Department of Electrical and Computer Engineering, University of Alberta, Edmonton, Canada.
Bioinformatics. 2010 Sep 15;26(18):i489-96. doi: 10.1093/bioinformatics/btq373.
Intrinsically disordered proteins play a crucial role in numerous regulatory processes. Their abundance and ubiquity combined with a relatively low quantity of their annotations motivate research toward the development of computational models that predict disordered regions from protein sequences. Although the prediction quality of these methods continues to rise, novel and improved predictors are urgently needed.
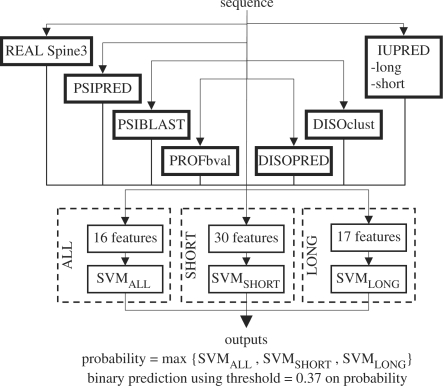
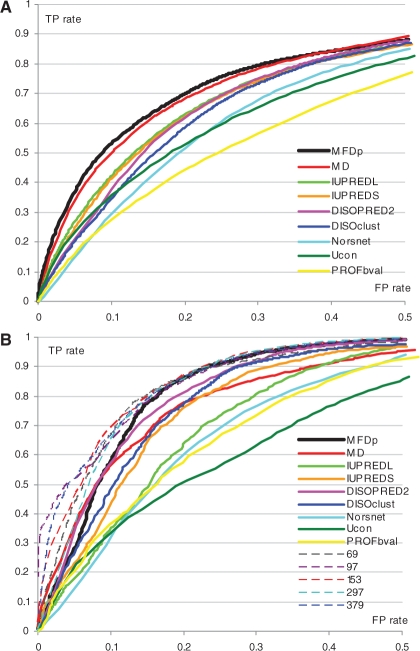
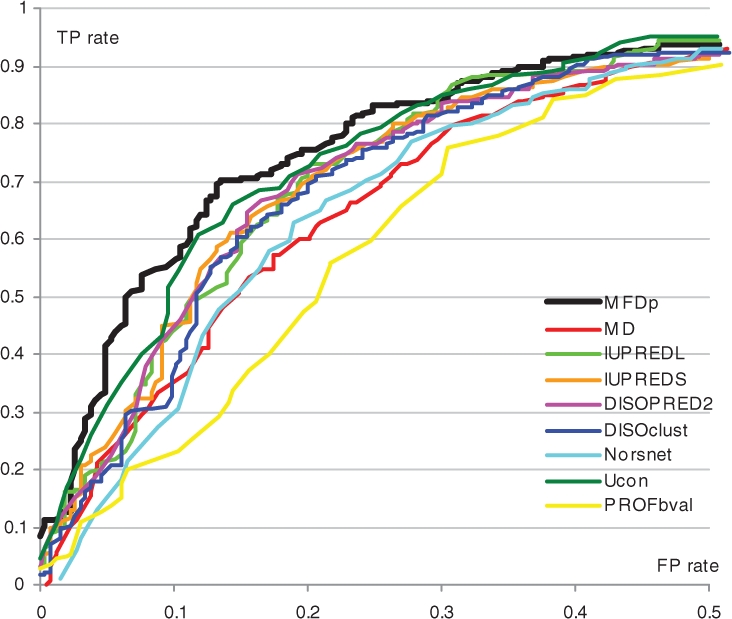
We propose a novel method, named MFDp (Multilayered Fusion-based Disorder predictor), that aims to improve over the current disorder predictors. MFDp is as an ensemble of 3 Support Vector Machines specialized for the prediction of short, long and generic disordered regions. It combines three complementary disorder predictors, sequence, sequence profiles, predicted secondary structure, solvent accessibility, backbone dihedral torsion angles, residue flexibility and B-factors. Our method utilizes a custom-designed set of features that are based on raw predictions and aggregated raw values and recognizes various types of disorder. The MFDp is compared at the residue level on two datasets against eight recent disorder predictors and top-performing methods from the most recent CASP8 experiment. In spite of using training chains with <or=25% similarity to the test sequences, our method consistently and significantly outperforms the other methods based on the MCC index. The MFDp outperforms modern disorder predictors for the binary disorder assignment and provides competitive real-valued predictions. The MFDp's outputs are also shown to outperform the other methods in the identification of proteins with long disordered regions.
无序蛋白质在许多调节过程中起着至关重要的作用。它们的丰富度和普遍性,加上它们的注释相对较少,这促使人们研究开发能够从蛋白质序列中预测无序区域的计算模型。尽管这些方法的预测质量不断提高,但迫切需要新的和改进的预测器。
我们提出了一种名为 MFDp(基于多层融合的无序预测器)的新方法,旨在改进现有的无序预测器。MFDp 是由 3 个专门用于预测短、长和通用无序区域的支持向量机构成的集成。它结合了三种互补的无序预测器,序列、序列图谱、预测的二级结构、溶剂可及性、骨架二面角扭转角、残基柔性和 B 因子。我们的方法利用了一组基于原始预测和聚合原始值的定制特征,识别各种类型的无序。在两个数据集上,我们在残基水平上与 8 种最新的无序预测器和最近的 CASP8 实验中的顶级方法进行了比较。尽管使用的训练链与测试序列的相似度<或=25%,但我们的方法基于 MCC 指数始终显著优于其他方法。MFDp 在二值无序分配方面优于现代无序预测器,并提供有竞争力的实值预测。MFDp 的输出在识别具有长无序区域的蛋白质方面也表现优于其他方法。