National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, Maryland 20894.
National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, Maryland 20894.
J Biol Chem. 2012 Jan 2;287(1):21-28. doi: 10.1074/jbc.R111.241976. Epub 2011 Nov 8.
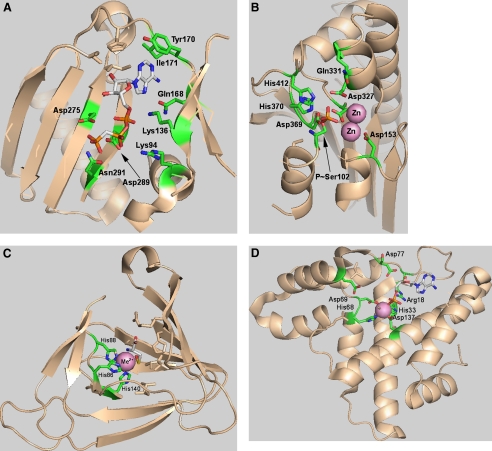
Comparative analysis of the sequences of enzymes encoded in a variety of prokaryotic and eukaryotic genomes reveals convergence and divergence at several levels. Functional convergence can be inferred when structurally distinct and hence non-homologous enzymes show the ability to catalyze the same biochemical reaction. In contrast, as a result of functional diversification, many structurally similar enzyme molecules act on substantially distinct substrates and catalyze diverse biochemical reactions. Here, we present updates on the ATP-grasp, alkaline phosphatase, cupin, HD hydrolase, and N-terminal nucleophile (Ntn) hydrolase enzyme superfamilies and discuss the patterns of sequence and structural conservation and diversity within these superfamilies. Typically, enzymes within a superfamily possess common sequence motifs and key active site residues, as well as (predicted) reaction mechanisms. These observations suggest that the strained conformation (the entatic state) of the active site, which is responsible for the substrate binding and formation of the transition complex, tends to be conserved within enzyme superfamilies. The subsequent fate of the transition complex is not necessarily conserved and depends on the details of the structures of the enzyme and the substrate. This variability of reaction outcomes limits the ability of sequence analysis to predict the exact enzymatic activities of newly sequenced gene products. Nevertheless, sequence-based (super)family assignments and generic functional predictions, even if imprecise, provide valuable leads for experimental studies and remain the best approach to the functional annotation of uncharacterized proteins from new genomes.
对各种原核生物和真核生物基因组中编码的酶序列进行比较分析,揭示了在几个层次上的趋同和分歧。当结构不同且因此非同源的酶表现出催化相同生化反应的能力时,可以推断出功能趋同。相比之下,由于功能多样化,许多结构相似的酶分子作用于明显不同的底物,并催化不同的生化反应。在这里,我们介绍了 ATP 结合酶、碱性磷酸酶、cupin、HD 水解酶和 N 端核酶 (Ntn) 水解酶超家族的最新进展,并讨论了这些超家族中序列和结构保守性和多样性的模式。通常,超家族中的酶具有共同的序列基序和关键的活性位点残基,以及(预测的)反应机制。这些观察结果表明,负责底物结合和过渡态复合物形成的活性位点的紧张构象(entatic 态)在酶超家族中趋于保守。过渡态复合物的后续命运不一定保守,取决于酶和底物的结构细节。这种反应结果的可变性限制了序列分析预测新测序基因产物的确切酶活性的能力。尽管如此,基于序列的(超)家族分配和通用功能预测,即使不精确,也为实验研究提供了有价值的线索,并仍然是对新基因组中未表征蛋白质进行功能注释的最佳方法。