Shah Nigam H, Rubin Daniel L, Espinosa Inigo, Montgomery Kelli, Musen Mark A
Stanford Medical Informatics, School of Medicine, Stanford University, Stanford, CA 94305, USA.
BMC Bioinformatics. 2007 Aug 8;8:296. doi: 10.1186/1471-2105-8-296.
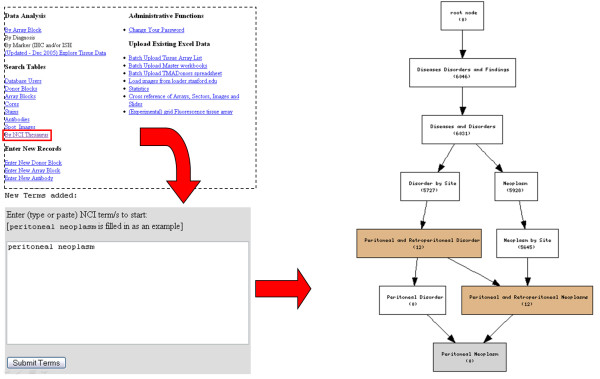
The Stanford Tissue Microarray Database (TMAD) is a repository of data serving a consortium of pathologists and biomedical researchers. The tissue samples in TMAD are annotated with multiple free-text fields, specifying the pathological diagnoses for each sample. These text annotations are not structured according to any ontology, making future integration of this resource with other biological and clinical data difficult.
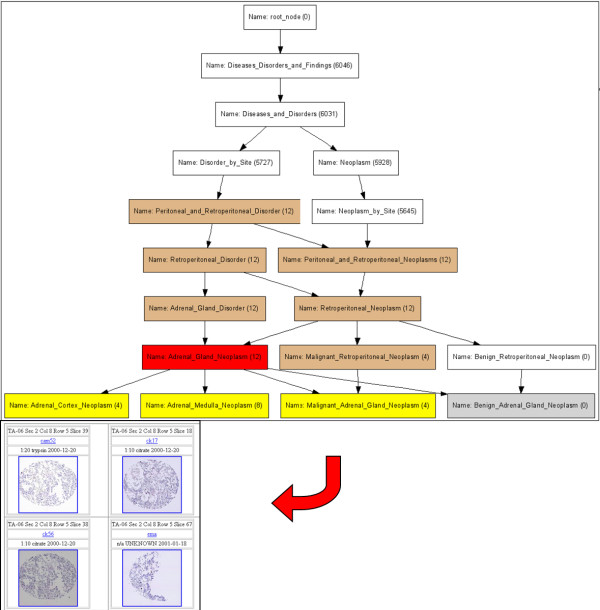
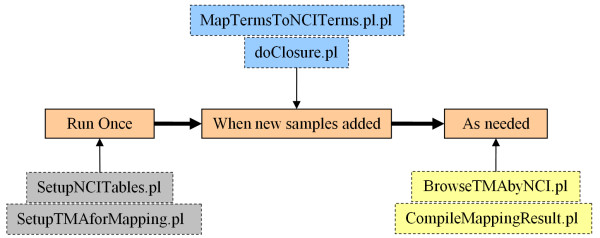
We developed methods to map these annotations to the NCI thesaurus. Using the NCI-T we can effectively represent annotations for about 86% of the samples. We demonstrate how this mapping enables ontology driven integration and querying of tissue microarray data. We have deployed the mapping and ontology driven querying tools at the TMAD site for general use.
We have demonstrated that we can effectively map the diagnosis-related terms describing a sample in TMAD to the NCI-T. The NCI thesaurus terms have a wide coverage and provide terms for about 86% of the samples. In our opinion the NCI thesaurus can facilitate integration of this resource with other biological data.
斯坦福组织微阵列数据库(TMAD)是一个为病理学家和生物医学研究人员联盟提供服务的数据储存库。TMAD中的组织样本用多个自由文本字段进行注释,指定每个样本的病理诊断。这些文本注释没有按照任何本体进行结构化,使得该资源未来与其他生物和临床数据的整合变得困难。
我们开发了将这些注释映射到美国国立癌症研究所(NCI)叙词表的方法。使用NCI-T,我们可以有效地表示约86%样本的注释。我们展示了这种映射如何实现本体驱动的组织微阵列数据整合和查询。我们已在TMAD网站部署了映射和本体驱动的查询工具以供通用。
我们已经证明,我们可以有效地将描述TMAD中样本的诊断相关术语映射到NCI-T。NCI叙词表术语具有广泛的覆盖范围,为约86%的样本提供了术语。我们认为,NCI叙词表可以促进该资源与其他生物数据的整合。