Centro Nacional de Biotecnología (CNB), CSIC, C/Darwin 3, 28049 Madrid, Spain.
BMC Bioinformatics. 2010 Jun 1;11:294. doi: 10.1186/1471-2105-11-294.
For ecological studies, it is crucial to count on adequate descriptions of the environments and samples being studied. Such a description must be done in terms of their physicochemical characteristics, allowing a direct comparison between different environments that would be difficult to do otherwise. Also the characterization must include the precise geographical location, to make possible the study of geographical distributions and biogeographical patterns. Currently, there is no schema for annotating these environmental features, and these data have to be extracted from textual sources (published articles). So far, this had to be performed by manual inspection of the corresponding documents. To facilitate this task, we have developed EnvMine, a set of text-mining tools devoted to retrieve contextual information (physicochemical variables and geographical locations) from textual sources of any kind.
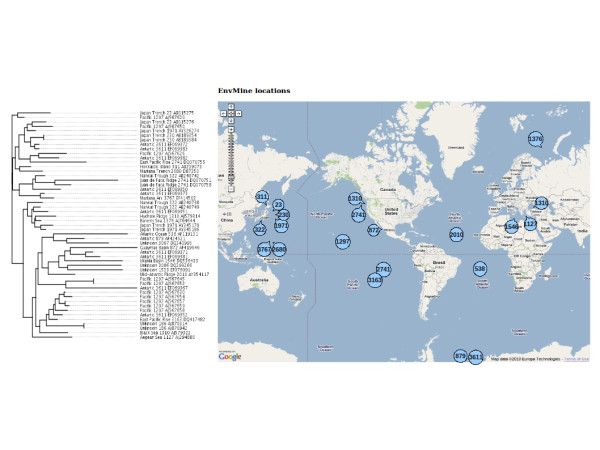
EnvMine is capable of retrieving the physicochemical variables cited in the text, by means of the accurate identification of their associated units of measurement. In this task, the system achieves a recall (percentage of items retrieved) of 92% with less than 1% error. Also a Bayesian classifier was tested for distinguishing parts of the text describing environmental characteristics from others dealing with, for instance, experimental settings.Regarding the identification of geographical locations, the system takes advantage of existing databases such as GeoNames to achieve 86% recall with 92% precision. The identification of a location includes also the determination of its exact coordinates (latitude and longitude), thus allowing the calculation of distance between the individual locations.
EnvMine is a very efficient method for extracting contextual information from different text sources, like published articles or web pages. This tool can help in determining the precise location and physicochemical variables of sampling sites, thus facilitating the performance of ecological analyses. EnvMine can also help in the development of standards for the annotation of environmental features.
对于生态研究,关键是要充分描述所研究的环境和样本。这种描述必须根据其物理化学特性进行,否则很难在不同环境之间进行直接比较。此外,特征描述还必须包括精确的地理位置,以便能够研究地理分布和生物地理模式。目前,还没有用于标注这些环境特征的模式,这些数据必须从文本来源(已发表的文章)中提取。到目前为止,这必须通过手动检查相应的文件来完成。为了方便这项任务,我们开发了 EnvMine,这是一组文本挖掘工具,用于从任何类型的文本来源中检索上下文信息(物理化学变量和地理位置)。
EnvMine 能够通过准确识别其相关的度量单位,检索文本中引用的物理化学变量。在这项任务中,系统的召回率(检索项的百分比)达到 92%,错误率不到 1%。还测试了贝叶斯分类器,用于区分描述环境特征的文本部分和描述实验设置等的文本部分。关于地理位置的识别,系统利用现有数据库(如 GeoNames)实现 86%的召回率和 92%的精度。位置的识别还包括确定其确切坐标(纬度和经度),从而允许计算各个位置之间的距离。
EnvMine 是一种从不同文本来源(如已发表的文章或网页)中提取上下文信息的非常有效的方法。该工具可以帮助确定采样点的确切位置和物理化学变量,从而便于进行生态分析。EnvMine 还可以帮助制定环境特征标注的标准。