Division of Humanities and Social Sciences, California Institute of Technology, Pasadena, CA 91101, USA.
Neuron. 2010 May 27;66(4):585-95. doi: 10.1016/j.neuron.2010.04.016.
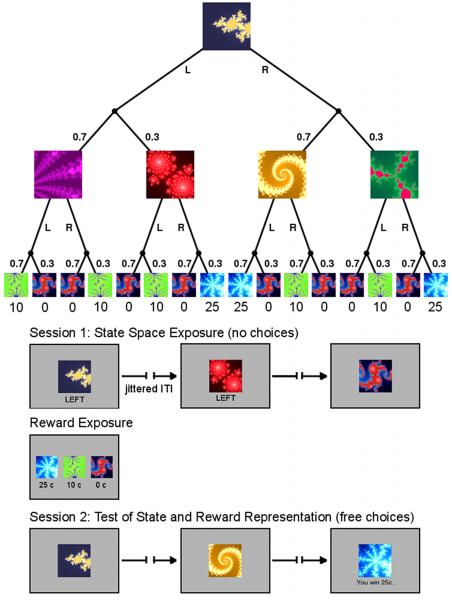
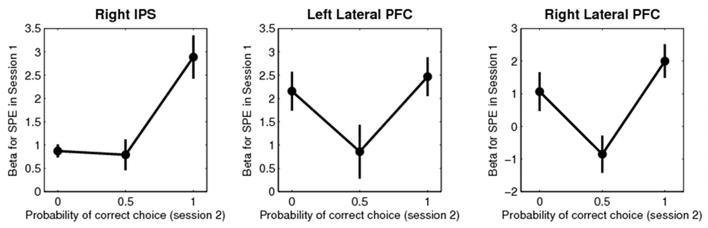
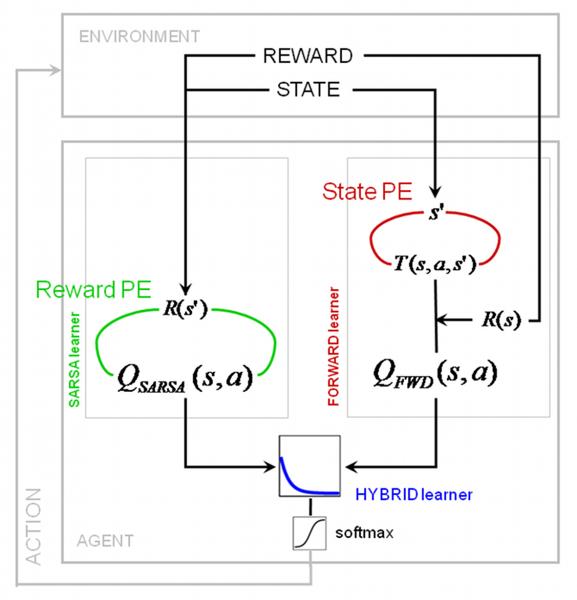
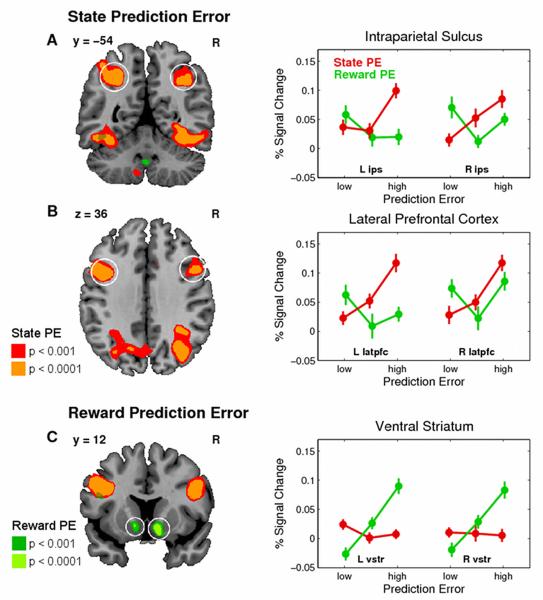
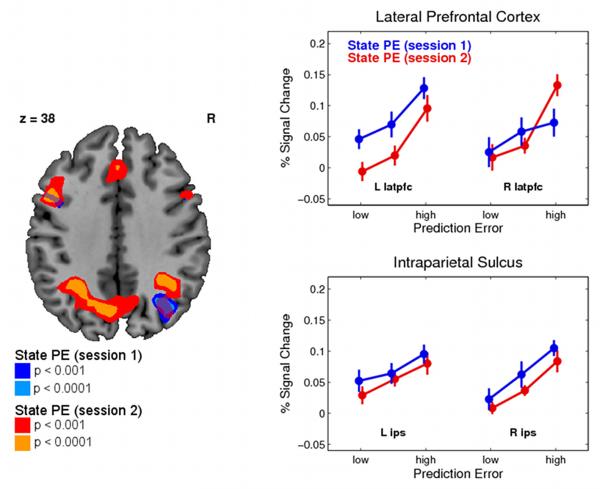
Reinforcement learning (RL) uses sequential experience with situations ("states") and outcomes to assess actions. Whereas model-free RL uses this experience directly, in the form of a reward prediction error (RPE), model-based RL uses it indirectly, building a model of the state transition and outcome structure of the environment, and evaluating actions by searching this model. A state prediction error (SPE) plays a central role, reporting discrepancies between the current model and the observed state transitions. Using functional magnetic resonance imaging in humans solving a probabilistic Markov decision task, we found the neural signature of an SPE in the intraparietal sulcus and lateral prefrontal cortex, in addition to the previously well-characterized RPE in the ventral striatum. This finding supports the existence of two unique forms of learning signal in humans, which may form the basis of distinct computational strategies for guiding behavior.
强化学习 (RL) 使用与情况(“状态”)和结果相关的顺序经验来评估行动。虽然无模型 RL 直接使用这种经验,形式为奖励预测误差 (RPE),但基于模型的 RL 则间接地使用它,构建环境的状态转换和结果结构模型,并通过搜索该模型来评估行动。状态预测误差 (SPE) 起着核心作用,报告当前模型与观察到的状态转换之间的差异。使用人类解决概率马尔可夫决策任务的功能磁共振成像,我们在顶内沟和外侧前额叶皮层中发现了 SPE 的神经特征,除了先前在腹侧纹状体中很好地描述的 RPE 之外。这一发现支持了人类存在两种独特形式的学习信号的假设,这可能是指导行为的不同计算策略的基础。