Genes and Development Group, Centre for Integrative Physiology, University of Edinburgh, Hugh Robson Building, George Square, Edinburgh, EH8 9XD, UK.
BMC Bioinformatics. 2010 Dec 3;11:590. doi: 10.1186/1471-2105-11-590.
One of the most commonly performed tasks when analysing high throughput gene expression data is to use clustering methods to classify the data into groups. There are a large number of methods available to perform clustering, but it is often unclear which method is best suited to the data and how to quantify the quality of the classifications produced.
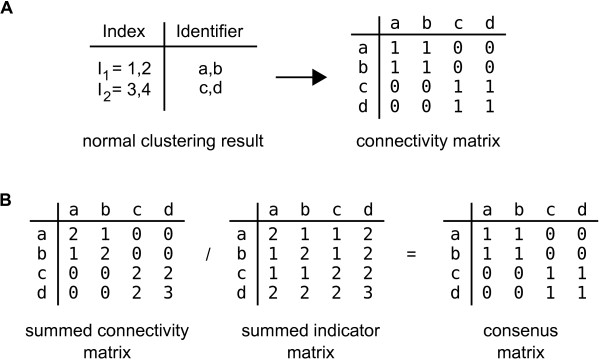
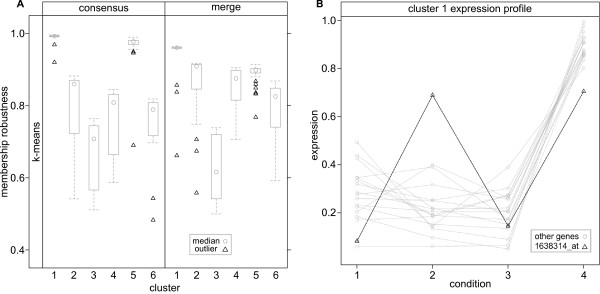
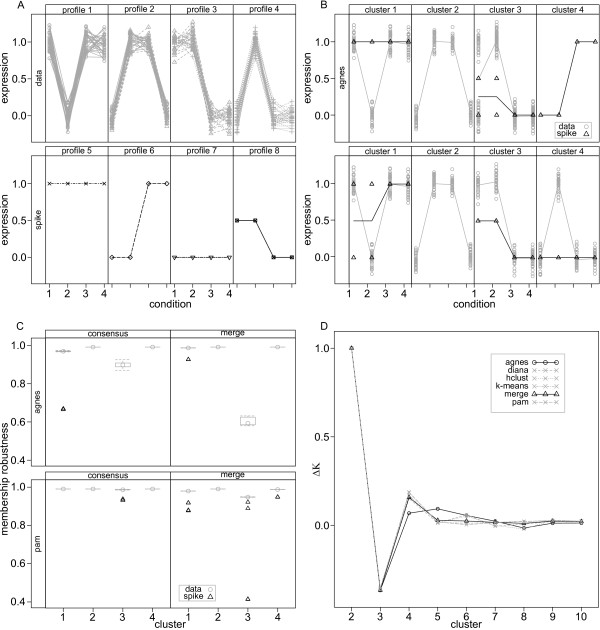
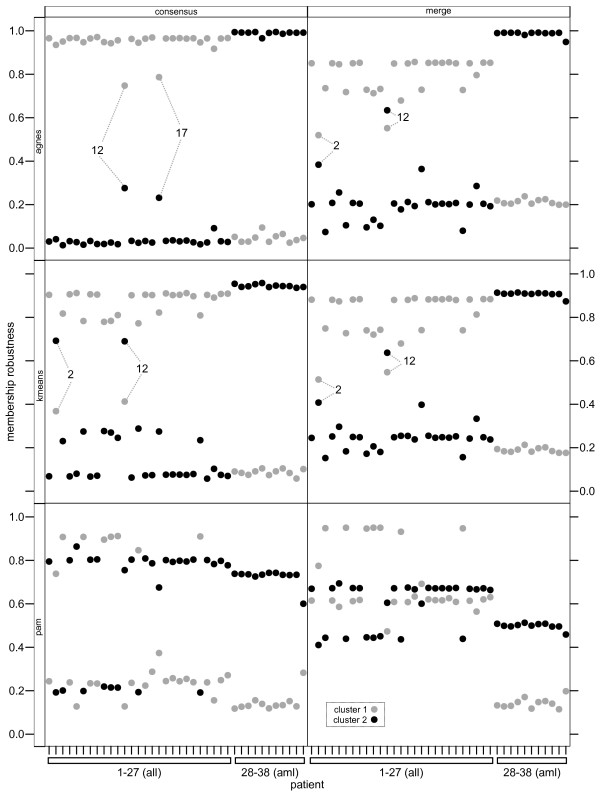
Here we describe an R package containing methods to analyse the consistency of clustering results from any number of different clustering methods using resampling statistics. These methods allow the identification of the the best supported clusters and additionally rank cluster members by their fidelity within the cluster. These metrics allow us to compare the performance of different clustering algorithms under different experimental conditions and to select those that produce the most reliable clustering structures. We show the application of this method to simulated data, canonical gene expression experiments and our own novel analysis of genes involved in the specification of the peripheral nervous system in the fruitfly, Drosophila melanogaster.
Our package enables users to apply the merged consensus clustering methodology conveniently within the R programming environment, providing both analysis and graphical display functions for exploring clustering approaches. It extends the basic principle of consensus clustering by allowing the merging of results between different methods to provide an averaged clustering robustness. We show that this extension is useful in correcting for the tendency of clustering algorithms to treat outliers differently within datasets. The R package, clusterCons, is freely available at CRAN and sourceforge under the GNU public licence.
在分析高通量基因表达数据时,最常执行的任务之一是使用聚类方法将数据分为若干组。有大量的方法可用于执行聚类,但通常不清楚哪种方法最适合数据,以及如何量化分类的质量。
在这里,我们描述了一个 R 包,其中包含使用重采样统计信息分析任意数量的不同聚类方法的聚类结果一致性的方法。这些方法允许识别最受支持的聚类,并且还可以根据其在聚类中的保真度对聚类成员进行排序。这些指标允许我们在不同的实验条件下比较不同聚类算法的性能,并选择那些产生最可靠聚类结构的算法。我们展示了该方法在模拟数据、典型基因表达实验以及我们自己对参与果蝇外周神经系统特化的基因的新分析中的应用。
我们的软件包使用户能够在 R 编程环境中方便地应用合并共识聚类方法,提供用于探索聚类方法的分析和图形显示功能。它通过允许在不同方法之间合并结果来扩展共识聚类的基本原理,以提供平均聚类稳健性。我们表明,这种扩展对于纠正聚类算法在数据集内对待异常值的不同方式是有用的。R 包 clusterCons 可在 CRAN 和sourceforge 上根据 GNU 公共许可证免费获得。