Piwowar Heather, Chapman Wendy
University of Pittsburgh.
J Biomed Discov Collab. 2010 Mar 28;5:7-20.
The ability to locate publicly available gene expression microarray datasets effectively and efficiently facilitates the reuse of these potentially valuable resources. Centralized biomedical databases allow users to query dataset metadata descriptions, but these annotations are often too sparse and diverse to allow complex and accurate queries. In this study we examined the ability of PubMed article identifiers to locate publicly available gene expression microarray datasets, and investigated whether the retrieved datasets were representative of publicly available datasets found through statements of data sharing in the associated research articles.
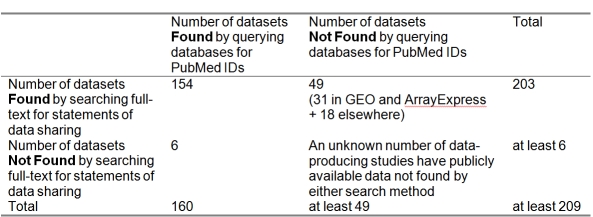
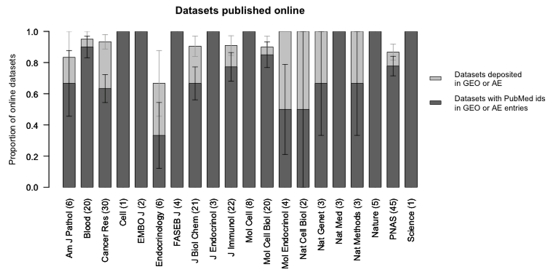
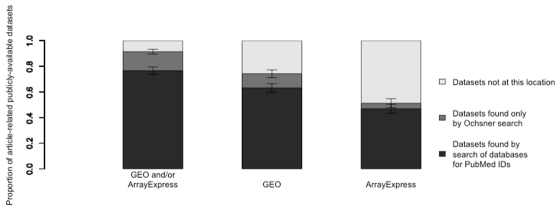
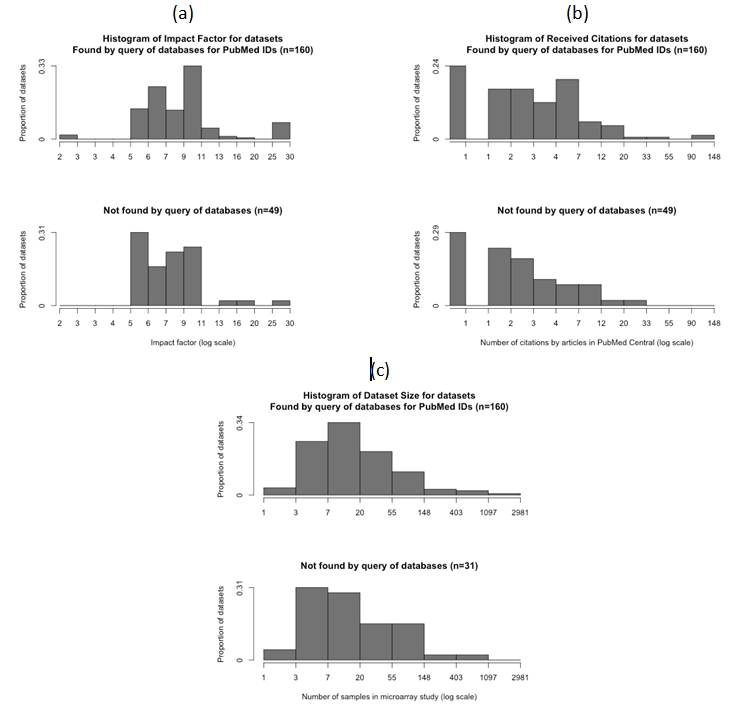
In a recent article, Ochsner and colleagues identified 397 studies that had generated gene expression microarray data. Their search of the full text of each publication for statements of data sharing revealed 203 publicly available datasets, including 179 in the Gene Expression Omnibus (GEO) or ArrayExpress databases. Our scripted search of GEO and ArrayExpress for PubMed identifiers of the same 397 studies returned 160 datasets, including six not found by the original search for data sharing statements. As a proportion of datasets found by either method, the search for data sharing statements identified 91.4% of the 209 publicly available datasets, compared to only 76.6% found by our search carried out using PubMed identifiers. Searching GEO or ArrayExpress alone retrieved 63.2% and 46.9% of all available datasets, respectively. There was no difference in the type of datasets found by PubMed identifier searches in terms of research theme or the technology used. However, the studies identified were more likely to have larger sample sizes, were more frequently cited, and published in higher impact journals.
Searching database entries using PubMed identifiers can identify the majority of publicly available datasets, but caution is required when this method is used to collect data for policy evaluation since studies in low impact journals are disproportionately excluded. We urge authors of all datasets to complete the citation fields for their dataset submissions once publication details are known, thereby ensuring their work has maximum visibility and can contribute to subsequent studies.
有效且高效地定位公开可用的基因表达微阵列数据集的能力有助于这些潜在有价值资源的重复利用。集中式生物医学数据库允许用户查询数据集的元数据描述,但这些注释往往过于稀疏和多样,无法进行复杂而准确的查询。在本研究中,我们检验了PubMed文章标识符定位公开可用基因表达微阵列数据集的能力,并调查了检索到的数据集是否代表通过相关研究文章中的数据共享声明找到的公开可用数据集。
在最近的一篇文章中,奥克斯纳及其同事识别出397项产生了基因表达微阵列数据的研究。他们在每篇出版物的全文中搜索数据共享声明,发现了203个公开可用的数据集,其中包括基因表达综合数据库(GEO)或ArrayExpress数据库中的179个。我们使用脚本在GEO和ArrayExpress中搜索这397项相同研究的PubMed标识符,返回了160个数据集,其中包括原始数据共享声明搜索未找到的6个。就两种方法找到的数据集比例而言,数据共享声明搜索识别出了209个公开可用数据集中的91.4%,相比之下,我们使用PubMed标识符进行的搜索仅找到76.6%。单独搜索GEO或ArrayExpress分别检索到所有可用数据集的63.2%和46.9%。通过PubMed标识符搜索找到的数据集类型在研究主题或所用技术方面没有差异。然而,识别出的研究更有可能具有更大的样本量,被引用的频率更高,且发表在影响因子更高的期刊上。
使用PubMed标识符搜索数据库条目可以识别出大多数公开可用的数据集,但在使用此方法收集数据用于政策评估时需谨慎,因为低影响因子期刊中的研究被不成比例地排除了。我们敦促所有数据集的作者在已知出版细节后,为其数据集提交完成引用字段,从而确保他们的工作具有最大的可见性,并能为后续研究做出贡献。