Gana Dresen Irina M, Boes Tanja, Huesing Johannes, Neuhaeuser Markus, Joeckel Karl-Heinz
Institut für Medizinische Informatik, Biometrie und Epidemiologie, Universitaetsklinikum Essen, Germany.
BMC Bioinformatics. 2008 Jan 24;9:42. doi: 10.1186/1471-2105-9-42.
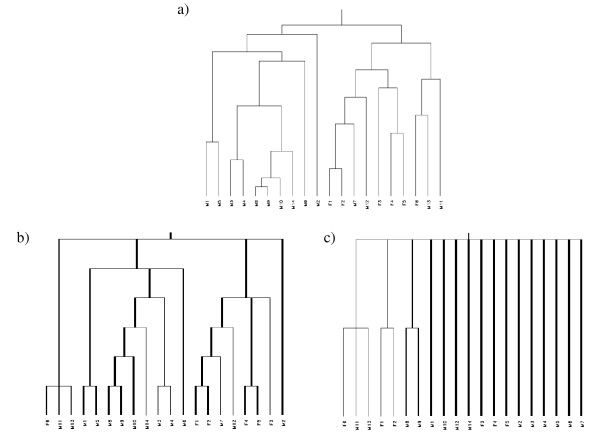
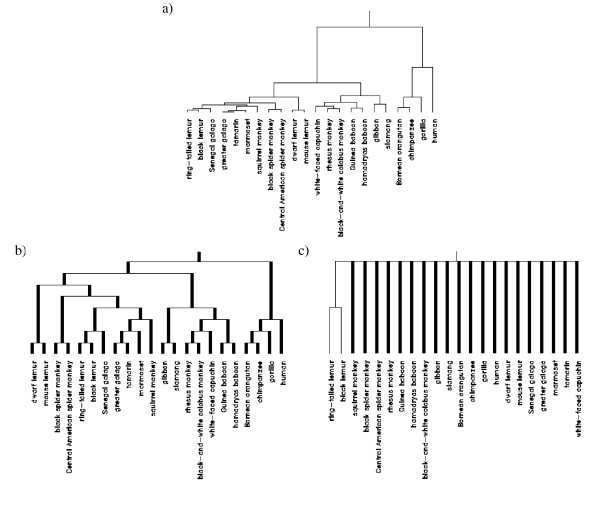
Hierarchical clustering is a widely applied tool in the analysis of microarray gene expression data. The assessment of cluster stability is a major challenge in clustering procedures. Statistical methods are required to distinguish between real and random clusters. Several methods for assessing cluster stability have been published, including resampling methods such as the bootstrap. We propose a new resampling method based on continuous weights to assess the stability of clusters in hierarchical clustering. While in bootstrapping approximately one third of the original items is lost, continuous weights avoid zero elements and instead allow non integer diagonal elements, which leads to retention of the full dimensionality of space, i.e. each variable of the original data set is represented in the resampling sample.
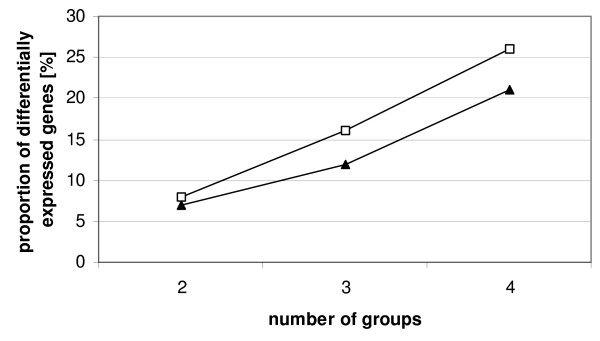
Comparison of continuous weights and bootstrapping using real datasets and simulation studies reveals the advantage of continuous weights especially when the dataset has only few observations, few differentially expressed genes and the fold change of differentially expressed genes is low.
We recommend the use of continuous weights in small as well as in large datasets, because according to our results they produce at least the same results as conventional bootstrapping and in some cases they surpass it.
层次聚类是微阵列基因表达数据分析中广泛应用的工具。聚类稳定性评估是聚类过程中的一项重大挑战。需要统计方法来区分真实聚类和随机聚类。已经发表了几种评估聚类稳定性的方法,包括重采样方法,如自助法。我们提出了一种基于连续权重的新重采样方法,以评估层次聚类中聚类的稳定性。在自助法中,大约三分之一的原始数据项会丢失,而连续权重避免了零元素,取而代之的是允许非整数对角元素,这导致保留了空间的全维度,即原始数据集中的每个变量都在重采样样本中得到体现。
使用真实数据集和模拟研究对连续权重和自助法进行比较,结果表明连续权重具有优势,尤其是当数据集观测值较少、差异表达基因较少且差异表达基因的倍数变化较低时。
我们建议在小数据集和大数据集中都使用连续权重,因为根据我们的结果,它们至少能产生与传统自助法相同的结果,并且在某些情况下优于传统自助法。