Biomedical Informatics Training Program, Stanford University School of Medicine, Stanford, CA, USA.
BMC Bioinformatics. 2010 Oct 28;11 Suppl 9(Suppl 9):S9. doi: 10.1186/1471-2105-11-S9-S9.
A key challenge in pharmacogenomics is the identification of genes whose variants contribute to drug response phenotypes, which can include severe adverse effects. Pharmacogenomics GWAS attempt to elucidate genotypes predictive of drug response. However, the size of these studies has severely limited their power and potential application. We propose a novel knowledge integration and SNP aggregation approach for identifying genes impacting drug response. Our SNP aggregation method characterizes the degree to which uncommon alleles of a gene are associated with drug response. We first use pre-existing knowledge sources to rank pharmacogenes by their likelihood to affect drug response. We then define a summary score for each gene based on allele frequencies and train linear and logistic regression classifiers to predict drug response phenotypes.
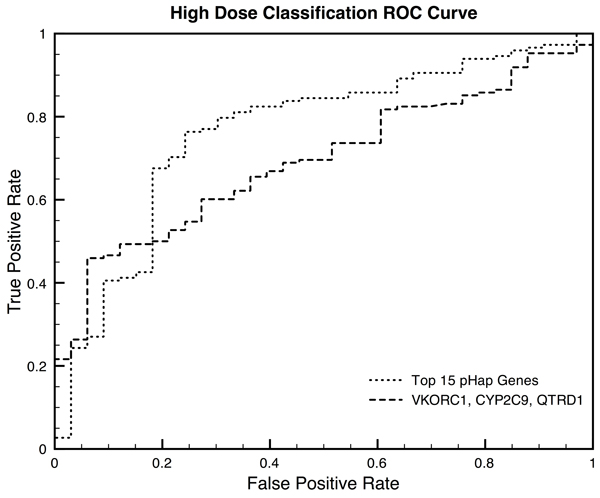
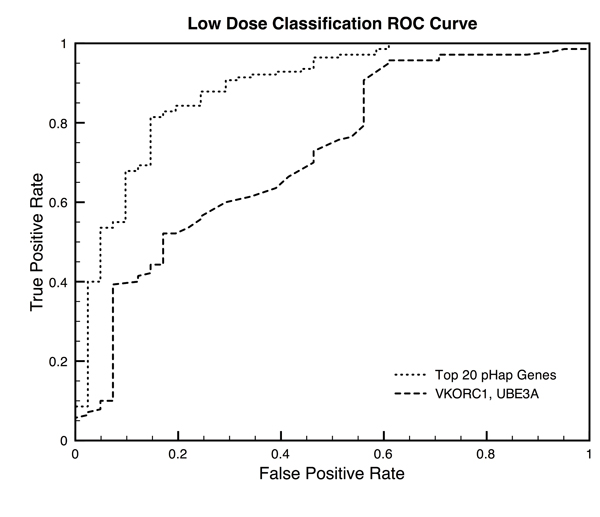
We applied our method to a published warfarin GWAS data set comprising 181 individuals. We find that our method can increase the power of the GWAS to identify both VKORC1 and CYP2C9 as warfarin pharmacogenes, where the original analysis had only identified VKORC1. Additionally, we find that our method can be used to discriminate between low-dose (AUROC=0.886) and high-dose (AUROC=0.764) responders.
Our method offers a new route for candidate pharmacogene discovery from pharmacogenomics GWAS, and serves as a foundation for future work in methods for predictive pharmacogenomics.
药物基因组学的一个关键挑战是确定导致药物反应表型(包括严重不良反应)的基因变体。药物基因组学 GWAS 试图阐明预测药物反应的基因型。然而,这些研究的规模严重限制了它们的能力和潜在应用。我们提出了一种新的知识整合和 SNP 聚合方法,用于识别影响药物反应的基因。我们的 SNP 聚合方法表征了一个基因的罕见等位基因与药物反应之间的关联程度。我们首先使用现有的知识库按影响药物反应的可能性对药物基因进行排序。然后,我们根据等位基因频率为每个基因定义一个综合评分,并训练线性和逻辑回归分类器来预测药物反应表型。
我们将我们的方法应用于一个包含 181 个人的已发表的华法林 GWAS 数据集。我们发现,我们的方法可以提高 GWAS 识别华法林药物基因 VKORC1 和 CYP2C9 的能力,而原始分析仅识别出 VKORC1。此外,我们发现我们的方法可用于区分低剂量(AUROC=0.886)和高剂量(AUROC=0.764)反应者。
我们的方法为从药物基因组学 GWAS 中发现候选药物基因提供了一条新途径,并为预测药物基因组学的未来工作奠定了基础。