DECS Global Compound Sciences, Computational Chemistry, AstraZeneca R&D Mölndal, S-43183 Mölndal, Sweden.
J Cheminform. 2009 Jul 6;1(1):10. doi: 10.1186/1758-2946-1-10.
Since 2004 public cheminformatic databases and their collective functionality for exploring relationships between compounds, protein sequences, literature and assay data have advanced dramatically. In parallel, commercial sources that extract and curate such relationships from journals and patents have also been expanding. This work updates a previous comparative study of databases chosen because of their bioactive content, availability of downloads and facility to select informative subsets.
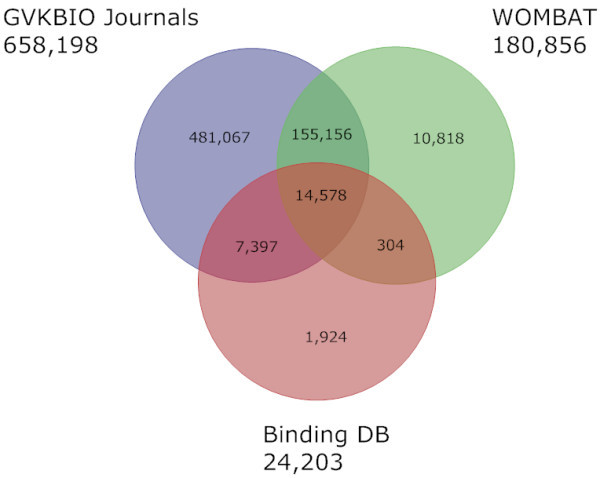
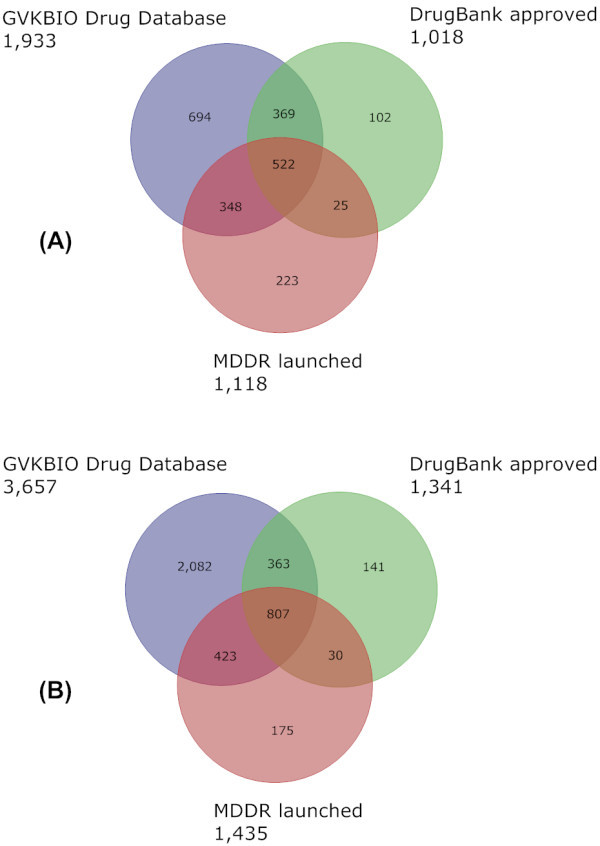
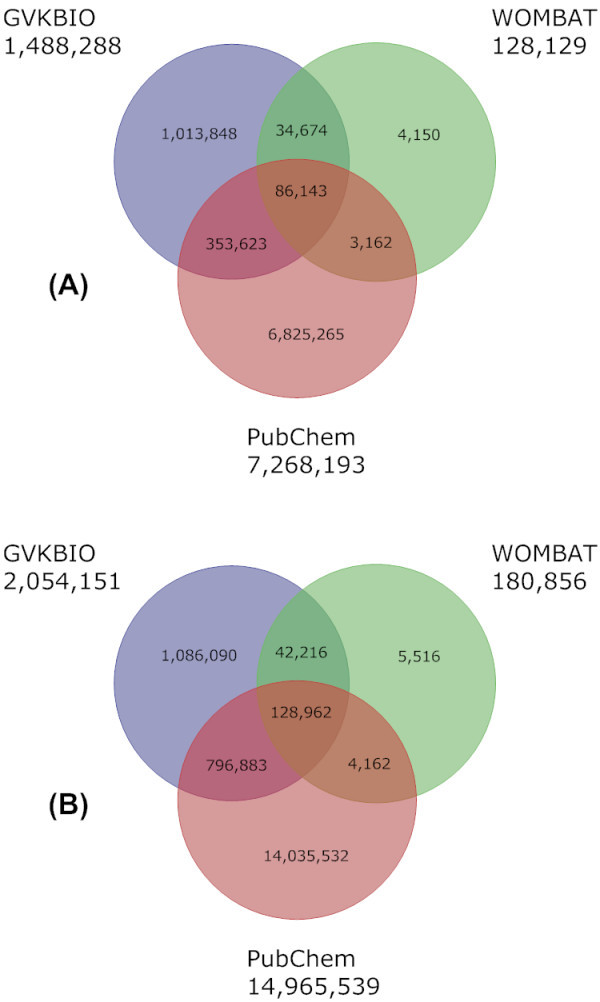
Where they could be calculated, extracted compounds-per-journal article were in the range of 12 to 19 but compound-per-protein counts increased with document numbers. Chemical structure filtration to facilitate standardised comparisons typically reduced source counts by between 5% and 30%. The pair-wise overlaps between 23 databases and subsets were determined, as well as changes between 2006 and 2008. While all compound sets have increased, PubChem has doubled to 14.2 million. The 2008 comparison matrix shows not only overlap but also unique content across all sources. Many of the detailed differences could be attributed to individual strategies for data selection and extraction. While there was a big increase in patent-derived structures entering PubChem since 2006, GVKBIO contains over 0.8 million unique structures from this source. Venn diagrams showed extensive overlap between compounds extracted by independent expert curation from journals by GVKBIO, WOMBAT (both commercial) and BindingDB (public) but each included unique content. In contrast, the approved drug collections from GVKBIO, MDDR (commercial) and DrugBank (public) showed surprisingly low overlap. Aggregating all commercial sources established that while 1 million compounds overlapped with PubChem 1.2 million did not.
On the basis of chemical structure content per se public sources have covered an increasing proportion of commercial databases over the last two years. However, commercial products included in this study provide links between compounds and information from patents and journals at a larger scale than current public efforts. They also continue to capture a significant proportion of unique content. Our results thus demonstrate not only an encouraging overall expansion of data-supported bioactive chemical space but also that both commercial and public sources are complementary for its exploration.
自 2004 年以来,公共化学信息数据库及其用于探索化合物、蛋白质序列、文献和检测数据之间关系的集体功能有了显著的进步。与此同时,从期刊和专利中提取和整理这些关系的商业资源也在不断扩大。这项工作更新了之前对数据库的比较研究,这些数据库是因为它们的生物活性内容、下载的可用性和选择信息子集的便利性而被选中的。
在可以计算的情况下,每篇期刊文章中的提取化合物数量在 12 到 19 之间,但化合物与蛋白质数量的比值随着文献数量的增加而增加。为了便于标准化比较而进行的化学结构过滤通常会使源计数减少 5%到 30%。确定了 23 个数据库和子集之间的两两重叠,以及 2006 年和 2008 年之间的变化。虽然所有化合物集都有所增加,但 PubChem 已经翻了一番,达到 1420 万。2008 年的比较矩阵不仅显示了所有来源之间的重叠,还显示了独特的内容。许多详细的差异可以归因于数据选择和提取的个别策略。虽然自 2006 年以来,专利衍生结构进入 PubChem 的数量大幅增加,但 GVKBIO 包含了超过 80 万种来自这一来源的独特结构。Venn 图显示了 GVKBIO、WOMBAT(均为商业)和 BindingDB(公共)从期刊中由独立专家提取的化合物之间有广泛的重叠,但每个都包含独特的内容。相比之下,GVKBIO、MDDR(商业)和 DrugBank(公共)的批准药物集显示出令人惊讶的低重叠。聚合所有商业来源表明,虽然有 100 万种化合物与 PubChem 1.2 重叠,但仍有 100 万种不重叠。
基于化学结构内容本身,公共来源在过去两年中覆盖了越来越多的商业数据库。然而,本研究中包含的商业产品在更大的范围内提供了化合物与专利和期刊信息之间的联系,这超过了当前公共努力的范围。它们还继续捕获了很大一部分独特的内容。因此,我们的研究结果不仅展示了数据支持的生物活性化学空间的令人鼓舞的整体扩展,还表明商业和公共来源在探索该空间方面是互补的。