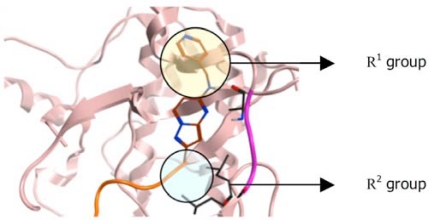
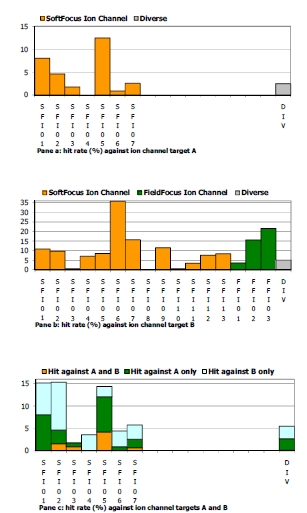
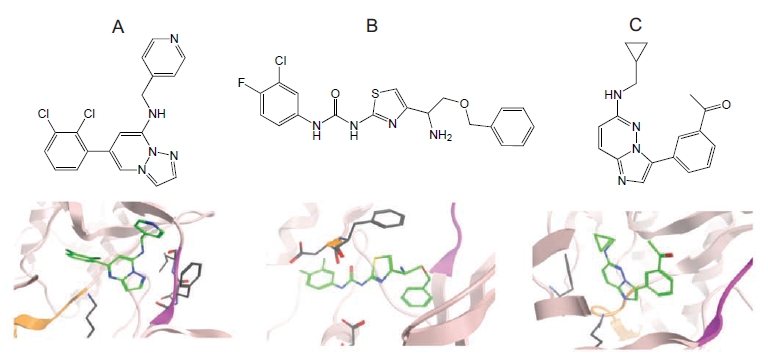
Harris C John, Hill Richard D, Sheppard David W, Slater Martin J, Stouten Pieter F W
BioFocus, Chesterford Research Park, CB10 1XL, UK.
Comb Chem High Throughput Screen. 2011 Jul;14(6):521-31. doi: 10.2174/138620711795767802.
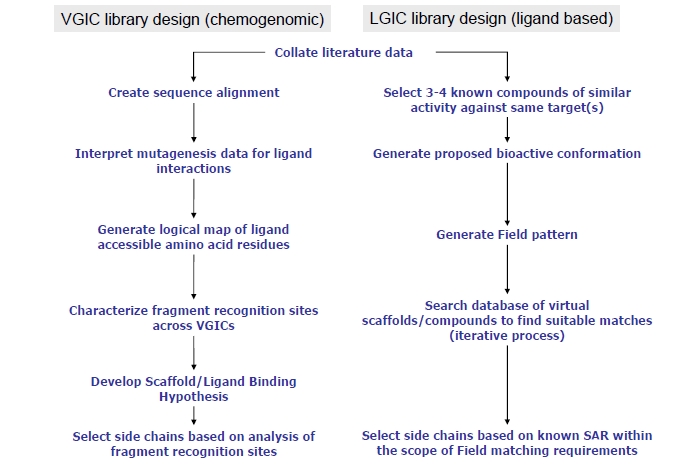
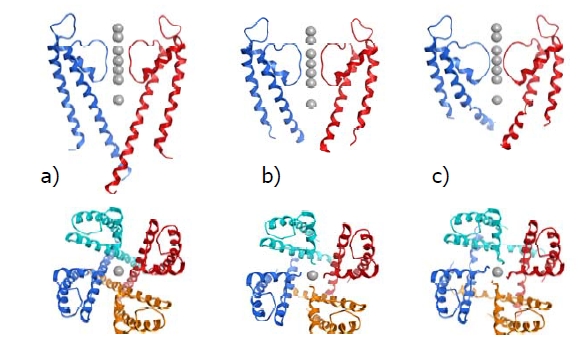
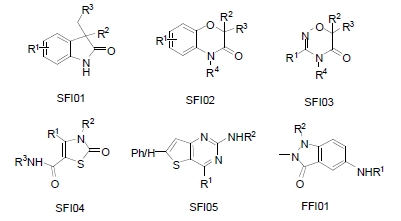
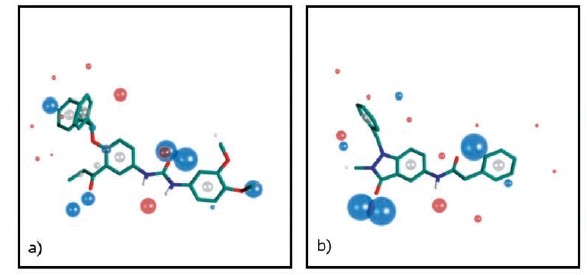
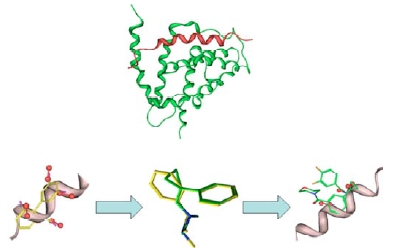
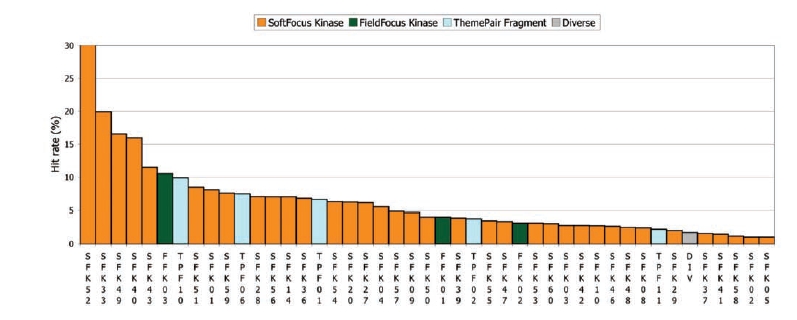
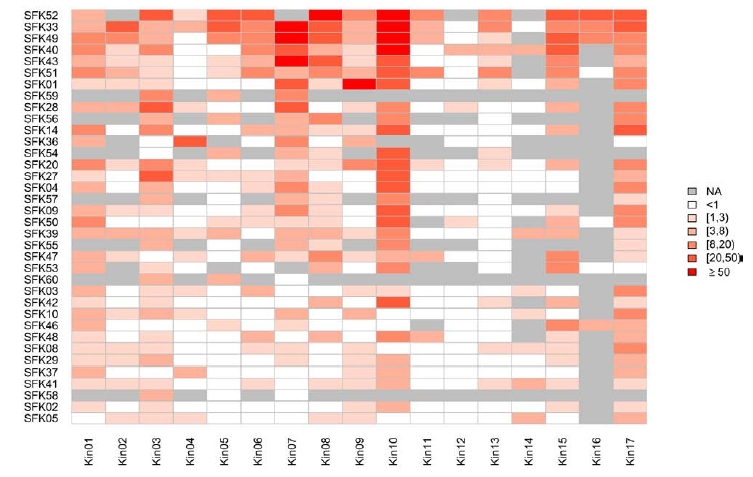
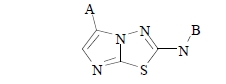
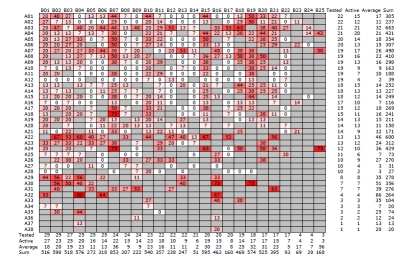
Target-focused compound libraries are collections of compounds which are designed to interact with an individual protein target or, frequently, a family of related targets (such as kinases, voltage-gated ion channels, serine/cysteine proteases). They are used for screening against therapeutic targets in order to find hit compounds that might be further developed into drugs. The design of such libraries generally utilizes structural information about the target or family of interest. In the absence of such structural information, a chemogenomic model that incorporates sequence and mutagenesis data to predict the properties of the binding site can be employed. A third option, usually pursued when no structural data are available, utilizes knowledge of the ligands of the target from which focused libraries can be developed via scaffold hopping. Consequently, the methods used for the design of target-focused libraries vary according to the quantity and quality of structural or ligand data that is available for each target family. This article describes examples of each of these design approaches and illustrates them with case studies, which highlight some of the issues and successes observed when screening target-focused libraries.
靶向化合物库是一类化合物的集合,其设计目的是与单个蛋白质靶点相互作用,或者更常见的是与一组相关靶点(如激酶、电压门控离子通道、丝氨酸/半胱氨酸蛋白酶)相互作用。它们用于针对治疗靶点进行筛选,以找到可能进一步开发成药物的活性化合物。此类文库的设计通常利用有关目标靶点或目标靶点家族的结构信息。在缺乏此类结构信息的情况下,可以采用一种化学基因组模型,该模型结合序列和诱变数据来预测结合位点的性质。第三种选择通常在没有结构数据时采用,它利用目标靶点配体的知识,通过骨架跃迁开发聚焦文库。因此,用于设计靶向化合物库的方法会根据每个靶点家族可获得的结构或配体数据的数量和质量而有所不同。本文描述了每种设计方法的示例,并通过案例研究进行说明,这些案例突出了在筛选靶向化合物库时观察到的一些问题和成功之处。