Li Guo-Zheng, Bu Hua-Long, Yang Mary Qu, Zeng Xue-Qiang, Yang Jack Y
Department of Control Science & Engineering, Tongji University, Shanghai 201804, PR China.
BMC Genomics. 2008 Sep 16;9 Suppl 2(Suppl 2):S24. doi: 10.1186/1471-2164-9-S2-S24.
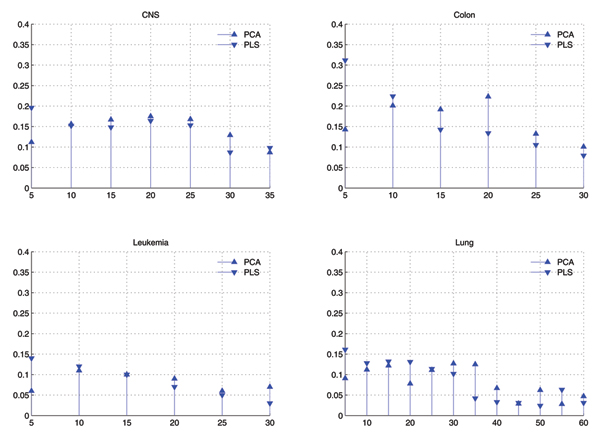
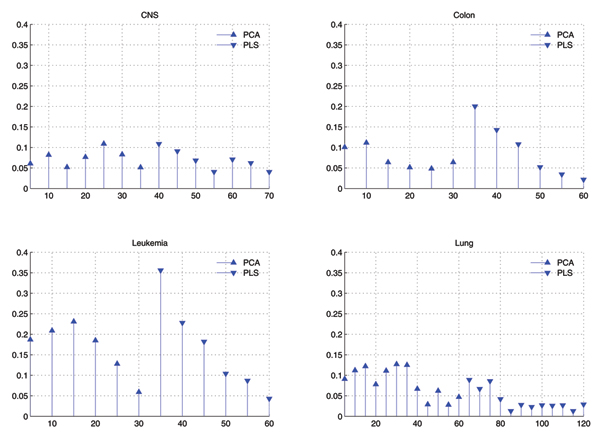
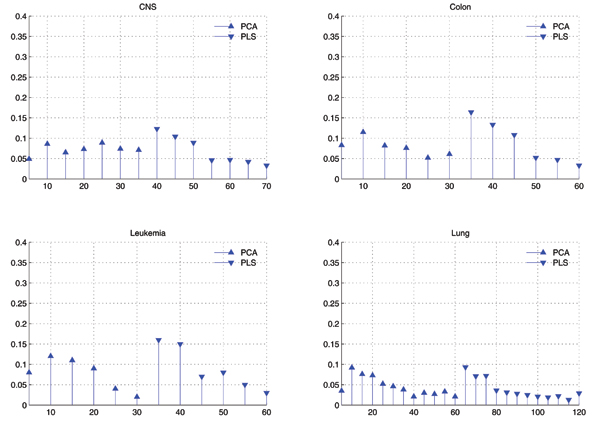
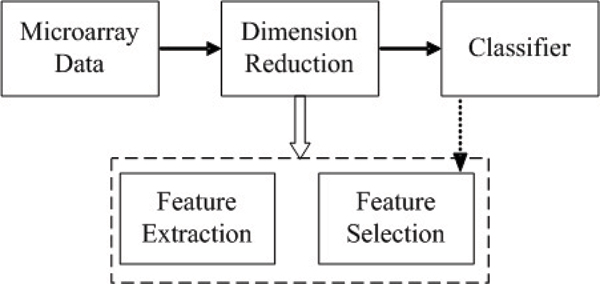
Dimension reduction is a critical issue in the analysis of microarray data, because the high dimensionality of gene expression microarray data set hurts generalization performance of classifiers. It consists of two types of methods, i.e. feature selection and feature extraction. Principle component analysis (PCA) and partial least squares (PLS) are two frequently used feature extraction methods, and in the previous works, the top several components of PCA or PLS are selected for modeling according to the descending order of eigenvalues. While in this paper, we prove that not all the top features are useful, but features should be selected from all the components by feature selection methods.
We demonstrate a framework for selecting feature subsets from all the newly extracted components, leading to reduced classification error rates on the gene expression microarray data. Here we have considered both an unsupervised method PCA and a supervised method PLS for extracting new components, genetic algorithms for feature selection, and support vector machines and k nearest neighbor for classification. Experimental results illustrate that our proposed framework is effective to select feature subsets and to reduce classification error rates.
Not only the top features newly extracted by PCA or PLS are important, therefore, feature selection should be performed to select subsets from new features to improve generalization performance of classifiers.
在微阵列数据分析中,降维是一个关键问题,因为基因表达微阵列数据集的高维度会损害分类器的泛化性能。它由两种类型的方法组成,即特征选择和特征提取。主成分分析(PCA)和偏最小二乘法(PLS)是两种常用的特征提取方法,在以往的工作中,根据特征值的降序选择PCA或PLS的前几个成分进行建模。而在本文中,我们证明并非所有的顶级特征都是有用的,而应该通过特征选择方法从所有成分中选择特征。
我们展示了一个从所有新提取的成分中选择特征子集的框架,从而降低了基因表达微阵列数据的分类错误率。这里我们考虑了用于提取新成分的无监督方法PCA和有监督方法PLS、用于特征选择的遗传算法以及用于分类的支持向量机和k近邻算法。实验结果表明,我们提出的框架对于选择特征子集和降低分类错误率是有效的。
因此,不仅PCA或PLS新提取的顶级特征很重要,还应该进行特征选择以从新特征中选择子集,从而提高分类器的泛化性能。