National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Department of Health and Human Services, 8600 Rockville Pike, Bethesda, MD 20894, USA.
J Cheminform. 2011 Jul 22;3(1):26. doi: 10.1186/1758-2946-3-26.
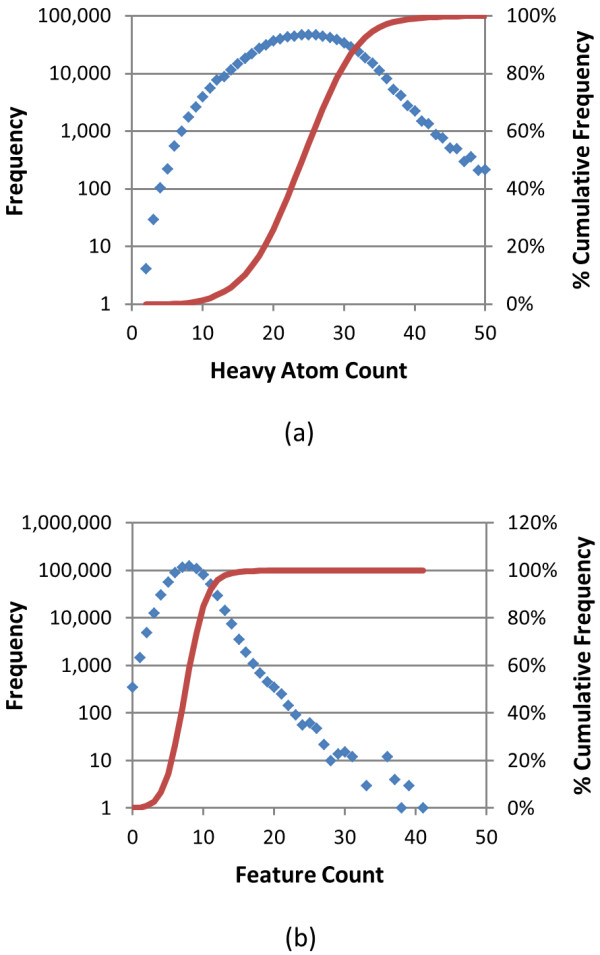
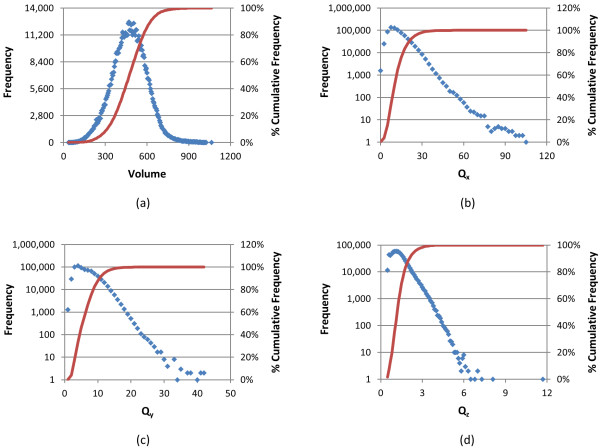
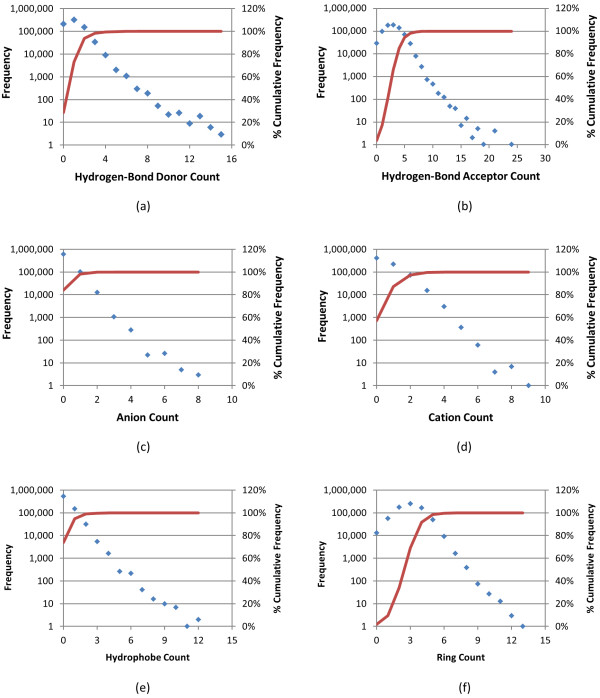
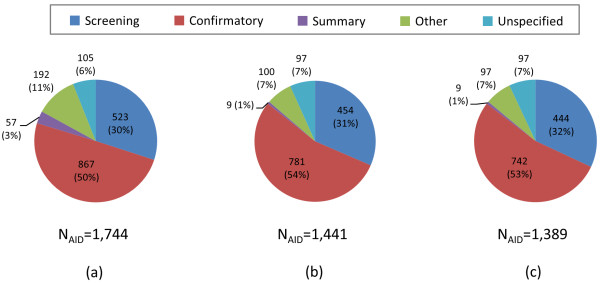
The use of 3-D similarity techniques in the analysis of biological data and virtual screening is pervasive, but what is a biologically meaningful 3-D similarity value? Can one find statistically significant separation between "active/active" and "active/inactive" spaces? These questions are explored using 734,486 biologically tested chemical structures, 1,389 biological assay data sets, and six different 3-D similarity types utilized by PubChem analysis tools.
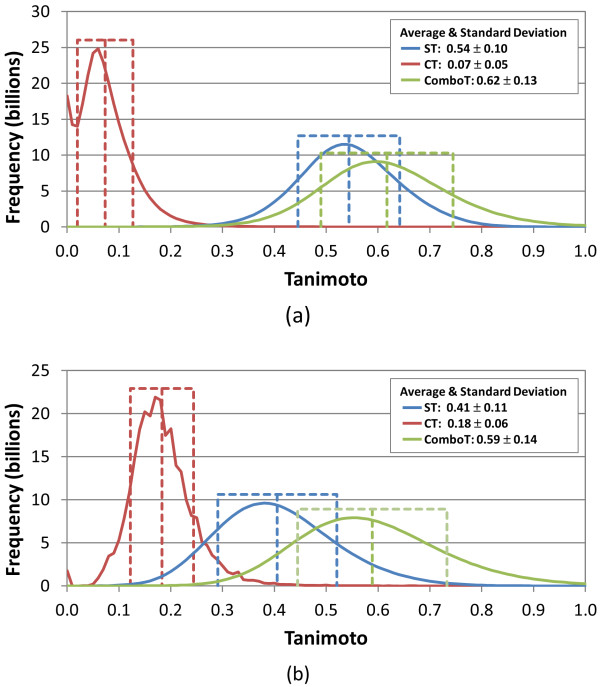
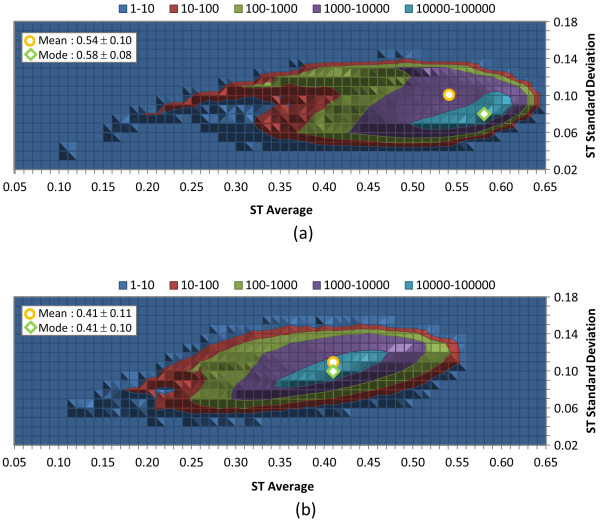
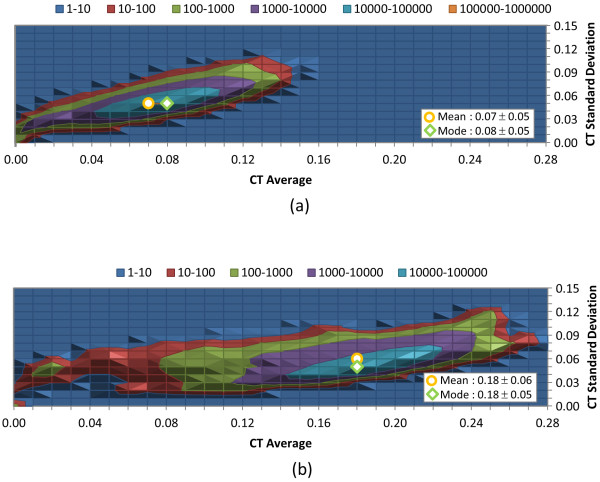
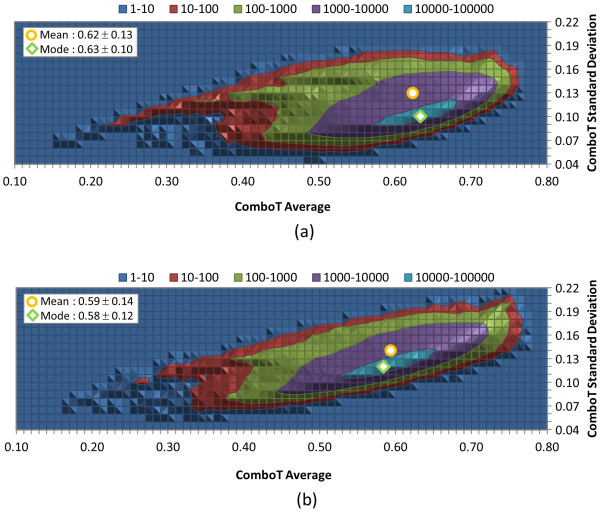
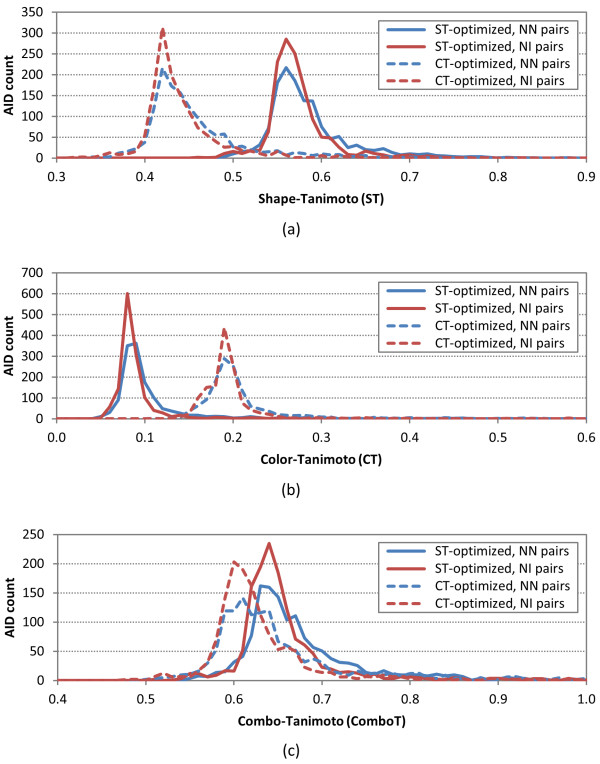
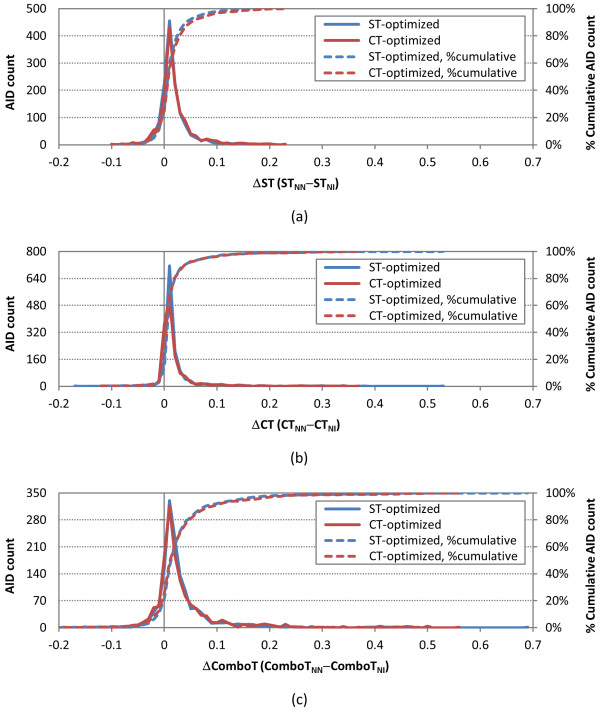
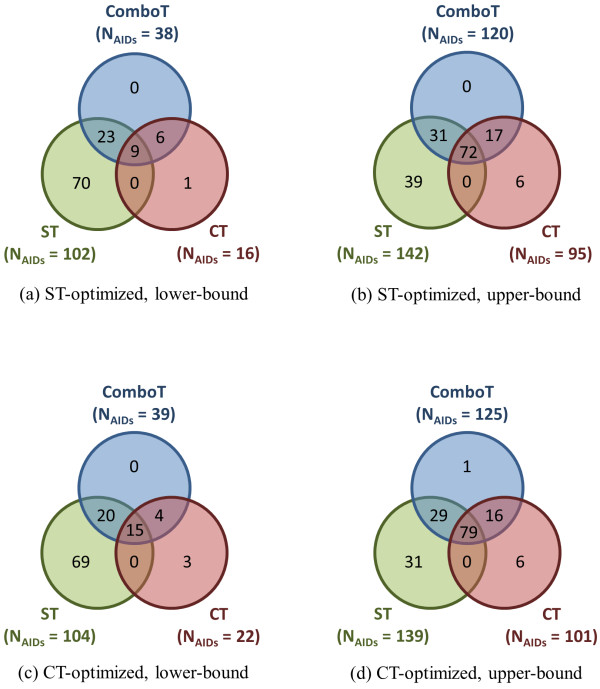
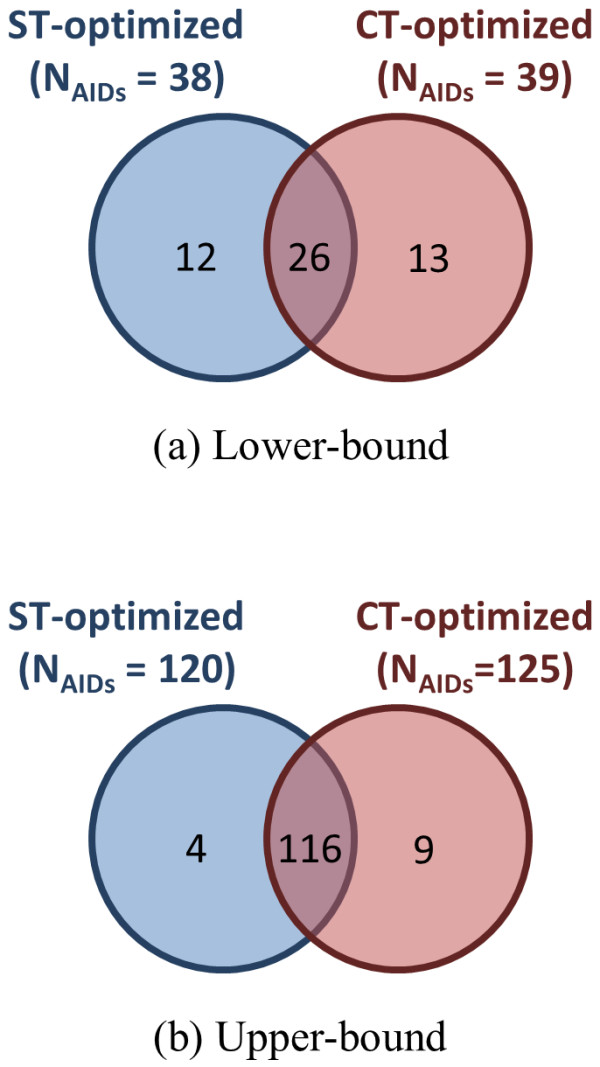
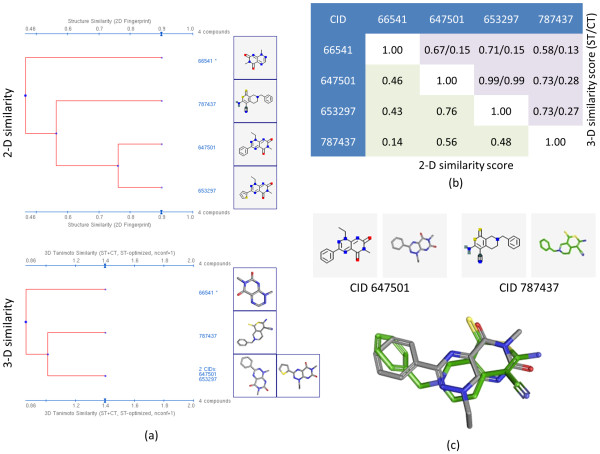
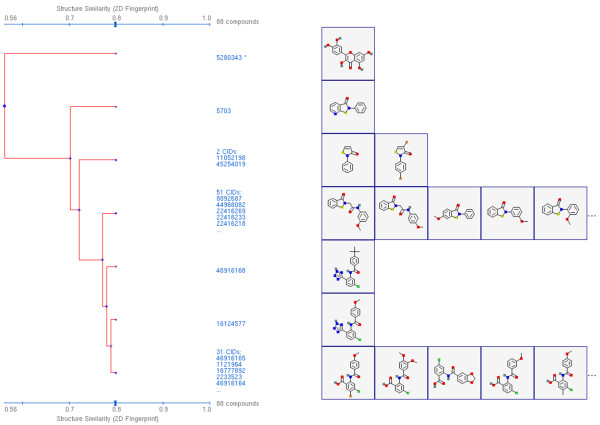
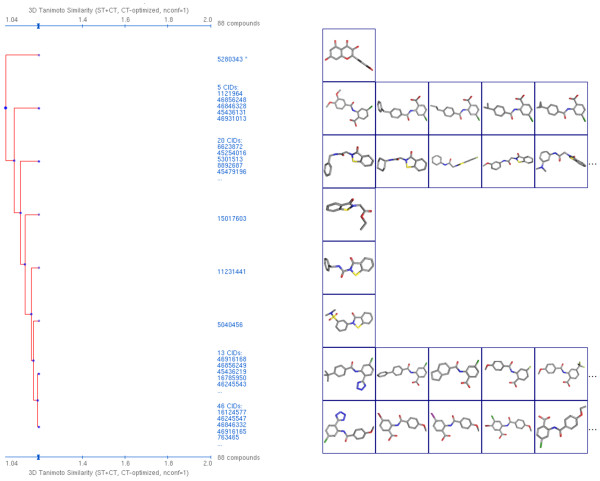
The similarity value distributions of 269.7 billion unique conformer pairs from 734,486 biologically tested compounds (all-against-all) from PubChem were utilized to help work towards an answer to the question: what is a biologically meaningful 3-D similarity score? The average and standard deviation for the six similarity measures STST-opt, CTST-opt, ComboTST-opt, STCT-opt, CTCT-opt, and ComboTCT-opt were 0.54 ± 0.10, 0.07 ± 0.05, 0.62 ± 0.13, 0.41 ± 0.11, 0.18 ± 0.06, and 0.59 ± 0.14, respectively. Considering that this random distribution of biologically tested compounds was constructed using a single theoretical conformer per compound (the "default" conformer provided by PubChem), further study may be necessary using multiple diverse conformers per compound; however, given the breadth of the compound set, the single conformer per compound results may still apply to the case of multi-conformer per compound 3-D similarity value distributions. As such, this work is a critical step, covering a very wide corpus of chemical structures and biological assays, creating a statistical framework to build upon.The second part of this study explored the question of whether it was possible to realize a statistically meaningful 3-D similarity value separation between reputed biological assay "inactives" and "actives". Using the terminology of noninactive-noninactive (NN) pairs and the noninactive-inactive (NI) pairs to represent comparison of the "active/active" and "active/inactive" spaces, respectively, each of the 1,389 biological assays was examined by their 3-D similarity score differences between the NN and NI pairs and analyzed across all assays and by assay category types. While a consistent trend of separation was observed, this result was not statistically unambiguous after considering the respective standard deviations. While not all "actives" in a biological assay are amenable to this type of analysis, e.g., due to different mechanisms of action or binding configurations, the ambiguous separation may also be due to employing a single conformer per compound in this study. With that said, there were a subset of biological assays where a clear separation between the NN and NI pairs found. In addition, use of combo Tanimoto (ComboT) alone, independent of superposition optimization type, appears to be the most efficient 3-D score type in identifying these cases.
This study provides a statistical guideline for analyzing biological assay data in terms of 3-D similarity and PubChem structure-activity analysis tools. When using a single conformer per compound, a relatively small number of assays appear to be able to separate "active/active" space from "active/inactive" space.
在生物数据和虚拟筛选的分析中,三维相似性技术的使用非常普遍,但是什么是具有生物学意义的三维相似性值呢?是否可以在“活性/活性”和“活性/非活性”空间之间找到具有统计学意义的分离?本研究使用 PubChem 分析工具的 6 种不同的 3-D 相似性类型,通过 734,486 种经过生物学测试的化学结构和 1,389 个生物测定数据集来探索这些问题。
利用 PubChem 中 734,486 种经过生物学测试的化合物(所有化合物对所有化合物)的 269.7 亿个独特构象对的相似性值分布,有助于回答以下问题:什么是具有生物学意义的三维相似性评分?6 种相似性度量 STST-opt、CTST-opt、ComboTST-opt、STCT-opt、CTCT-opt 和 ComboTCT-opt 的平均值和标准差分别为 0.54±0.10、0.07±0.05、0.62±0.13、0.41±0.11、0.18±0.06 和 0.59±0.14。考虑到使用单一理论构象(PubChem 提供的“默认”构象)构建这种经过生物学测试的化合物的随机分布,可能需要进一步研究使用每种化合物的多个不同构象;但是,鉴于化合物集的广度,单一构象化合物的结果可能仍然适用于具有多种构象的化合物的 3-D 相似值分布。因此,这项工作是一个关键步骤,涵盖了非常广泛的化学结构和生物测定数据集,为进一步建立统计框架奠定了基础。本研究的第二部分探讨了是否有可能在声誉良好的生物测定“非活性”和“活性”之间实现具有统计学意义的三维相似性值分离的问题。使用术语非非活性-非非活性(NN)对和非非活性-活性(NI)对分别表示“活性/活性”和“活性/非活性”空间的比较,分别对 1,389 个生物测定进行了分析,比较了 NN 和 NI 对之间的 3-D 相似性评分差异,并对所有测定和测定类别类型进行了分析。尽管观察到了一致的分离趋势,但在考虑各自的标准差后,这一结果并不具有统计学意义。虽然生物测定中的所有“活性”物质都不能进行这种类型的分析,例如由于不同的作用机制或结合构象,但这种不明确的分离也可能是由于在这项研究中对每种化合物都使用了单一构象。话虽如此,有一部分生物测定能够清楚地分离 NN 和 NI 对。此外,单独使用组合 Tanimoto(ComboT),而不考虑叠加优化类型,似乎是识别这些情况的最有效的 3-D 评分类型。
本研究为分析生物测定数据的三维相似性和 PubChem 结构-活性分析工具提供了统计指南。当对每种化合物使用单一构象时,似乎只有相对较少的测定能够将“活性/活性”空间与“活性/非活性”空间分离。