Lee Chih, Abdool Ali, Huang Chun-Hsi
Computer Science and Engineering Department, University of Connecticut, Storrs, CT 06269, USA.
BMC Bioinformatics. 2009 Jan 30;10 Suppl 1(Suppl 1):S73. doi: 10.1186/1471-2105-10-S1-S73.
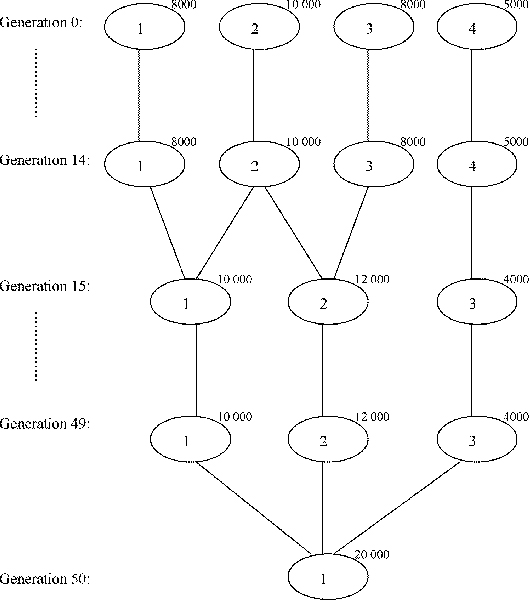
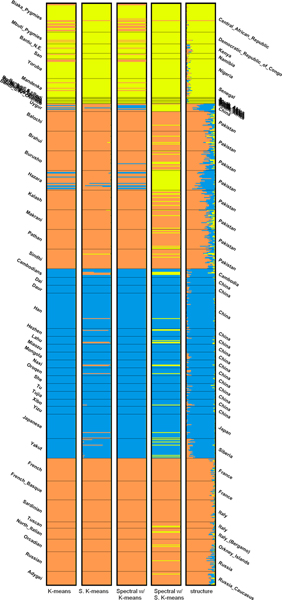
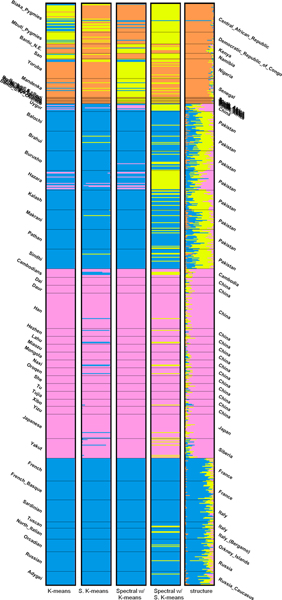
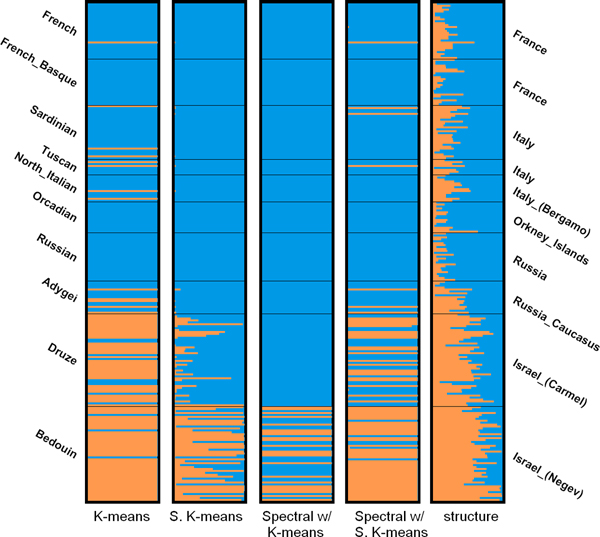
Handling genotype data typed at hundreds of thousands of loci is very time-consuming and it is no exception for population structure inference. Therefore, we propose to apply PCA to the genotype data of a population, select the significant principal components using the Tracy-Widom distribution, and assign the individuals to one or more subpopulations using generic clustering algorithms.
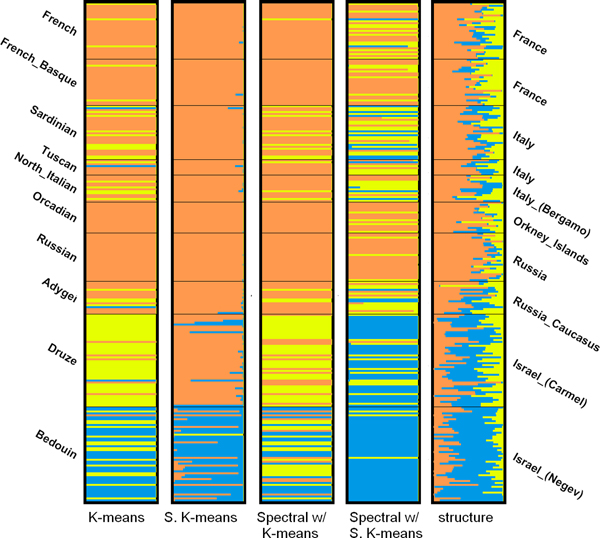
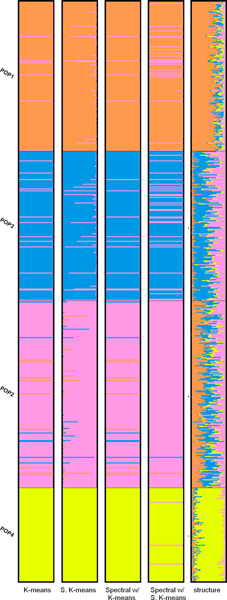
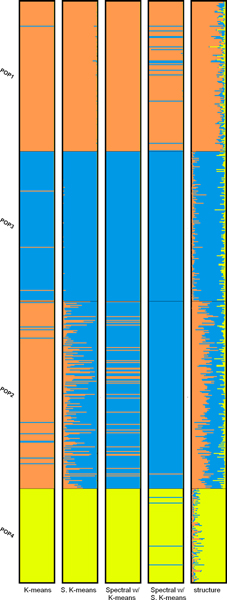
We investigated K-means, soft K-means and spectral clustering and made comparison to STRUCTURE, a model-based algorithm specifically designed for population structure inference. Moreover, we investigated methods for predicting the number of subpopulations in a population. The results on four simulated datasets and two real datasets indicate that our approach performs comparably well to STRUCTURE. For the simulated datasets, STRUCTURE and soft K-means with BIC produced identical predictions on the number of subpopulations. We also showed that, for real dataset, BIC is a better index than likelihood in predicting the number of subpopulations.
Our approach has the advantage of being fast and scalable, while STRUCTURE is very time-consuming because of the nature of MCMC in parameter estimation. Therefore, we suggest choosing the proper algorithm based on the application of population structure inference.
处理数十万个位点的基因型数据非常耗时,群体结构推断也不例外。因此,我们建议对一个群体的基因型数据应用主成分分析(PCA),使用 Tracy-Widom 分布选择显著的主成分,并使用通用聚类算法将个体分配到一个或多个亚群体。
我们研究了 K 均值、软 K 均值和谱聚类,并与专门为群体结构推断设计的基于模型的算法 STRUCTURE 进行了比较。此外,我们研究了预测群体中亚群体数量的方法。在四个模拟数据集和两个真实数据集上的结果表明,我们的方法与 STRUCTURE 的表现相当。对于模拟数据集,STRUCTURE 和使用贝叶斯信息准则(BIC)的软 K 均值对亚群体数量产生了相同的预测。我们还表明,对于真实数据集,在预测亚群体数量方面,BIC 是比似然性更好的指标。
我们的方法具有快速且可扩展的优点,而由于参数估计中马尔可夫链蒙特卡罗(MCMC)的性质,STRUCTURE 非常耗时。因此,我们建议根据群体结构推断的应用选择合适的算法。