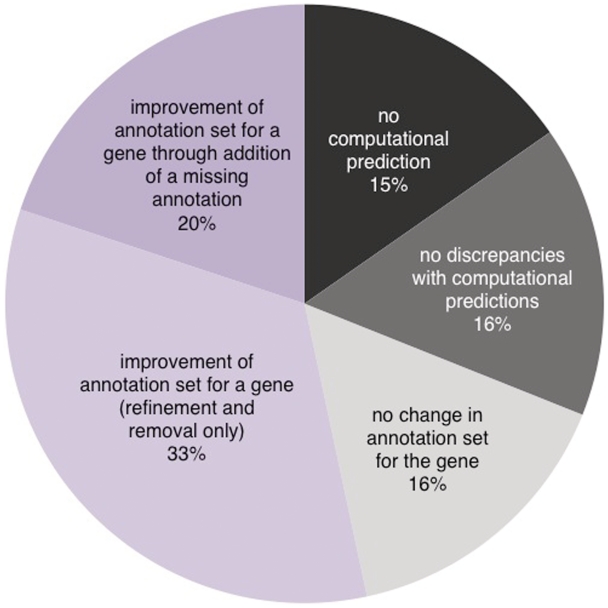
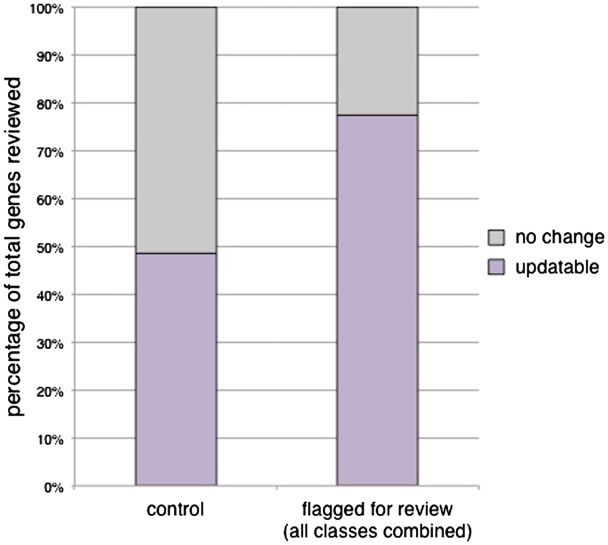
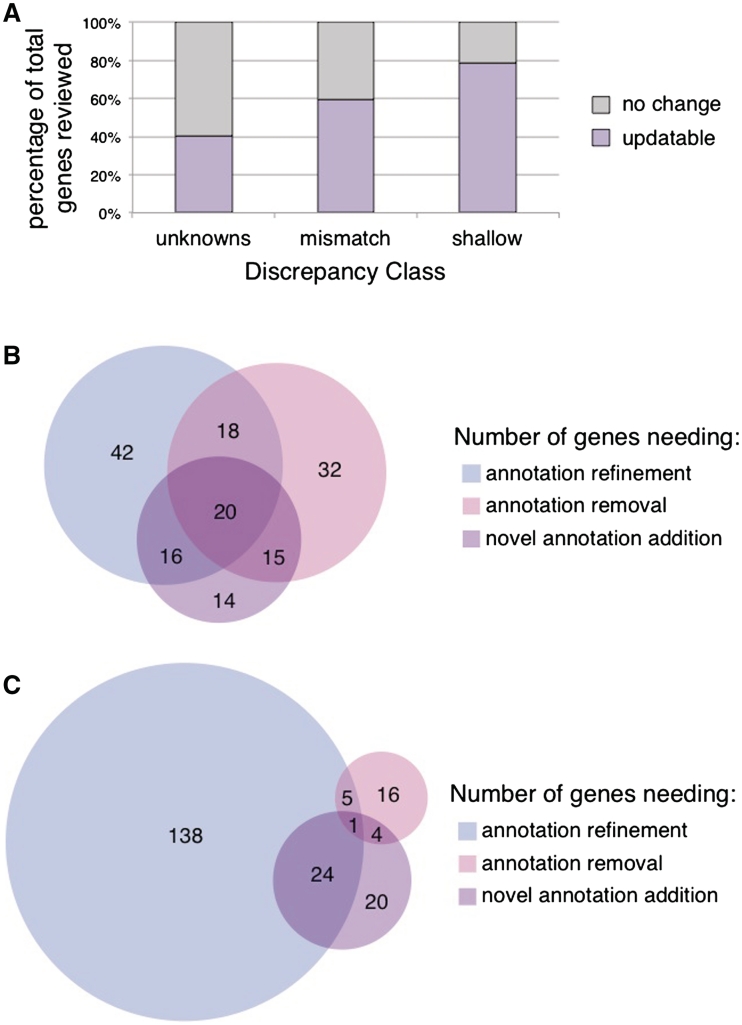
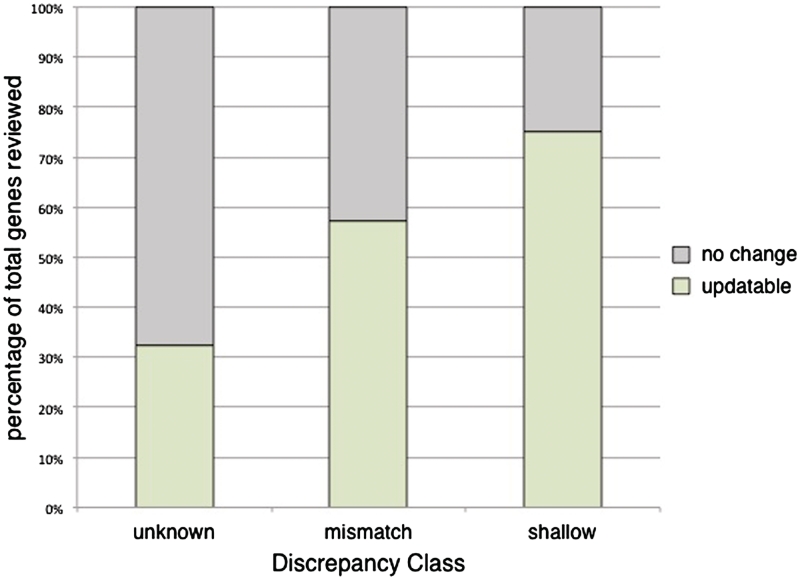
The set of annotations at the Saccharomyces Genome Database (SGD) that classifies the cellular function of S. cerevisiae gene products using Gene Ontology (GO) terms has become an important resource for facilitating experimental analysis. In addition to capturing and summarizing experimental results, the structured nature of GO annotations allows for functional comparison across organisms as well as propagation of functional predictions between related gene products. Due to their relevance to many areas of research, ensuring the accuracy and quality of these annotations is a priority at SGD. GO annotations are assigned either manually, by biocurators extracting experimental evidence from the scientific literature, or through automated methods that leverage computational algorithms to predict functional information. Here, we discuss the relationship between literature-based and computationally predicted GO annotations in SGD and extend a strategy whereby comparison of these two types of annotation identifies genes whose annotations need review. Our method, CvManGO (Computational versus Manual GO annotations), pairs literature-based GO annotations with computational GO predictions and evaluates the relationship of the two terms within GO, looking for instances of discrepancy. We found that this method will identify genes that require annotation updates, taking an important step towards finding ways to prioritize literature review. Additionally, we explored factors that may influence the effectiveness of CvManGO in identifying relevant gene targets to find in particular those genes that are missing literature-supported annotations, but our survey found that there are no immediately identifiable criteria by which one could enrich for these under-annotated genes. Finally, we discuss possible ways to improve this strategy, and the applicability of this method to other projects that use the GO for curation. DATABASE URL: http://www.yeastgenome.org.
在酿酒酵母基因组数据库 (SGD) 中,使用基因本体论 (GO) 术语对酿酒酵母基因产物的细胞功能进行分类的注释集已成为促进实验分析的重要资源。GO 注释不仅捕获和总结了实验结果,其结构化的性质还允许在生物体之间进行功能比较,并在相关基因产物之间传播功能预测。由于它们与许多研究领域相关,因此确保这些注释的准确性和质量是 SGD 的首要任务。GO 注释要么是手动分配的,由生物注释员从科学文献中提取实验证据,要么是通过利用计算算法来预测功能信息的自动化方法分配的。在这里,我们讨论了 SGD 中基于文献的和基于计算的 GO 注释之间的关系,并扩展了一种策略,即通过比较这两种类型的注释来确定需要审查注释的基因。我们的方法 CvManGO(基于文献的 GO 注释与基于计算的 GO 预测)将基于文献的 GO 注释与基于计算的 GO 预测配对,并在 GO 内评估这两个术语的关系,寻找不一致的实例。我们发现,这种方法将能够识别需要注释更新的基因,朝着寻找优先审查文献的方法迈出了重要一步。此外,我们还探讨了可能影响 CvManGO 识别相关基因靶标有效性的因素,特别是那些缺少文献支持注释的基因,但我们的调查发现,目前没有可以通过这些标准来丰富这些未注释基因的方法。最后,我们讨论了改进这种策略的可能方法,以及该方法在其他使用 GO 进行注释的项目中的适用性。数据库 URL:http://www.yeastgenome.org。