Pieper Ursula, Eswar Narayanan, Webb Ben M, Eramian David, Kelly Libusha, Barkan David T, Carter Hannah, Mankoo Parminder, Karchin Rachel, Marti-Renom Marc A, Davis Fred P, Sali Andrej
Department of Bioengineering and Therapeutic Sciences, Department of Pharmaceutical Chemistry, University of California at San Francisco, 1700 4th Street, San Francisco, CA 94158, USA.
Nucleic Acids Res. 2009 Jan;37(Database issue):D347-54. doi: 10.1093/nar/gkn791. Epub 2008 Oct 23.
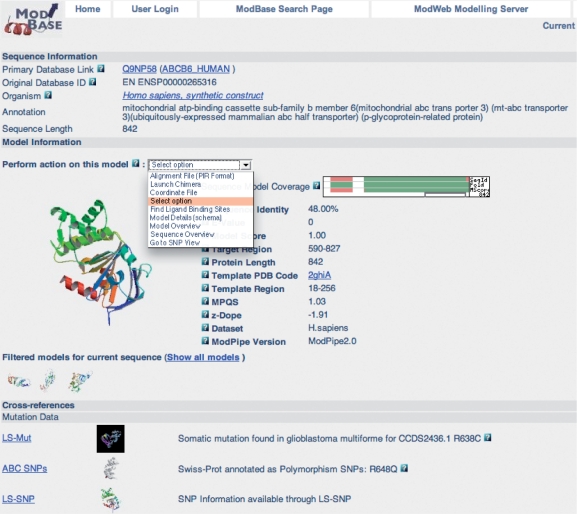
MODBASE (http://salilab.org/modbase) is a database of annotated comparative protein structure models. The models are calculated by MODPIPE, an automated modeling pipeline that relies primarily on MODELLER for fold assignment, sequence-structure alignment, model building and model assessment (http:/salilab.org/modeller). MODBASE currently contains 5,152,695 reliable models for domains in 1,593,209 unique protein sequences; only models based on statistically significant alignments and/or models assessed to have the correct fold are included. MODBASE also allows users to calculate comparative models on demand, through an interface to the MODWEB modeling server (http://salilab.org/modweb). Other resources integrated with MODBASE include databases of multiple protein structure alignments (DBAli), structurally defined ligand binding sites (LIGBASE), predicted ligand binding sites (AnnoLyze), structurally defined binary domain interfaces (PIBASE) and annotated single nucleotide polymorphisms and somatic mutations found in human proteins (LS-SNP, LS-Mut). MODBASE models are also available through the Protein Model Portal (http://www.proteinmodelportal.org/).