The Department of Statistics, West Virginia University, Morgantown, WV 26506, USA.
BMC Bioinformatics. 2011 Nov 18;12:450. doi: 10.1186/1471-2105-12-450.
Successfully modeling high-dimensional data involving thousands of variables is challenging. This is especially true for gene expression profiling experiments, given the large number of genes involved and the small number of samples available. Random Forests (RF) is a popular and widely used approach to feature selection for such "small n, large p problems." However, Random Forests suffers from instability, especially in the presence of noisy and/or unbalanced inputs.
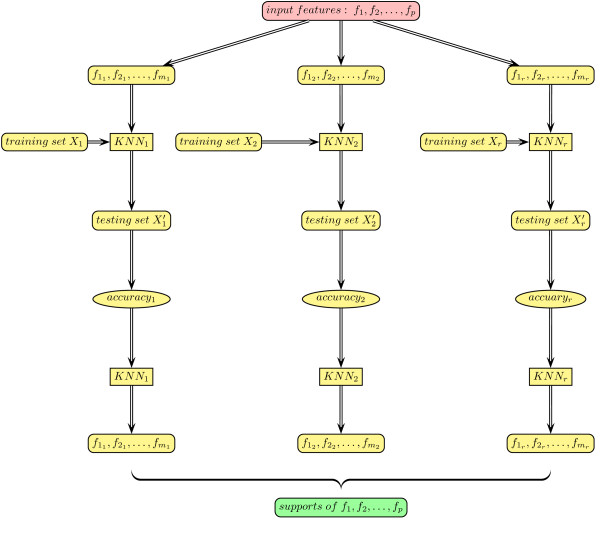
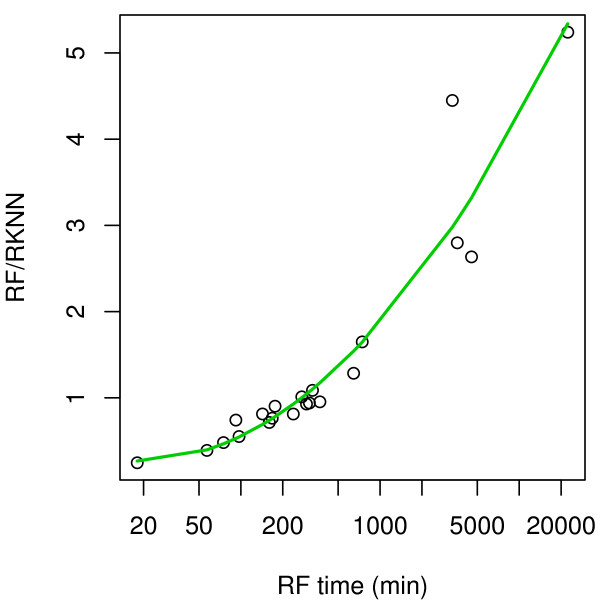
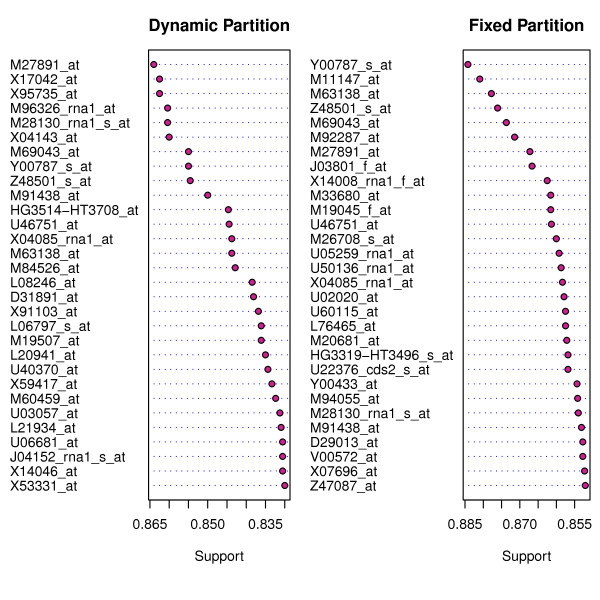
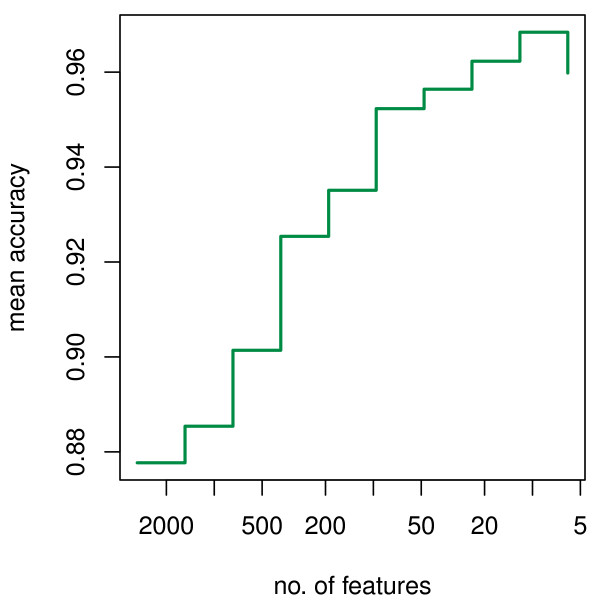
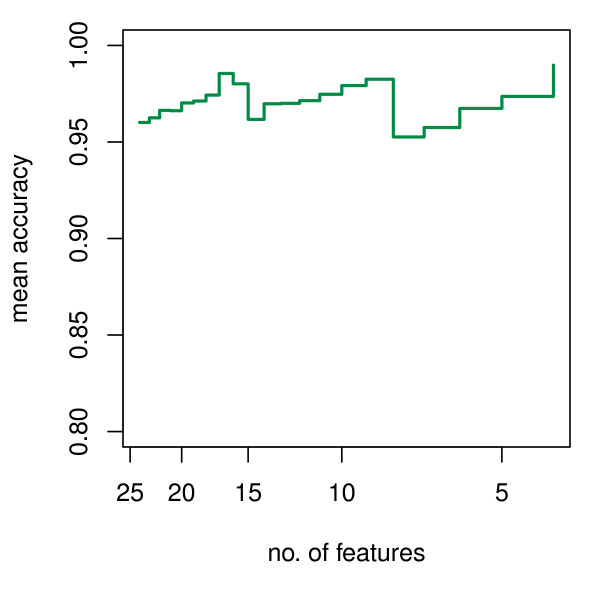
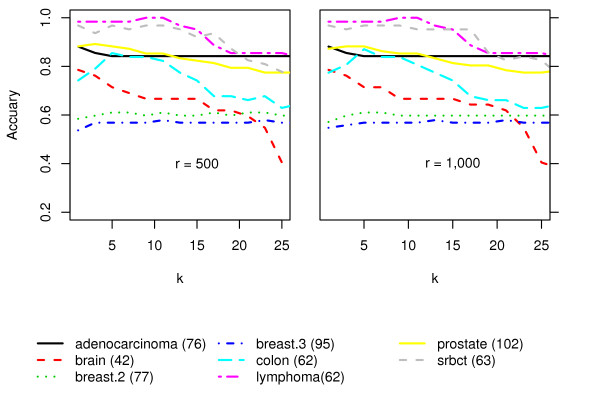
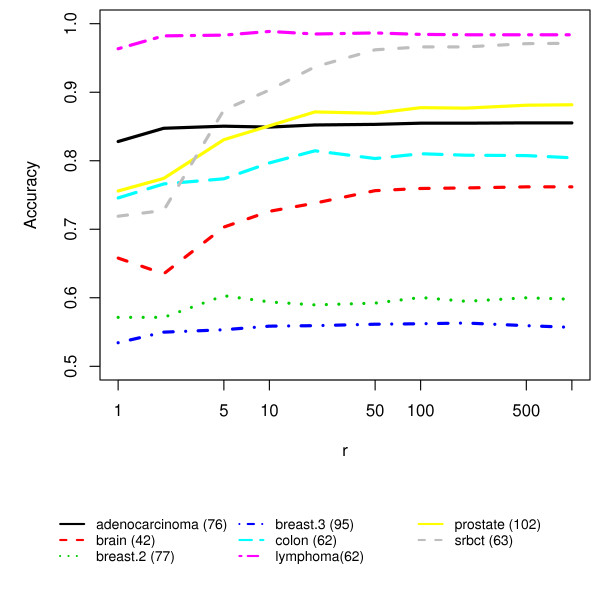
We present RKNN-FS, an innovative feature selection procedure for "small n, large p problems." RKNN-FS is based on Random KNN (RKNN), a novel generalization of traditional nearest-neighbor modeling. RKNN consists of an ensemble of base k-nearest neighbor models, each constructed from a random subset of the input variables. To rank the importance of the variables, we define a criterion on the RKNN framework, using the notion of support. A two-stage backward model selection method is then developed based on this criterion. Empirical results on microarray data sets with thousands of variables and relatively few samples show that RKNN-FS is an effective feature selection approach for high-dimensional data. RKNN is similar to Random Forests in terms of classification accuracy without feature selection. However, RKNN provides much better classification accuracy than RF when each method incorporates a feature-selection step. Our results show that RKNN is significantly more stable and more robust than Random Forests for feature selection when the input data are noisy and/or unbalanced. Further, RKNN-FS is much faster than the Random Forests feature selection method (RF-FS), especially for large scale problems, involving thousands of variables and multiple classes.
Given the superiority of Random KNN in classification performance when compared with Random Forests, RKNN-FS's simplicity and ease of implementation, and its superiority in speed and stability, we propose RKNN-FS as a faster and more stable alternative to Random Forests in classification problems involving feature selection for high-dimensional datasets.
成功建模涉及数千个变量的高维数据具有挑战性。对于基因表达谱实验来说尤其如此,因为涉及到大量的基因,而可用的样本数量却很少。随机森林(RF)是一种流行且广泛使用的特征选择方法,用于解决这种“小 n,大 p 问题”。然而,随机森林存在不稳定性,尤其是在存在噪声和/或不平衡输入的情况下。
我们提出了 RKNN-FS,这是一种用于“小 n,大 p 问题”的创新特征选择程序。RKNN-FS 基于随机 KNN(RKNN),这是传统最近邻建模的一种新推广。RKNN 由一组基 k-最近邻模型组成,每个模型都是从输入变量的随机子集构建的。为了对变量的重要性进行排序,我们在 RKNN 框架上定义了一个基于支持的标准。然后基于该标准开发了一种两阶段后向模型选择方法。在具有数千个变量和相对较少样本的微阵列数据集上的实验结果表明,RKNN-FS 是一种用于高维数据的有效特征选择方法。在没有特征选择的情况下,RKNN 在分类准确性方面与随机森林相似。但是,当每种方法都包含特征选择步骤时,RKNN 提供的分类准确性要优于 RF。我们的结果表明,在输入数据存在噪声和/或不平衡的情况下,RKNN 比随机森林在特征选择方面更稳定和更健壮。此外,与随机森林特征选择方法(RF-FS)相比,RKNN-FS 速度更快,尤其是对于涉及数千个变量和多个类别的大规模问题。
鉴于随机 KNN 在分类性能方面优于随机森林,RKNN-FS 的简单易用性,以及在速度和稳定性方面的优势,我们建议在涉及高维数据集的特征选择的分类问题中,将 RKNN-FS 作为随机森林的更快、更稳定的替代方案。