Department of Ocean Sciences, University of California, Santa Cruz, CA 95064, USA.
Nucleic Acids Res. 2011 Nov 1;39(20):8792-802. doi: 10.1093/nar/gkr576. Epub 2011 Jul 19.
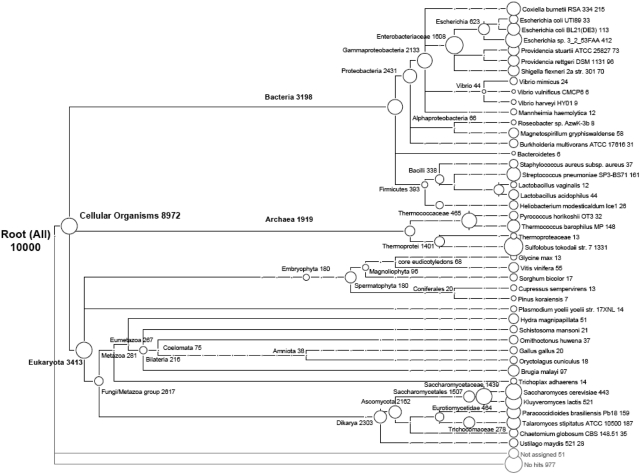
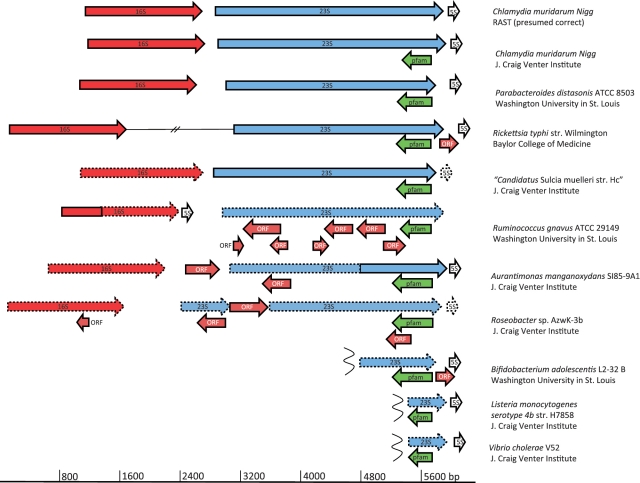
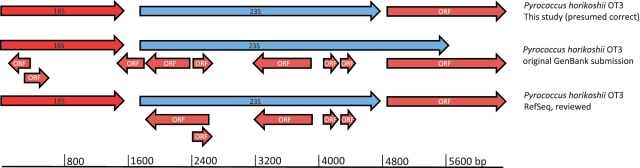
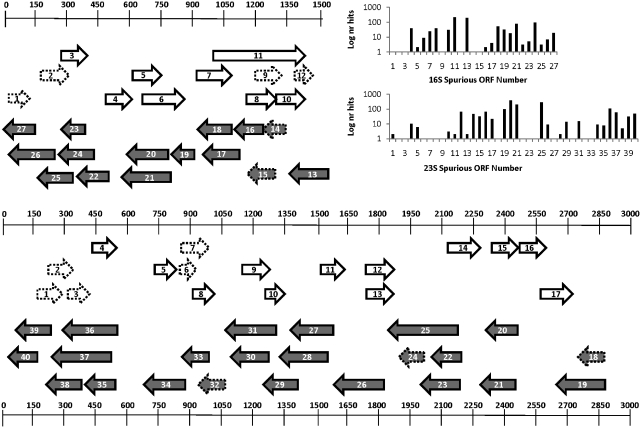
In the course of analyzing 9,522,746 pyrosequencing reads from 23 stations in the Southwestern Pacific and equatorial Atlantic oceans, it came to our attention that misannotations of rRNA as proteins is now so widespread that false positive matching of rRNA pyrosequencing reads to the National Center for Biotechnology Information (NCBI) non-redundant protein database approaches 90%. One conserved portion of 23S rRNA was consistently misannotated often enough to prompt curators at Pfam to create a spurious protein family. Detailed examination of the annotation history of each seed sequence in the spurious Pfam protein family (PF10695, 'Cw-hydrolase') uncovered issues in the standard operating procedures and quality assurance programs of major sequencing centers, and other issues relating to the curation practices of those managing public databases such as GenBank and SwissProt. We offer recommendations for all these issues, and recommend as well that workers in the field of metatranscriptomics take extra care to avoid including false positive matches in their datasets.
在分析来自西南太平洋和赤道大西洋 23 个站位的 9522746 个焦磷酸测序读数的过程中,我们注意到 rRNA 被错误注释为蛋白质的情况现在非常普遍,以至于 rRNA 焦磷酸测序读数与国家生物技术信息中心(NCBI)非冗余蛋白质数据库的假阳性匹配率接近 90%。23S rRNA 的一个保守部分经常被错误注释,以至于 Pfam 的策展人创建了一个虚假的蛋白质家族。详细检查虚假 Pfam 蛋白质家族(PF10695,“Cw-水解酶”)中每个种子序列的注释历史,揭示了主要测序中心的标准操作程序和质量保证计划中的问题,以及与管理公共数据库(如 GenBank 和 SwissProt)的策展实践相关的其他问题。我们针对所有这些问题提出了建议,并建议从事宏转录组学领域的工作人员格外小心,避免在其数据集中包含假阳性匹配。