Computer Languages and Computing Science Department, Higher Technical School of Computer Science Engineering, University of Málaga, Málaga, 29071, Spain.
BMC Bioinformatics. 2009 Oct 1;10 Suppl 10(Suppl 10):S5. doi: 10.1186/1471-2105-10-S10-S5.
The analysis of information in the biological domain is usually focused on the analysis of data from single on-line data sources. Unfortunately, studying a biological process requires having access to disperse, heterogeneous, autonomous data sources. In this context, an analysis of the information is not possible without the integration of such data.
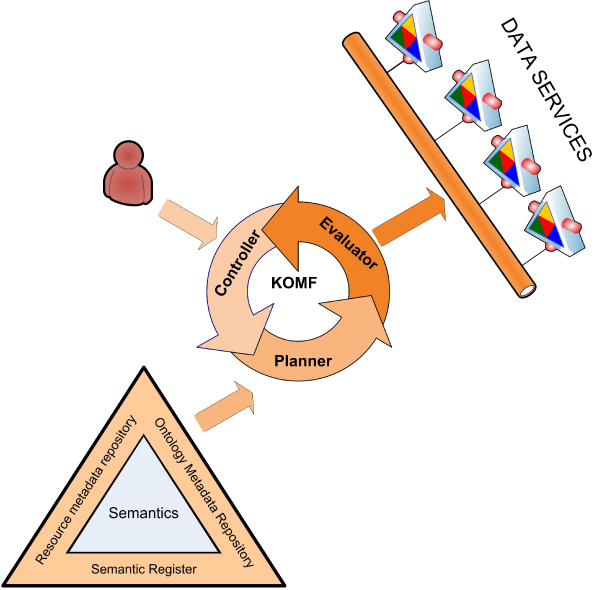
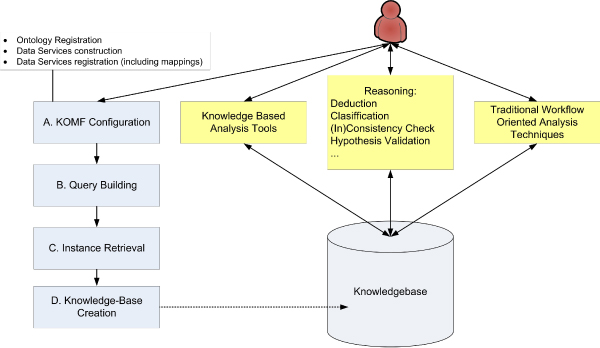
KA-SB is a querying and analysis system for final users based on combining a data integration solution with a reasoner. Thus, the tool has been created with a process divided into two steps: 1) KOMF, the Khaos Ontology-based Mediator Framework, is used to retrieve information from heterogeneous and distributed databases; 2) the integrated information is crystallized in a (persistent and high performance) reasoner (DBOWL). This information could be further analyzed later (by means of querying and reasoning).
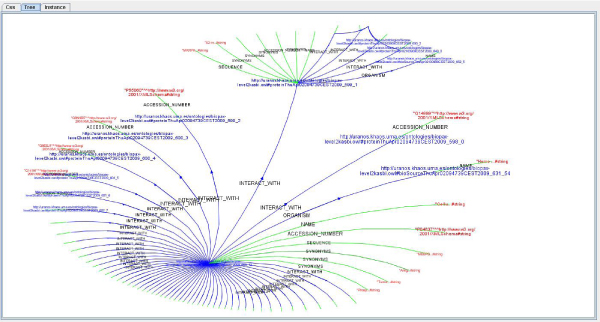
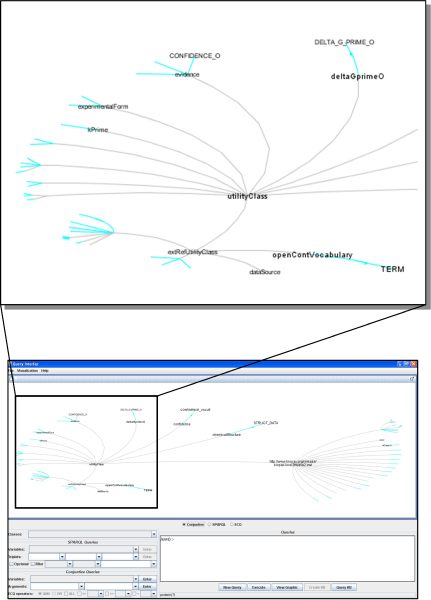
In this paper we present a novel system that combines the use of a mediation system with the reasoning capabilities of a large scale reasoner to provide a way of finding new knowledge and of analyzing the integrated information from different databases, which is retrieved as a set of ontology instances. This tool uses a graphical query interface to build user queries easily, which shows a graphical representation of the ontology and allows users o build queries by clicking on the ontology concepts.
These kinds of systems (based on KOMF) will provide users with very large amounts of information (interpreted as ontology instances once retrieved), which cannot be managed using traditional main memory-based reasoners. We propose a process for creating persistent and scalable knowledgebases from sets of OWL instances obtained by integrating heterogeneous data sources with KOMF. This process has been applied to develop a demo tool http://khaos.uma.es/KA-SB, which uses the BioPax Level 3 ontology as the integration schema, and integrates UNIPROT, KEGG, CHEBI, BRENDA and SABIORK databases.
生物领域的信息分析通常侧重于分析来自单一在线数据源的数据。然而,研究生物过程需要访问分散、异构、自主的数据来源。在这种情况下,如果不整合这些数据,就不可能对信息进行分析。
KA-SB 是一个基于组合数据集成解决方案和推理机的最终用户查询和分析系统。因此,该工具的创建过程分为两个步骤:1)KOMF,基于 Khaos 本体的中介框架,用于从异构和分布式数据库中检索信息;2)将集成的信息结晶在一个(持久且高性能)推理机(DBOWL)中。这些信息可以在以后进一步分析(通过查询和推理)。
在本文中,我们提出了一种新的系统,该系统将中介系统的使用与大规模推理机的推理能力相结合,提供了一种从不同数据库中检索的一组本体实例中寻找新知识和分析集成信息的方法。该工具使用图形查询界面来轻松构建用户查询,该界面显示了本体的图形表示,并允许用户通过点击本体概念来构建查询。
这些系统(基于 KOMF)将为用户提供大量信息(检索后解释为本体实例),这是传统基于主内存的推理机无法管理的。我们提出了一种从使用 KOMF 集成异构数据源获得的 OWL 实例集中创建持久和可扩展知识库的过程。该过程已应用于开发一个演示工具 http://khaos.uma.es/KA-SB,该工具使用 BioPax Level 3 本体作为集成模式,并集成了 UNIPROT、KEGG、CHEBI、BRENDA 和 SABIORK 数据库。