Department of Statistics, Federal University of Minas Gerais, Belo Horizonte, Minas Gerais, Brazil.
BMC Med Res Methodol. 2011 Jun 26;11:99. doi: 10.1186/1471-2288-11-99.
Longitudinal studies often employ complex sample designs to optimize sample size, over-representing population groups of interest. The effect of sample design on parameter estimates is quite often ignored, particularly when fitting survival models. Another major problem in long-term cohort studies is the potential bias due to loss to follow-up.
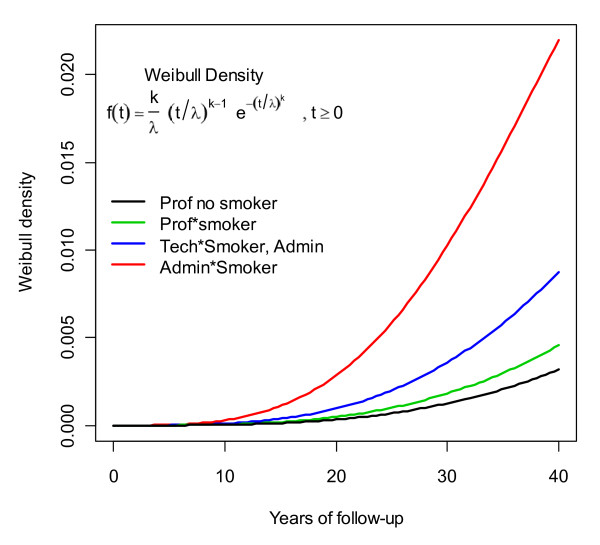
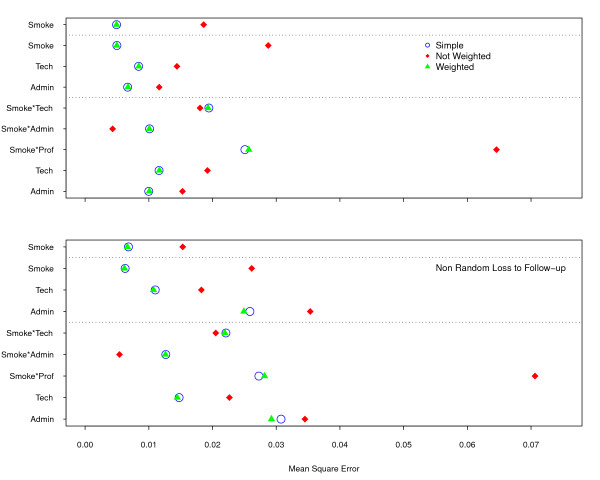
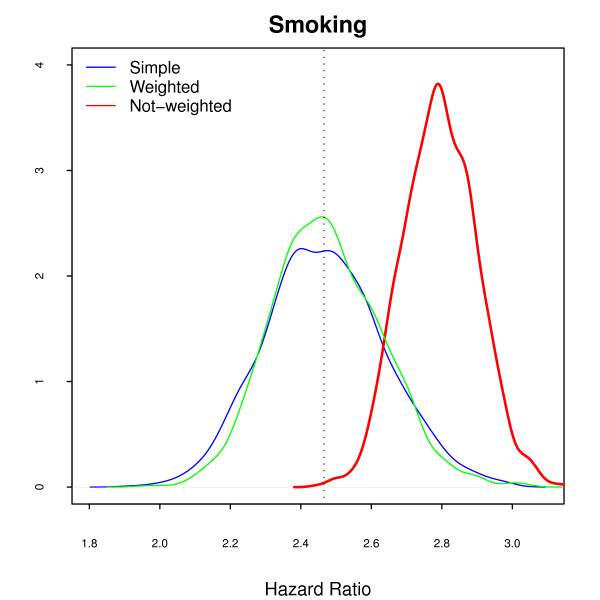
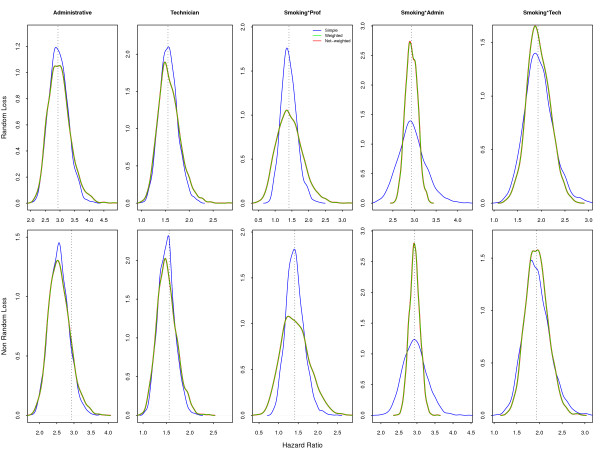
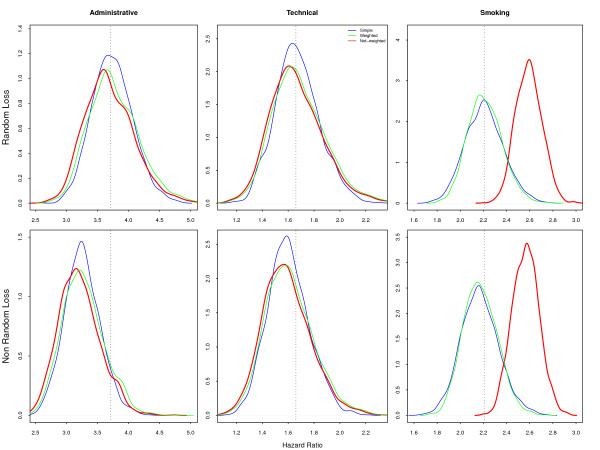
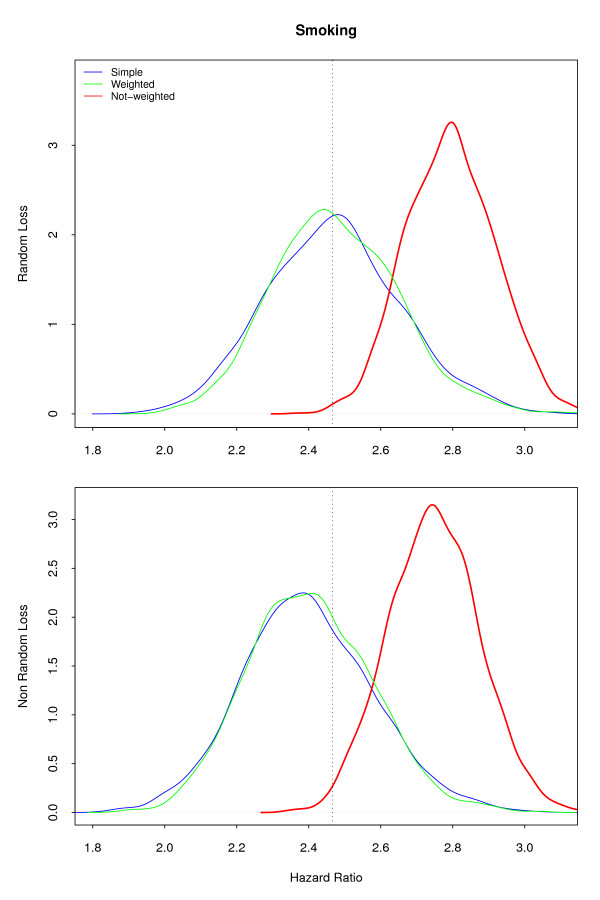
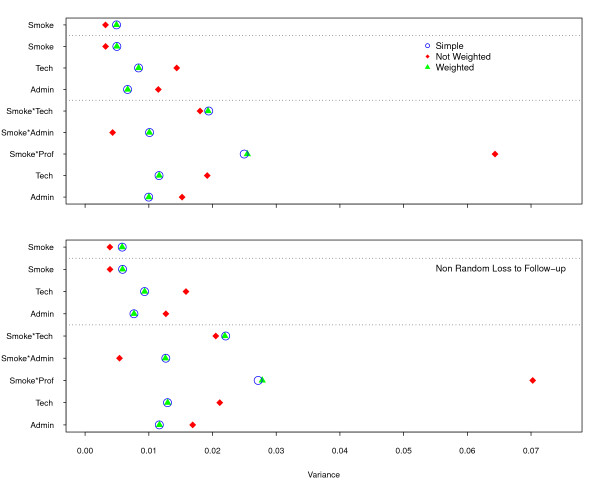
In this paper we simulated a dataset with approximately 50,000 individuals as the target population and 15,000 participants to be followed up for 40 years, both based on real cohort studies of cardiovascular diseases. Two sample strategies--simple random (our golden standard) and Stratified by professional group, with non-proportional allocation--and two loss to follow-up scenarios--non-informative censoring and losses related to the professional group--were analyzed.
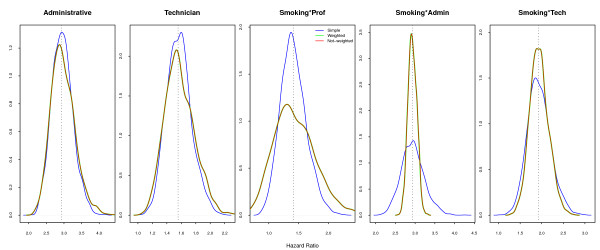
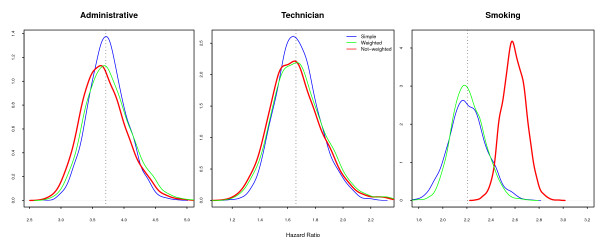
Two modeling approaches were evaluated: weighted and non-weighted fit. Our results indicate that under the correctly specified model, ignoring the sample weights does not affect the results. However, the model ignoring the interaction of sample strata with the variable of interest and the crude estimates were highly biased.
In epidemiological studies misspecification should always be considered, as different sources of variability, related to the individuals and not captured by the covariates, are always present. Therefore, allowance must be made for the possibility of unknown confounders and interactions with the main variable of interest in our data. It is strongly recommended always to correct by sample weights.
纵向研究通常采用复杂的样本设计来优化样本量,从而过度代表感兴趣的人群。样本设计对参数估计的影响往往被忽视,尤其是在拟合生存模型时。长期队列研究中的另一个主要问题是由于随访丢失而导致的潜在偏差。
在本文中,我们模拟了一个数据集,目标人群约为 50000 人,15000 人将在 40 年内进行随访,这两个数据均基于心血管疾病的真实队列研究。分析了两种样本策略:简单随机(我们的黄金标准)和按专业群体分层,非比例分配,以及两种随访丢失情况:无信息删失和与专业群体相关的丢失。
评估了两种建模方法:加权和非加权拟合。我们的结果表明,在正确指定的模型下,忽略样本权重不会影响结果。但是,忽略样本分层与感兴趣变量的交互以及未加权的估计值存在高度偏差。
在流行病学研究中,应始终考虑模型的不正确指定,因为总是存在与个体相关且未被协变量捕获的不同来源的变异性。因此,必须考虑到我们数据中未知混杂因素和与主要感兴趣变量的交互的可能性。强烈建议始终通过样本权重进行校正。