Institut für Biologie, Theoretische Biophysik, Humboldt-Universität zu Berlin, Invalidenstrasse 42, Berlin, Germany.
Mol Syst Biol. 2011 Jul 19;7:512. doi: 10.1038/msb.2011.41.
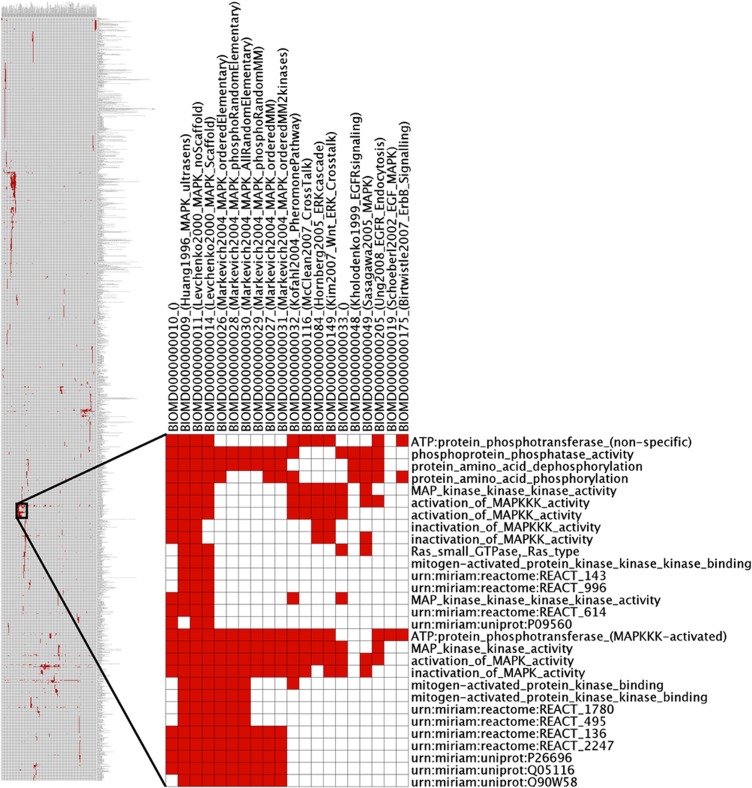
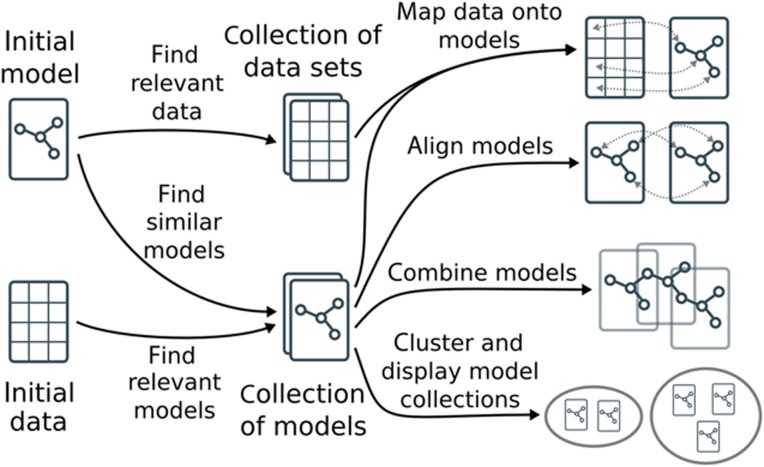
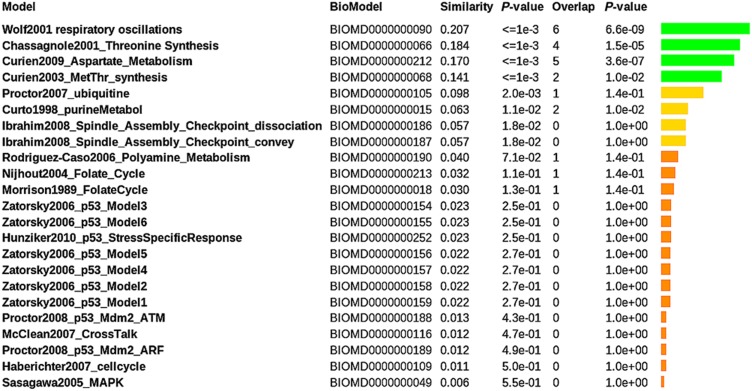
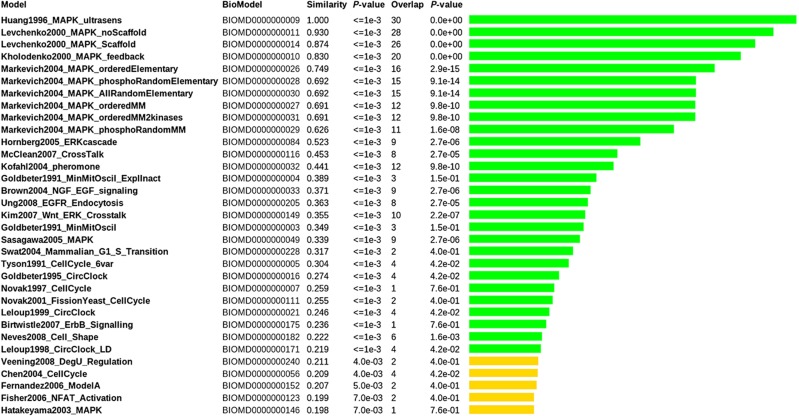
The exploding number of computational models produced by Systems Biologists over the last years is an invitation to structure and exploit this new wealth of information. Researchers would like to trace models relevant to specific scientific questions, to explore their biological content, to align and combine them, and to match them with experimental data. To automate these processes, it is essential to consider semantic annotations, which describe their biological meaning. As a prerequisite for a wide range of computational methods, we propose general and flexible similarity measures for Systems Biology models computed from semantic annotations. By using these measures and a large extensible ontology, we implement a platform that can retrieve, cluster, and align Systems Biology models and experimental data sets. At present, its major application is the search for relevant models in the BioModels Database, starting from initial models, data sets, or lists of biological concepts. Beyond similarity searches, the representation of models by semantic feature vectors may pave the way for visualisation, exploration, and statistical analysis of large collections of models and corresponding data.
近年来,系统生物学家所产生的计算模型数量呈爆炸式增长,这为我们提供了一个整理和利用这些新信息的机会。研究人员希望能够追踪到与特定科学问题相关的模型,探索它们的生物学内涵,对齐和组合这些模型,并将它们与实验数据相匹配。为了实现这些过程的自动化,考虑语义注释以描述其生物学意义是至关重要的。作为广泛的计算方法的前提条件,我们提出了用于从语义注释中计算系统生物学模型的通用且灵活的相似性度量。通过使用这些度量和一个大型可扩展本体,我们实现了一个平台,可以检索、聚类和对齐系统生物学模型和实验数据集。目前,它的主要应用是从初始模型、数据集或生物概念列表开始,在 BioModels 数据库中搜索相关模型。除了相似性搜索之外,通过语义特征向量来表示模型也为可视化、探索和对大量模型和相应数据进行统计分析铺平了道路。