INRIA Grenoble-Rhône-Alpes, Montbonnot, France.
Bioinformatics. 2011 Jul 1;27(13):i186-95. doi: 10.1093/bioinformatics/btr225.
High-throughput measurement techniques for metabolism and gene expression provide a wealth of information for the identification of metabolic network models. Yet, missing observations scattered over the dataset restrict the number of effectively available datapoints and make classical regression techniques inaccurate or inapplicable. Thorough exploitation of the data by identification techniques that explicitly cope with missing observations is therefore of major importance.
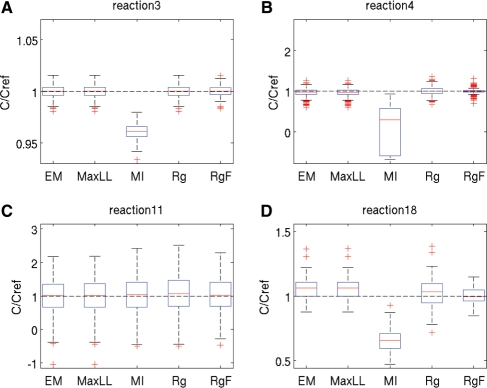
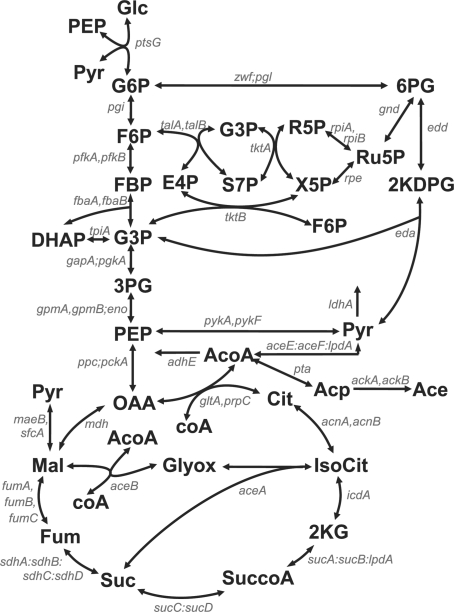
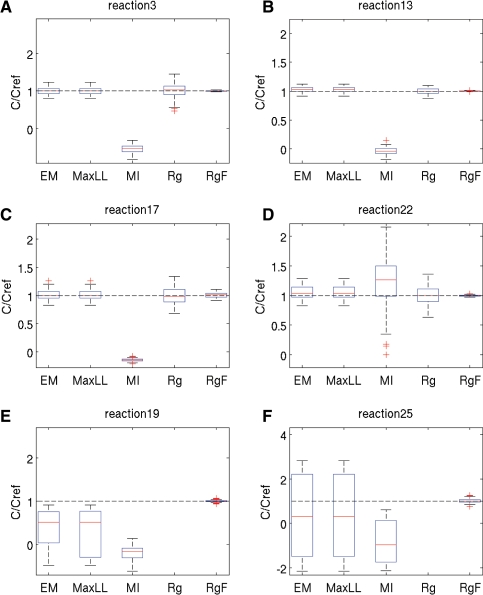
We develop a maximum-likelihood approach for the estimation of unknown parameters of metabolic network models that relies on the integration of statistical priors to compensate for the missing data. In the context of the linlog metabolic modeling framework, we implement the identification method by an Expectation-Maximization (EM) algorithm and by a simpler direct numerical optimization method. We evaluate performance of our methods by comparison to existing approaches, and show that our EM method provides the best results over a variety of simulated scenarios. We then apply the EM algorithm to a real problem, the identification of a model for the Escherichia coli central carbon metabolism, based on challenging experimental data from the literature. This leads to promising results and allows us to highlight critical identification issues.
高通量测量技术可用于代谢和基因表达,为代谢网络模型的识别提供了丰富的信息。然而,数据集上分散的缺失观测值限制了有效可用数据点的数量,使得经典回归技术不准确或不适用。因此,通过显式处理缺失观测值的识别技术对数据进行彻底的利用非常重要。
我们开发了一种最大似然方法来估计代谢网络模型的未知参数,该方法依赖于统计先验的整合来补偿缺失数据。在 linlog 代谢建模框架的背景下,我们通过期望最大化(EM)算法和更简单的直接数值优化方法来实现识别方法。我们通过与现有方法进行比较来评估我们方法的性能,并表明我们的 EM 方法在各种模拟场景下提供了最佳结果。然后,我们将 EM 算法应用于一个实际问题,即根据文献中具有挑战性的实验数据识别大肠杆菌中心碳代谢模型。这带来了有希望的结果,并使我们能够突出关键的识别问题。