Rakovski Cyril S, Stram Daniel O
Department of Mathematics and Computer Science, Chapman University, Orange, California, United States of America.
PLoS One. 2009 Jun 8;4(6):e5825. doi: 10.1371/journal.pone.0005825.
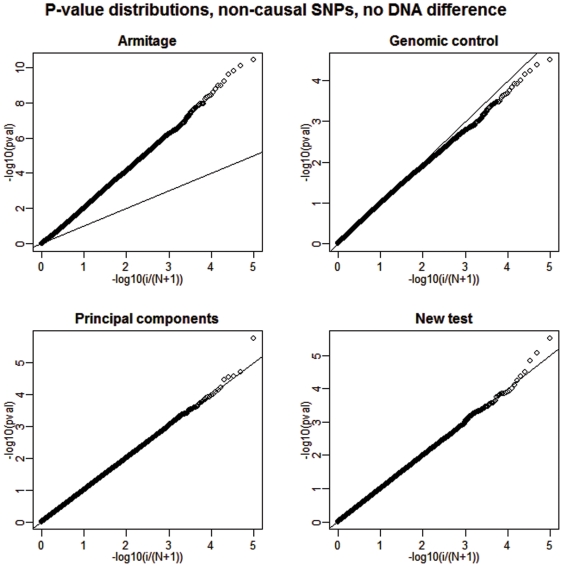
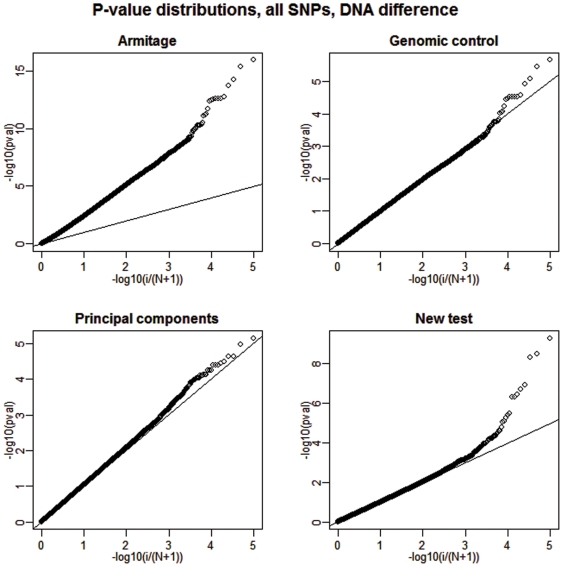
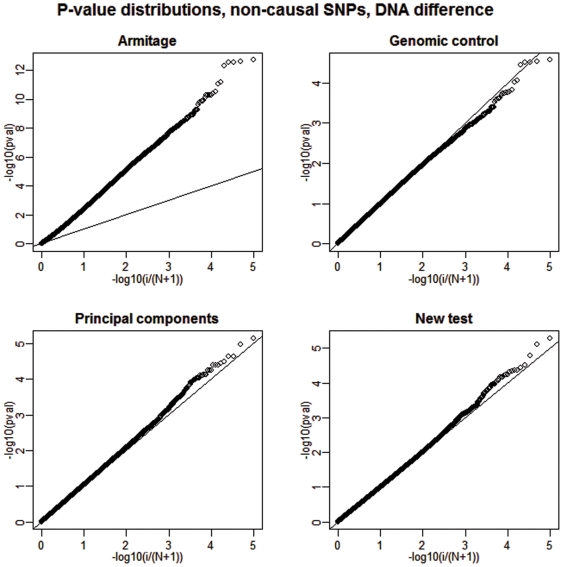
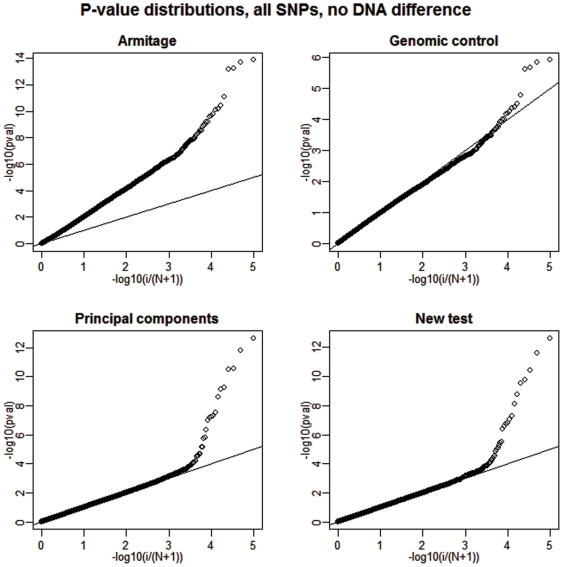
BACKGROUND/AIMS: We propose a modification of the well-known Armitage trend test to address the problems associated with hidden population structure and hidden relatedness in genome-wide case-control association studies.
The new test adopts beneficial traits from three existing testing strategies: the principal components, mixed model, and genomic control while avoiding some of their disadvantageous characteristics, such as the tendency of the principal components method to over-correct in certain situations or the failure of the genomic control approach to reorder the adjusted tests based on their degree of alignment with the underlying hidden structure. The new procedure is based on Gauss-Markov estimators derived from a straightforward linear model with an imposed variance structure proportional to an empirical relatedness matrix. Lastly, conceptual and analytical similarities to and distinctions from other approaches are emphasized throughout.
Our simulations show that the power performance of the proposed test is quite promising compared to the considered competing strategies. The power gains are especially large when small differential differences between cases and controls are present; a likely scenario when public controls are used in multiple studies.
The proposed modified approach attains high power more consistently than that of the existing commonly implemented tests. Its performance improvement is most apparent when small but detectable systematic differences between cases and controls exist.
背景/目的:我们提出对著名的阿米蒂奇趋势检验进行修改,以解决全基因组病例对照关联研究中与隐藏群体结构和隐藏相关性相关的问题。
新检验采用了三种现有检验策略的有益特性:主成分分析、混合模型和基因组控制,同时避免了它们的一些不利特征,例如主成分分析方法在某些情况下过度校正的趋势,或者基因组控制方法无法根据与潜在隐藏结构的对齐程度对调整后的检验进行重新排序。新程序基于从一个简单线性模型导出的高斯 - 马尔可夫估计量,该线性模型具有与经验相关性矩阵成比例的强制方差结构。最后,自始至终强调了与其他方法在概念和分析上的异同。
我们的模拟表明,与所考虑的竞争策略相比,所提出检验的功效表现很有前景。当病例与对照之间存在微小差异时,功效提升尤为显著;在多项研究中使用公共对照时可能会出现这种情况。
所提出的改进方法比现有的常用检验更一致地获得高功效。当病例与对照之间存在微小但可检测的系统差异时,其性能提升最为明显。