Wang Yong-Cui, Wang Yong, Yang Zhi-Xia, Deng Nai-Yang
College of Mathematics and System Science, Xinjiang University, Urumuchi, China.
BMC Syst Biol. 2011 Jun 20;5 Suppl 1(Suppl 1):S6. doi: 10.1186/1752-0509-5-S1-S6.
Enzymes are known as the largest class of proteins and their functions are usually annotated by the Enzyme Commission (EC), which uses a hierarchy structure, i.e., four numbers separated by periods, to classify the function of enzymes. Automatically categorizing enzyme into the EC hierarchy is crucial to understand its specific molecular mechanism.
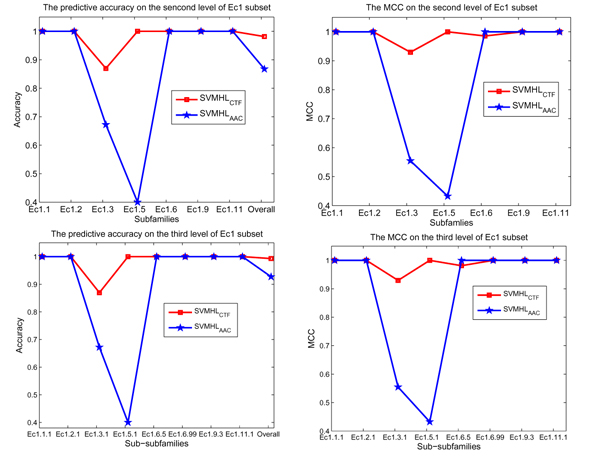
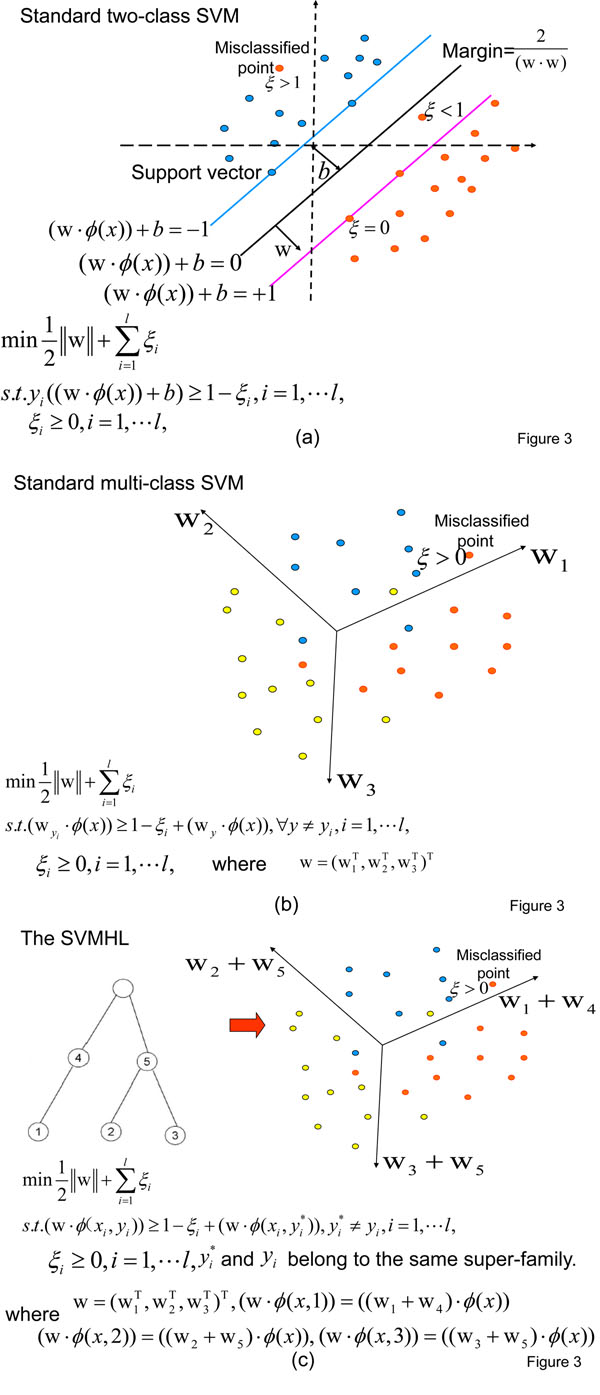
In this paper, we introduce two key improvements in predicting enzyme function within the machine learning framework. One is to introduce the efficient sequence encoding methods for representing given proteins. The second one is to develop a structure-based prediction method with low computational complexity. In particular, we propose to use the conjoint triad feature (CTF) to represent the given protein sequences by considering not only the composition of amino acids but also the neighbor relationships in the sequence. Then we develop a support vector machine (SVM)-based method, named as SVMHL (SVM for hierarchy labels), to output enzyme function by fully considering the hierarchical structure of EC. The experimental results show that our SVMHL with the CTF outperforms SVMHL with the amino acid composition (AAC) feature both in predictive accuracy and Matthew's correlation coefficient (MCC). In addition, SVMHL with the CTF obtains the accuracy and MCC ranging from 81% to 98% and 0.82 to 0.98 when predicting the first three EC digits on a low-homologous enzyme dataset. We further demonstrate that our method outperforms the methods which do not take account of hierarchical relationship among enzyme categories and alternative methods which incorporate prior knowledge about inter-class relationships.
Our structure-based prediction model, SVMHL with the CTF, reduces the computational complexity and outperforms the alternative approaches in enzyme function prediction. Therefore our new method will be a useful tool for enzyme function prediction community.
酶是已知最大的蛋白质类别,其功能通常由酶委员会(EC)注释,该委员会使用层次结构,即由句点分隔的四个数字,对酶的功能进行分类。将酶自动分类到EC层次结构中对于理解其特定分子机制至关重要。
在本文中,我们介绍了机器学习框架内预测酶功能的两项关键改进。一是引入用于表示给定蛋白质的高效序列编码方法。二是开发一种计算复杂度低的基于结构的预测方法。特别是,我们提出使用联合三联体特征(CTF)来表示给定的蛋白质序列,不仅考虑氨基酸组成,还考虑序列中的相邻关系。然后我们开发了一种基于支持向量机(SVM)的方法,名为SVMHL(用于层次标签的SVM),通过充分考虑EC的层次结构来输出酶功能。实验结果表明,我们带有CTF的SVMHL在预测准确性和马修斯相关系数(MCC)方面均优于带有氨基酸组成(AAC)特征的SVMHL。此外,在低同源酶数据集上预测前三个EC数字时,带有CTF的SVMHL的准确率和MCC范围分别为81%至98%和0.82至0.98。我们进一步证明,我们的方法优于不考虑酶类别之间层次关系的方法以及纳入类间关系先验知识的替代方法。
我们基于结构的预测模型,即带有CTF的SVMHL,降低了计算复杂度,并且在酶功能预测方面优于替代方法。因此,我们的新方法将成为酶功能预测领域的一个有用工具。