Faculty of Engineering, King Mongkut's Institute of Technology Ladkrabang, Bangkok, Thailand.
BMC Bioinformatics. 2011 Jun 23;12:255. doi: 10.1186/1471-2105-12-255.
The ever increasing sizes of population genetic datasets pose great challenges for population structure analysis. The Tracy-Widom (TW) statistical test is widely used for detecting structure. However, it has not been adequately investigated whether the TW statistic is susceptible to type I error, especially in large, complex datasets. Non-parametric, Principal Component Analysis (PCA) based methods for resolving structure have been developed which rely on the TW test. Although PCA-based methods can resolve structure, they cannot infer ancestry. Model-based methods are still needed for ancestry analysis, but they are not suitable for large datasets. We propose a new structure analysis framework for large datasets. This includes a new heuristic for detecting structure and incorporation of the structure patterns inferred by a PCA method to complement STRUCTURE analysis.
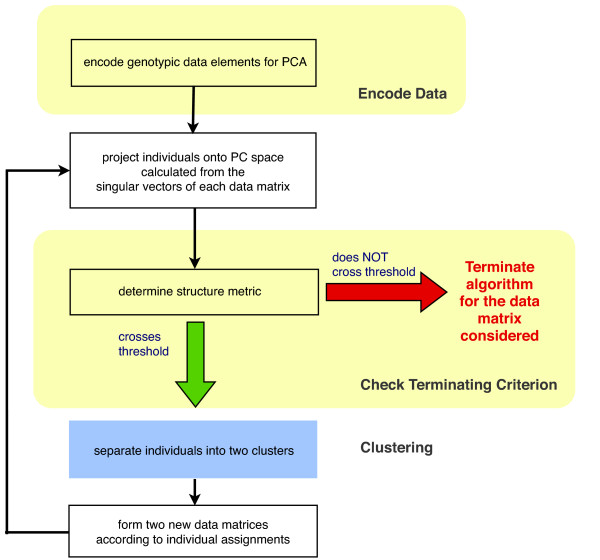
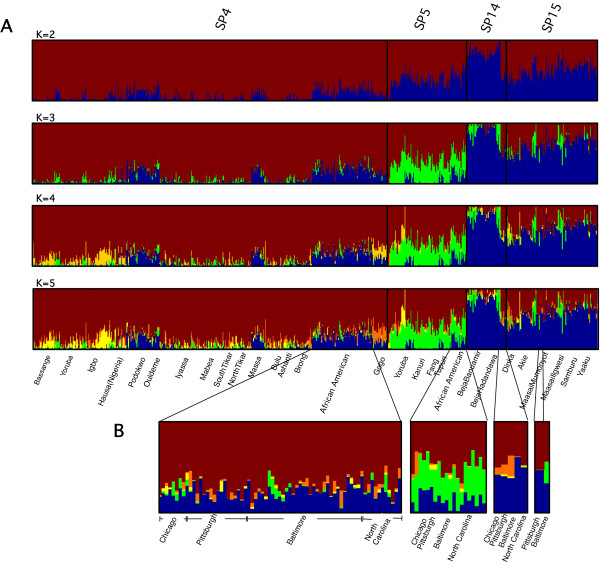
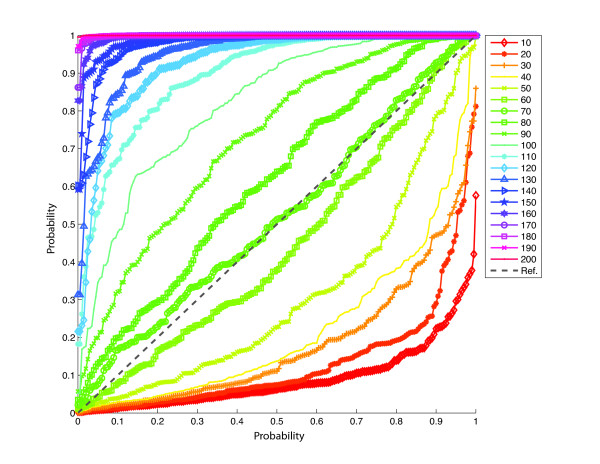
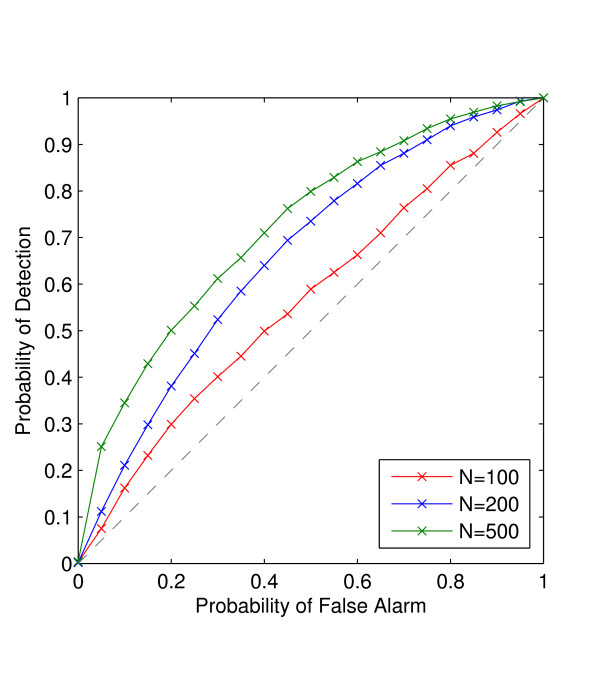
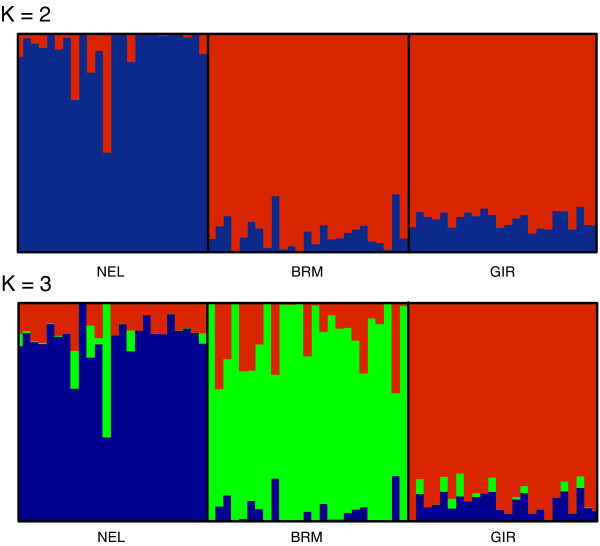
A new heuristic called EigenDev for detecting population structure is presented. When tested on simulated data, this heuristic is robust to sample size. In contrast, the TW statistic was found to be susceptible to type I error, especially for large population samples. EigenDev is thus better-suited for analysis of large datasets containing many individuals, in which spurious patterns are likely to exist and could be incorrectly interpreted as population stratification. EigenDev was applied to the iterative pruning PCA (ipPCA) method, which resolves the underlying subpopulations. This subpopulation information was used to supervise STRUCTURE analysis to infer patterns of ancestry at an unprecedented level of resolution. To validate the new approach, a bovine and a large human genetic dataset (3945 individuals) were analyzed. We found new ancestry patterns consistent with the subpopulations resolved by ipPCA.
The EigenDev heuristic is robust to sampling and is thus superior for detecting structure in large datasets. The application of EigenDev to the ipPCA algorithm improves the estimation of the number of subpopulations and the individual assignment accuracy, especially for very large and complex datasets. Furthermore, we have demonstrated that the structure resolved by this approach complements parametric analysis, allowing a much more comprehensive account of population structure. The new version of the ipPCA software with EigenDev incorporated can be downloaded from http://www4a.biotec.or.th/GI/tools/ippca.
不断增长的人口遗传数据集给群体结构分析带来了巨大的挑战。特雷西- widom (TW)统计检验被广泛用于检测结构。然而,TW 统计量是否容易出现 I 型错误,特别是在大型、复杂的数据集上,尚未得到充分研究。已经开发了基于非参数、主成分分析(PCA)的方法来解决结构问题,这些方法依赖于 TW 检验。虽然基于 PCA 的方法可以解决结构问题,但它们不能推断祖先。仍然需要基于模型的方法进行祖先分析,但它们不适合大型数据集。我们提出了一种新的用于大型数据集的结构分析框架。这包括一种新的检测结构的启发式方法,并结合 PCA 方法推断出的结构模式来补充 STRUCTURE 分析。
提出了一种新的启发式方法,称为 EigenDev,用于检测群体结构。在测试模拟数据时,该启发式方法对样本大小具有鲁棒性。相比之下,TW 统计量被发现容易出现 I 型错误,特别是对于大的群体样本。因此,EigenDev 更适合分析包含许多个体的大型数据集,在这些数据集中,可能存在虚假模式,并可能被错误地解释为群体分层。EigenDev 被应用于迭代修剪 PCA(ipPCA)方法,该方法解决了潜在的亚群。使用该亚群信息来监督 STRUCTURE 分析,以空前的分辨率推断出祖先模式。为了验证新方法,分析了一个牛和一个大型人类遗传数据集(3945 个人)。我们发现了与 ipPCA 解析的亚群一致的新的祖先模式。
EigenDev 启发式方法对抽样具有鲁棒性,因此更适合于大型数据集的结构检测。将 EigenDev 应用于 ipPCA 算法可以提高亚群数量的估计和个体分配的准确性,特别是对于非常大和复杂的数据集。此外,我们已经证明,这种方法解析的结构补充了参数分析,允许更全面地描述群体结构。带有集成 EigenDev 的新版本 ipPCA 软件可以从 http://www4a.biotec.or.th/GI/tools/ippca 下载。