Department of Computer Science, University of Toronto, 10 Kings College Road, Toronto, Ontario M5S3G4, Canada.
BMC Bioinformatics. 2010 Nov 15;11:562. doi: 10.1186/1471-2105-11-562.
Semantic similarity measures are useful to assess the physiological relevance of protein-protein interactions (PPIs). They quantify similarity between proteins based on their function using annotation systems like the Gene Ontology (GO). Proteins that interact in the cell are likely to be in similar locations or involved in similar biological processes compared to proteins that do not interact. Thus the more semantically similar the gene function annotations are among the interacting proteins, more likely the interaction is physiologically relevant. However, most semantic similarity measures used for PPI confidence assessment do not consider the unequal depth of term hierarchies in different classes of cellular location, molecular function, and biological process ontologies of GO and thus may over-or under-estimate similarity.
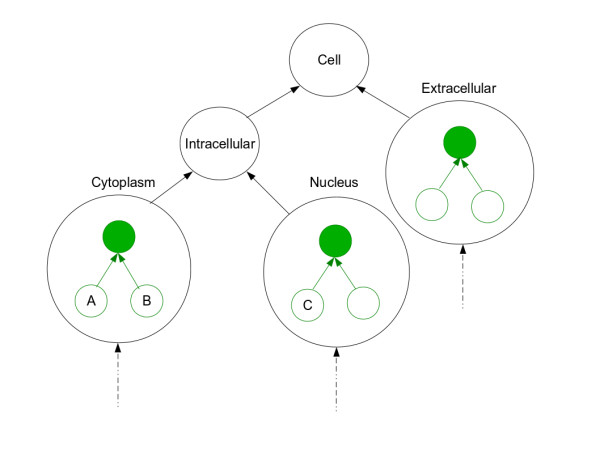
We describe an improved algorithm, Topological Clustering Semantic Similarity (TCSS), to compute semantic similarity between GO terms annotated to proteins in interaction datasets. Our algorithm, considers unequal depth of biological knowledge representation in different branches of the GO graph. The central idea is to divide the GO graph into sub-graphs and score PPIs higher if participating proteins belong to the same sub-graph as compared to if they belong to different sub-graphs.
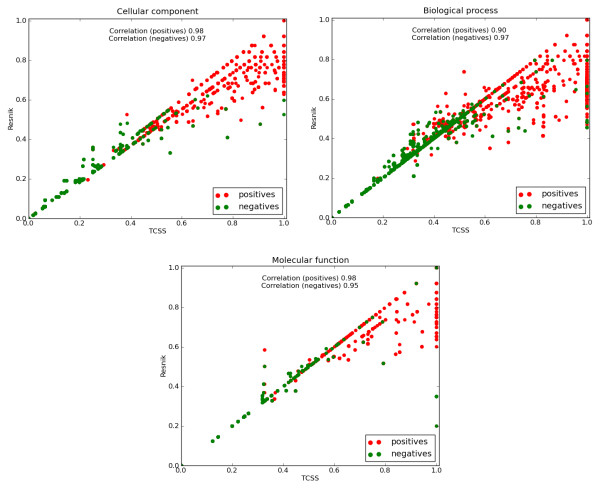
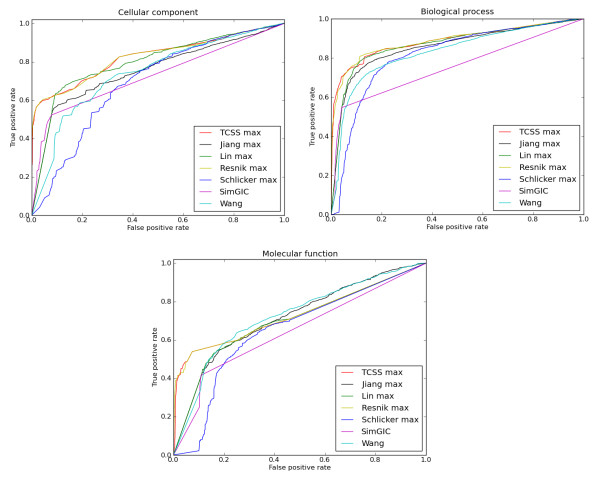
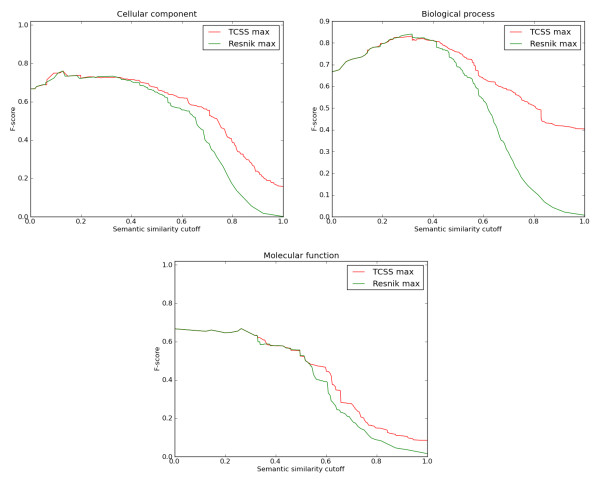
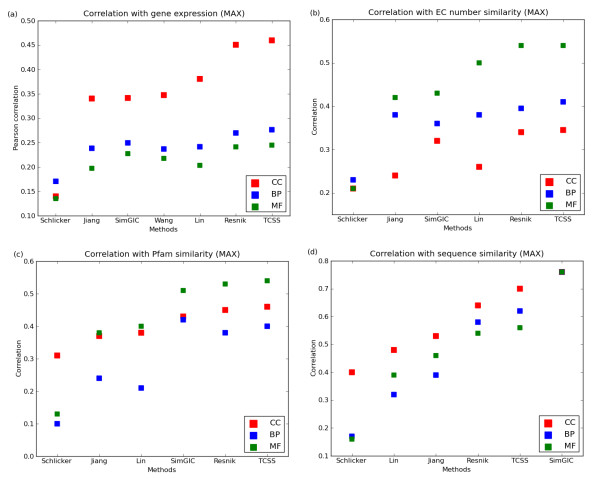
The TCSS algorithm performs better than other semantic similarity measurement techniques that we evaluated in terms of their performance on distinguishing true from false protein interactions, and correlation with gene expression and protein families. We show an average improvement of 4.6 times the F1 score over Resnik, the next best method, on our Saccharomyces cerevisiae PPI dataset and 2 times on our Homo sapiens PPI dataset using cellular component, biological process and molecular function GO annotations.
语义相似性度量对于评估蛋白质-蛋白质相互作用(PPIs)的生理相关性非常有用。它们基于注释系统(如基因本体论(GO))根据蛋白质的功能对蛋白质进行相似性量化。与不相互作用的蛋白质相比,在细胞中相互作用的蛋白质可能处于相似的位置或参与相似的生物过程。因此,相互作用蛋白的基因功能注释之间的语义相似性越高,相互作用就越具有生理相关性。然而,用于 PPI 置信度评估的大多数语义相似性度量并未考虑 GO 中细胞位置、分子功能和生物过程本体不同类别的术语层次结构的不等深度,因此可能会高估或低估相似性。
我们描述了一种改进的算法,拓扑聚类语义相似性(TCSS),用于计算交互数据集中标注蛋白质的 GO 术语之间的语义相似性。我们的算法考虑了 GO 图不同分支中生物知识表示的不等深度。核心思想是将 GO 图划分为子图,如果参与蛋白质属于同一子图,则将其划分为子图,而不是不同的子图。
与我们评估的其他语义相似性测量技术相比,TCSS 算法在区分真实和虚假蛋白质相互作用以及与基因表达和蛋白质家族的相关性方面表现更好。我们在酿酒酵母 PPI 数据集上使用细胞成分、生物过程和分子功能 GO 注释,将 Resnik(下一个最佳方法)的 F1 得分提高了 4.6 倍,在人类 PPI 数据集上提高了 2 倍。