The Protein Chemistry Group, Institute for Medical Biochemistry, Centre for Biomedical Education and Research, School of Medicine, Faculty of Health, Witten/Herdecke University, Stockumer Str. 10, Witten 58448, Germany.
BMC Bioinformatics. 2012 Sep 8;13:223. doi: 10.1186/1471-2105-13-223.
The COG database is the most popular collection of orthologous proteins from many different completely sequenced microbial genomes. Per definition, a cluster of orthologous groups (COG) within this database exclusively contains proteins that most likely achieve the same cellular function. Recently, the COG database was extended by assigning to every protein both the corresponding amino acid and its encoding nucleotide sequence resulting in the NUCOCOG database. This extended version of the COG database is a valuable resource connecting sequence features with the functionality of the respective proteins.
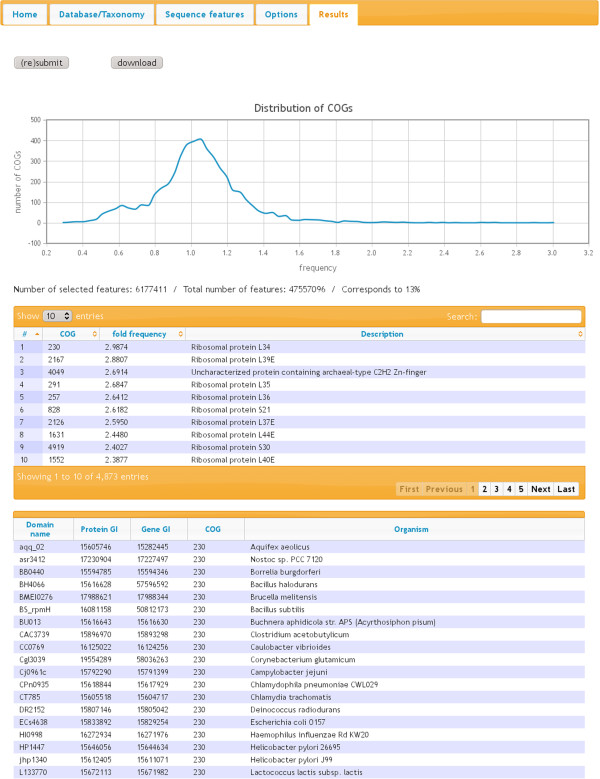
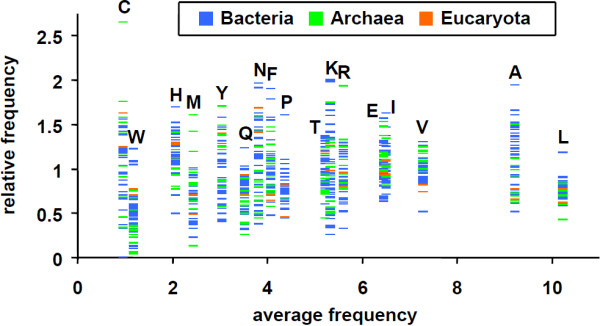
Here we present ANCAC, a web tool and MySQL database for the analysis of amino acid, nucleotide, and codon frequencies in COGs on the basis of freely definable phylogenetic patterns. We demonstrate the usefulness of ANCAC by analyzing amino acid frequencies, codon usage, and GC-content in a species- or function-specific context. With respect to amino acids we, at least in part, confirm the cognate bias hypothesis by using ANCAC's NUCOCOG dataset as the largest one available for that purpose thus far.
Using the NUCOCOG datasets, ANCAC connects taxonomic, amino acid, and nucleotide sequence information with the functional classification via COGs and provides a GUI for flexible mining for sequence-bias. Thereby, to our knowledge, it is the only tool for the analysis of sequence composition in the light of physiological roles and phylogenetic context without requirement of substantial programming-skills.
COG 数据库是最受欢迎的来自许多不同完全测序微生物基因组的同源蛋白集合。根据定义,该数据库中的一个同源簇(COG)仅包含最有可能实现相同细胞功能的蛋白质。最近,COG 数据库通过为每个蛋白质分配相应的氨基酸和编码核苷酸序列扩展为 NUCOCOG 数据库。该 COG 数据库的扩展版本是一个将序列特征与相应蛋白质功能连接起来的有价值的资源。
在这里,我们介绍了 ANCAC,这是一种基于可自由定义的系统发育模式分析 COG 中氨基酸、核苷酸和密码子频率的网络工具和 MySQL 数据库。我们通过在特定于物种或功能的上下文中分析氨基酸频率、密码子使用和 GC 含量来证明 ANCAC 的有用性。关于氨基酸,我们至少部分地通过使用 ANCAC 的 NUCOCOG 数据集证实了同源偏爱假说,因为这是迄今为止为此目的提供的最大数据集。
使用 NUCOCOG 数据集,ANCAC 通过 COG 将分类学、氨基酸和核苷酸序列信息与功能分类联系起来,并提供了一个用于灵活挖掘序列偏差的 GUI。因此,据我们所知,它是唯一一种无需大量编程技能即可根据生理角色和系统发育背景分析序列组成的工具。