Wendl Michael C, Smith Scott, Pohl Craig S, Dooling David J, Chinwalla Asif T, Crouse Kevin, Hepler Todd, Leong Shin, Carmichael Lynn, Nhan Mike, Oberkfell Benjamin J, Mardis Elaine R, Hillier LaDeana W, Wilson Richard K
Genome Sequencing Center, Washington University, St, Louis, MO 63108, USA.
BMC Bioinformatics. 2007 Sep 26;8:362. doi: 10.1186/1471-2105-8-362.
Investigators in the biological sciences continue to exploit laboratory automation methods and have dramatically increased the rates at which they can generate data. In many environments, the methods themselves also evolve in a rapid and fluid manner. These observations point to the importance of robust information management systems in the modern laboratory. Designing and implementing such systems is non-trivial and it appears that in many cases a database project ultimately proves unserviceable.
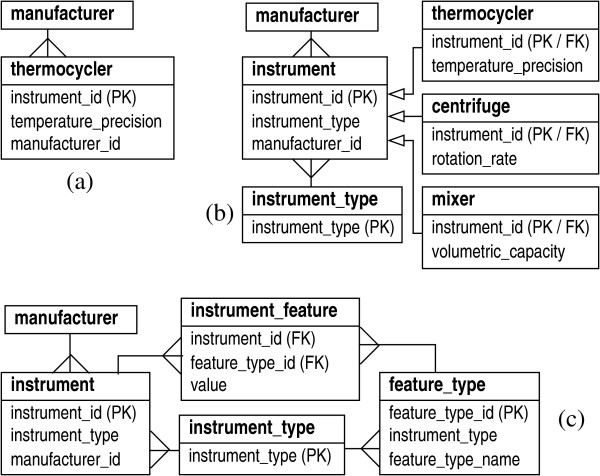
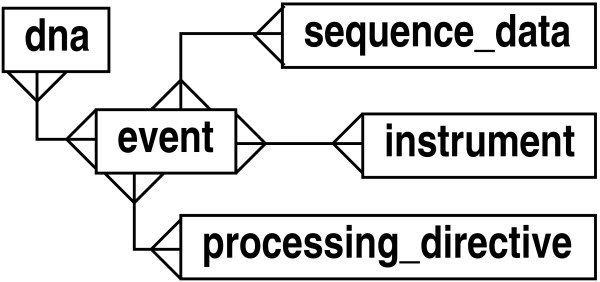
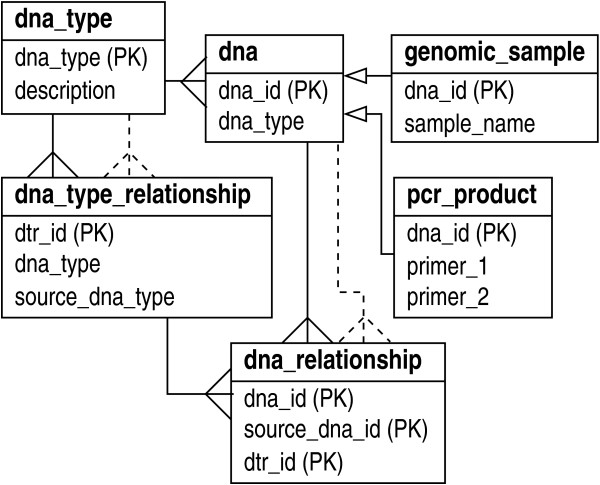
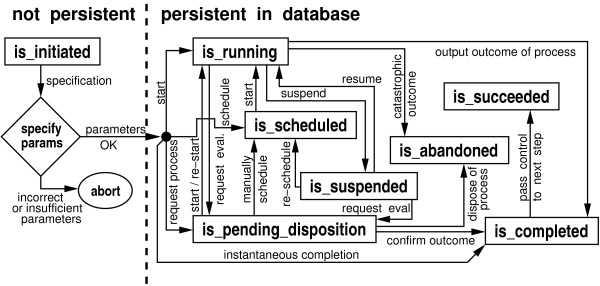
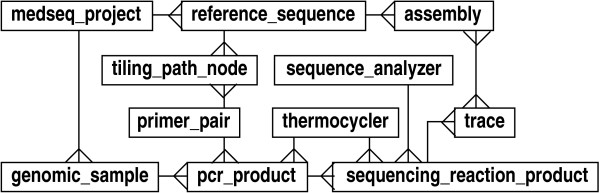
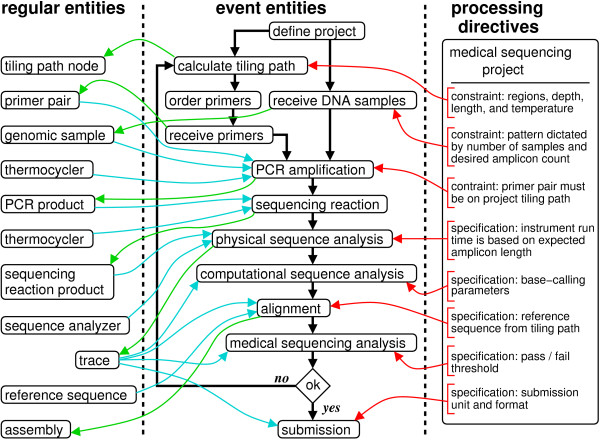
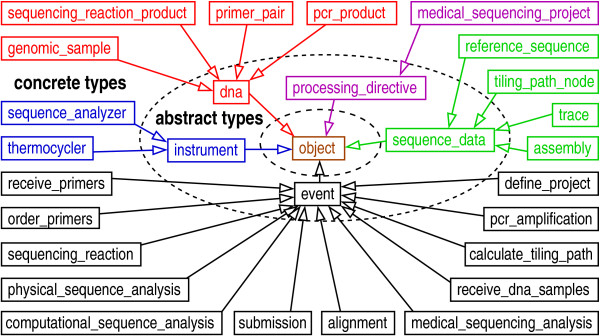
We describe a general modeling framework for laboratory data and its implementation as an information management system. The model utilizes several abstraction techniques, focusing especially on the concepts of inheritance and meta-data. Traditional approaches commingle event-oriented data with regular entity data in ad hoc ways. Instead, we define distinct regular entity and event schemas, but fully integrate these via a standardized interface. The design allows straightforward definition of a "processing pipeline" as a sequence of events, obviating the need for separate workflow management systems. A layer above the event-oriented schema integrates events into a workflow by defining "processing directives", which act as automated project managers of items in the system. Directives can be added or modified in an almost trivial fashion, i.e., without the need for schema modification or re-certification of applications. Association between regular entities and events is managed via simple "many-to-many" relationships. We describe the programming interface, as well as techniques for handling input/output, process control, and state transitions.
The implementation described here has served as the Washington University Genome Sequencing Center's primary information system for several years. It handles all transactions underlying a throughput rate of about 9 million sequencing reactions of various kinds per month and has handily weathered a number of major pipeline reconfigurations. The basic data model can be readily adapted to other high-volume processing environments.
生物科学领域的研究人员不断采用实验室自动化方法,极大地提高了数据生成的速度。在许多环境中,这些方法本身也在快速且灵活地发展。这些观察结果表明了强大的信息管理系统在现代实验室中的重要性。设计和实施这样的系统并非易事,而且在许多情况下,数据库项目最终被证明无法使用。
我们描述了一个用于实验室数据的通用建模框架及其作为信息管理系统的实现。该模型采用了多种抽象技术,尤其侧重于继承和元数据的概念。传统方法以临时方式将面向事件的数据与常规实体数据混合在一起。相反,我们定义了不同的常规实体和事件模式,但通过标准化接口将它们完全集成。该设计允许将“处理管道”直接定义为一系列事件,从而无需单独的工作流管理系统。面向事件模式之上的一层通过定义“处理指令”将事件集成到工作流中,这些指令充当系统中项目的自动化项目经理。可以以几乎简单的方式添加或修改指令,即无需修改模式或重新认证应用程序。常规实体与事件之间的关联通过简单的“多对多”关系进行管理。我们描述了编程接口以及处理输入/输出、过程控制和状态转换的技术。
这里描述的实现多年来一直是华盛顿大学基因组测序中心的主要信息系统。它处理每月约900万个各种测序反应的通量率下的所有事务,并轻松经受住了多次主要管道重新配置。基本数据模型可以很容易地适应其他高容量处理环境。