Eshelman School of Pharmacy, University of North Carolina at Chapel Hill, NC, USA.
BMC Bioinformatics. 2009 Dec 18;10:431. doi: 10.1186/1471-2105-10-431.
Improvements in high-throughput technology and its increasing use have led to the generation of many highly complex datasets that often address similar biological questions. Combining information from these studies can increase the reliability and generalizability of results and also yield new insights that guide future research.
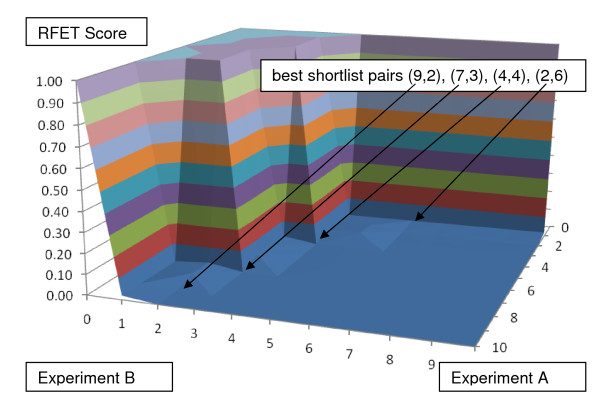
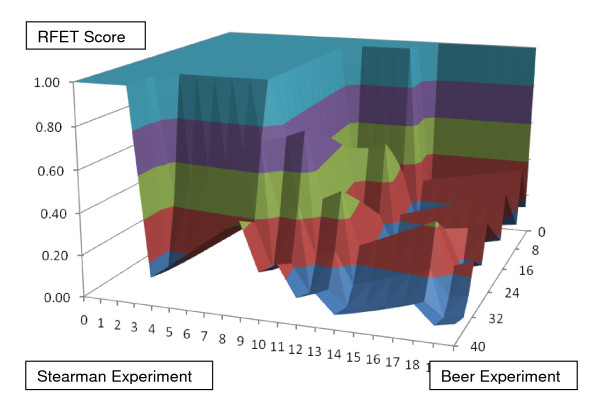
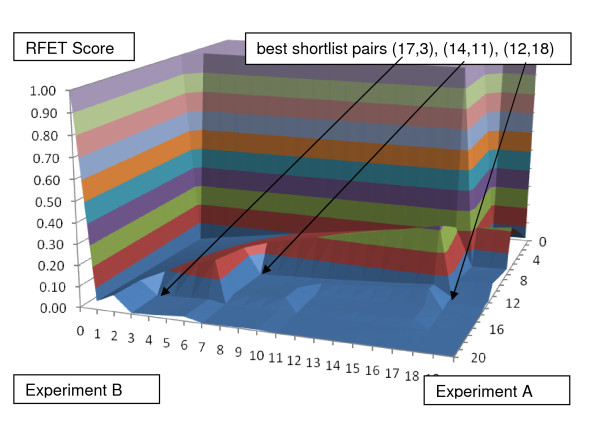
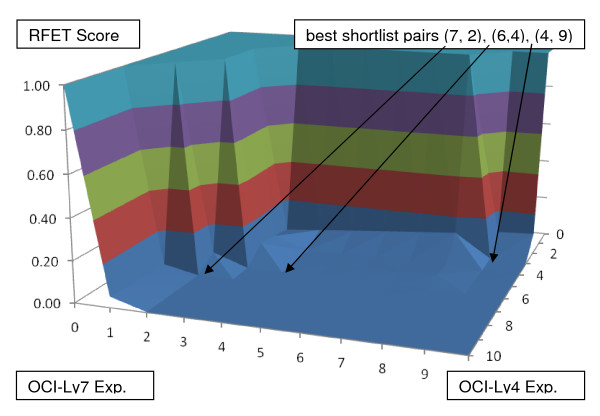
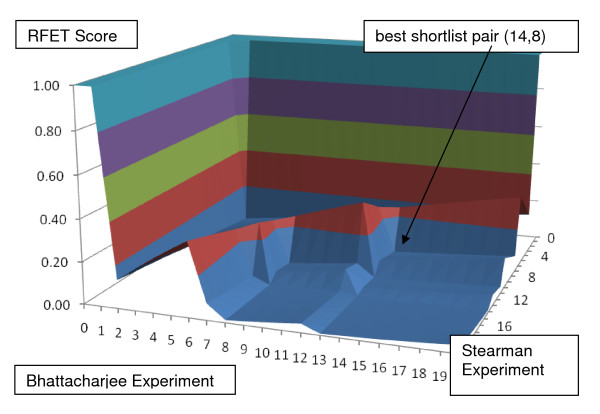
This paper describes a novel algorithm called BLANKET for symmetric analysis of two experiments that assess informativeness of descriptors. The experiments are required to be related only in that their descriptor sets intersect substantially and their definitions of case and control are consistent. From resulting lists of n descriptors ranked by informativeness, BLANKET determines shortlists of descriptors from each experiment, generally of different lengths p and q. For any pair of shortlists, four numbers are evident: the number of descriptors appearing in both shortlists, in exactly one shortlist, or in neither shortlist. From the associated contingency table, BLANKET computes Right Fisher Exact Test (RFET) values used as scores over a plane of possible pairs of shortlist lengths 12. BLANKET then chooses a pair or pairs with RFET score less than a threshold; the threshold depends upon n and shortlist length limits and represents a quality of intersection achieved by less than 5% of random lists.
Researchers seek within a universe of descriptors some minimal subset that collectively and efficiently predicts experimental outcomes. Ideally, any smaller subset should be insufficient for reliable prediction and any larger subset should have little additional accuracy. As a method, BLANKET is easy to conceptualize and presents only moderate computational complexity. Many existing databases could be mined using BLANKET to suggest optimal sets of predictive descriptors.
高通量技术的改进及其广泛应用产生了许多高度复杂的数据集,这些数据集通常都在研究类似的生物学问题。合并这些研究中的信息可以提高结果的可靠性和普遍性,并产生新的见解来指导未来的研究。
本文描述了一种名为 BLANKET 的新算法,用于对两个评估描述符信息量的实验进行对称分析。这些实验只需在其描述符集有很大的交集且病例和对照的定义一致这一点上具有相关性。从按信息量排序的 n 个描述符的结果列表中,BLANKET 从每个实验中确定描述符的短列表,通常长度为 p 和 q 不同。对于任何一对短列表,有四个数字是明显的:出现在两个短列表中的描述符数量、仅出现在一个短列表中的描述符数量,或者不出现在两个短列表中的描述符数量。从相关的列联表中,BLANKET 计算右 Fisher 精确检验(RFET)值,用作在可能的短列表长度 12 的平面上的得分。BLANKET 然后选择一对或多对具有低于阈值的 RFET 得分的短列表;该阈值取决于 n 和短列表长度限制,并代表少于 5%的随机列表所达到的交集质量。
研究人员在描述符的宇宙中寻求一些最小的子集,这些子集共同且有效地预测实验结果。理想情况下,任何更小的子集都不足以进行可靠的预测,而任何更大的子集都不会有太多额外的准确性。作为一种方法,BLANKET 易于理解,并且只具有中等的计算复杂性。许多现有的数据库可以使用 BLANKET 进行挖掘,以建议最佳的预测描述符集。