National Center for Biotechnology Information, US National Library of Medicine, 8600 Rockville Pike, Bethesda, MD 20894, USA.
BMC Bioinformatics. 2010 Nov 8;11:549. doi: 10.1186/1471-2105-11-549.
In recent years, the number of High Throughput Screening (HTS) assays deposited in PubChem has grown quickly. As a result, the volume of both the structured information (i.e. molecular structure, bioactivities) and the unstructured information (such as descriptions of bioassay experiments), has been increasing exponentially. As a result, it has become even more demanding and challenging to efficiently assemble the bioactivity data by mining the huge amount of information to identify and interpret the relationships among the diversified bioassay experiments. In this work, we propose a text-mining based approach for bioassay neighboring analysis from the unstructured text descriptions contained in the PubChem BioAssay database.
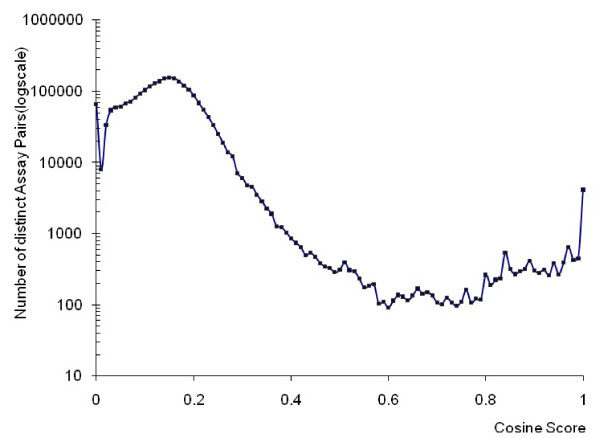
The neighboring analysis is achieved by evaluating the cosine scores of each bioassay pair and fraction of overlaps among the human-curated neighbors. Our results from the cosine score distribution analysis and assay neighbor clustering analysis on all PubChem bioassays suggest that strong correlations among the bioassays can be identified from their conceptual relevance. A comparison with other existing assay neighboring methods suggests that the text-mining based bioassay neighboring approach provides meaningful linkages among the PubChem bioassays, and complements the existing methods by identifying additional relationships among the bioassay entries.
The text-mining based bioassay neighboring analysis is efficient for correlating bioassays and studying different aspects of a biological process, which are otherwise difficult to achieve by existing neighboring procedures due to the lack of specific annotations and structured information. It is suggested that the text-mining based bioassay neighboring analysis can be used as a standalone or as a complementary tool for the PubChem bioassay neighboring process to enable efficient integration of assay results and generate hypotheses for the discovery of bioactivities of the tested reagents.
近年来,PubChem 中储存的高通量筛选 (HTS) 测定数量迅速增加。结果,无论是结构化信息(即分子结构、生物活性)还是非结构化信息(例如生物测定实验的描述)的数量都呈指数级增长。因此,通过挖掘大量信息来有效地组合生物活性数据,以识别和解释多样化的生物测定实验之间的关系,变得更加苛刻和具有挑战性。在这项工作中,我们提出了一种基于文本挖掘的方法,用于从 PubChem BioAssay 数据库中包含的非结构化文本描述中进行生物测定邻域分析。
通过评估每个生物测定对的余弦得分以及人工策邻居之间的重叠部分分数,实现了邻域分析。我们对所有 PubChem 生物测定的余弦得分分布分析和测定邻居聚类分析的结果表明,可以从概念相关性识别出生物测定之间的强相关性。与其他现有测定邻域方法的比较表明,基于文本挖掘的生物测定邻域分析为 PubChem 生物测定之间提供了有意义的联系,并通过识别生物测定条目中的其他关系来补充现有方法。
基于文本挖掘的生物测定邻域分析可有效地关联生物测定并研究生物过程的不同方面,由于缺乏特定的注释和结构化信息,现有邻域程序很难实现这一点。建议基于文本挖掘的生物测定邻域分析可作为 PubChem 生物测定邻域处理的独立或补充工具,以实现测定结果的有效整合,并为测试试剂的生物活性发现生成假设。