Department of Ecology and Evolutionary Biology, University of Connecticut.
Mol Biol Evol. 2011 Jan;28(1):523-32. doi: 10.1093/molbev/msq224. Epub 2010 Aug 27.
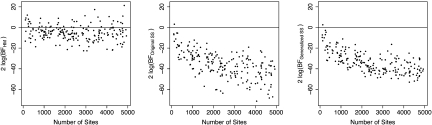
Bayesian phylogenetic analyses often depend on Bayes factors (BFs) to determine the optimal way to partition the data. The marginal likelihoods used to compute BFs, in turn, are most commonly estimated using the harmonic mean (HM) method, which has been shown to be inaccurate. We describe a new more accurate method for estimating the marginal likelihood of a model and compare it with the HM method on both simulated and empirical data. The new method generalizes our previously described stepping-stone (SS) approach by making use of a reference distribution parameterized using samples from the posterior distribution. This avoids one challenging aspect of the original SS method, namely the need to sample from distributions that are close (in the Kullback-Leibler sense) to the prior. We specifically address the choice of partition models and find that using the HM method can lead to a strong preference for an overpartitioned model. In contrast to the HM method and the original SS method, we show using simulated data that the generalized SS method is strikingly more precise (repeatable BF values of the same data and partition model) and yields BF values that are much more reasonable than those produced by the HM method. Comparisons of HM and generalized SS methods on an empirical data set demonstrate that the generalized SS method tends to choose simpler partition schemes that are more in line with expectation based on inferred patterns of molecular evolution. The generalized SS method shares with thermodynamic integration the need to sample from a series of distributions in addition to the posterior. Such dedicated path-based Markov chain Monte Carlo analyses appear to be a cost of estimating marginal likelihoods accurately.
贝叶斯系统发育分析通常依赖贝叶斯因子(BFs)来确定划分数据的最佳方法。用于计算 BFs 的边际似然度,反过来,最常用调和均值(HM)方法进行估计,该方法已被证明不准确。我们描述了一种新的更准确的方法来估计模型的边际似然度,并在模拟和实际数据上比较了 HM 方法。该新方法通过使用基于后验分布样本参数化的参考分布来扩展我们之前描述的步石(SS)方法。这避免了原始 SS 方法的一个具有挑战性的方面,即需要从与先验分布接近(在 Kullback-Leibler 意义上)的分布中进行采样。我们特别针对分区模型的选择,并发现使用 HM 方法可能导致对过度分区模型的强烈偏好。与 HM 方法和原始 SS 方法相比,我们使用模拟数据表明,广义 SS 方法具有惊人的更高精度(相同数据和分区模型的重复 BF 值),并且产生的 BF 值比 HM 方法合理得多。在实际数据集上比较 HM 和广义 SS 方法表明,广义 SS 方法倾向于选择更简单的分区方案,这些方案更符合基于推断的分子进化模式的预期。广义 SS 方法与热力学集成共享,除了后验之外,还需要从一系列分布中进行采样。这种专门的基于路径的马尔可夫链蒙特卡罗分析似乎是准确估计边际似然度的代价。