Chemoinformatics and Metabolism, European Bioinformatics Institute (EBI), Cambridge, UK.
J Cheminform. 2011 Dec 13;3:54. doi: 10.1186/1758-2946-3-54.
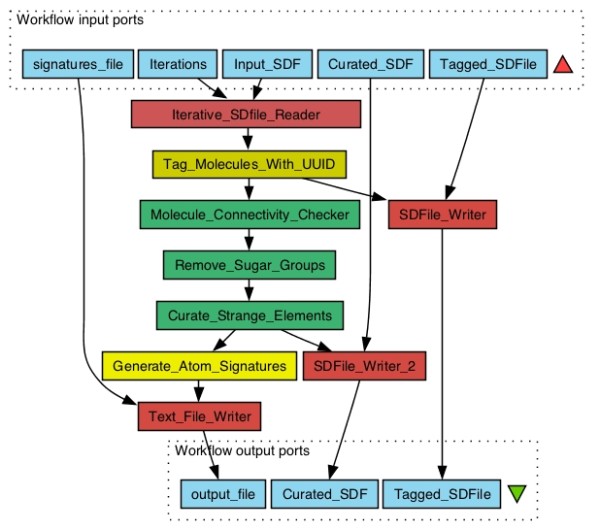
The computational processing and analysis of small molecules is at heart of cheminformatics and structural bioinformatics and their application in e.g. metabolomics or drug discovery. Pipelining or workflow tools allow for the Lego™-like, graphical assembly of I/O modules and algorithms into a complex workflow which can be easily deployed, modified and tested without the hassle of implementing it into a monolithic application. The CDK-Taverna project aims at building a free open-source cheminformatics pipelining solution through combination of different open-source projects such as Taverna, the Chemistry Development Kit (CDK) or the Waikato Environment for Knowledge Analysis (WEKA). A first integrated version 1.0 of CDK-Taverna was recently released to the public.
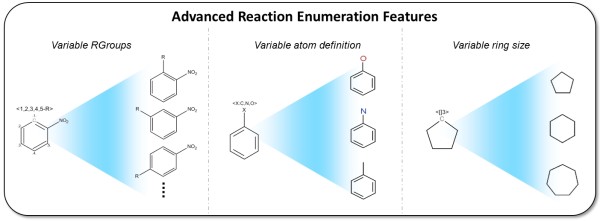
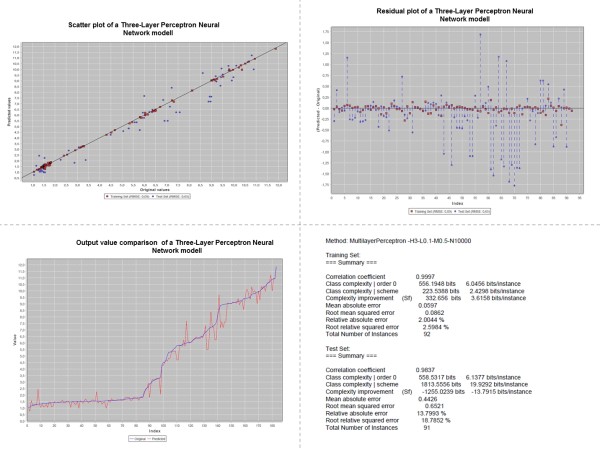
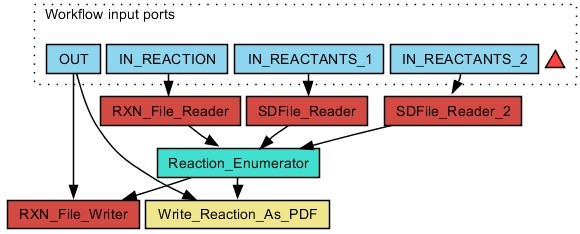
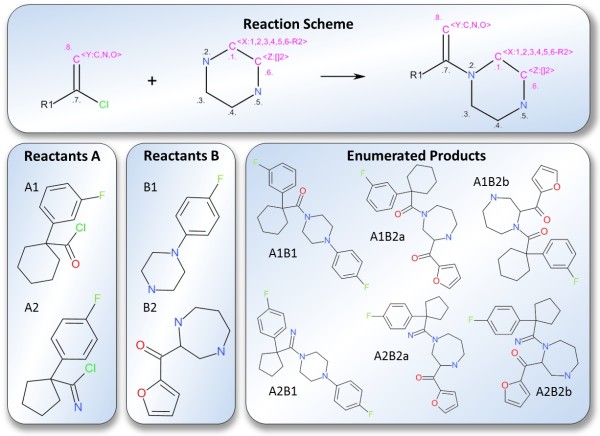
The CDK-Taverna project was migrated to the most up-to-date versions of its foundational software libraries with a complete re-engineering of its worker's architecture (version 2.0). 64-bit computing and multi-core usage by paralleled threads are now supported to allow for fast in-memory processing and analysis of large sets of molecules. Earlier deficiencies like workarounds for iterative data reading are removed. The combinatorial chemistry related reaction enumeration features are considerably enhanced. Additional functionality for calculating a natural product likeness score for small molecules is implemented to identify possible drug candidates. Finally the data analysis capabilities are extended with new workers that provide access to the open-source WEKA library for clustering and machine learning as well as training and test set partitioning. The new features are outlined with usage scenarios.
CDK-Taverna 2.0 as an open-source cheminformatics workflow solution matured to become a freely available and increasingly powerful tool for the biosciences. The combination of the new CDK-Taverna worker family with the already available workflows developed by a lively Taverna community and published on myexperiment.org enables molecular scientists to quickly calculate, process and analyse molecular data as typically found in e.g. today's systems biology scenarios.
小分子的计算处理和分析是化学生物信息学和结构生物信息学的核心,它们在代谢组学或药物发现等领域得到了广泛应用。流水线或工作流程工具允许以图形方式将输入/输出模块和算法“搭积木”式地组装成一个复杂的工作流程,而无需将其实现到一个整体应用程序中,即可轻松部署、修改和测试该工作流程。CDK-Taverna 项目旨在通过组合不同的开源项目(如 Taverna、化学开发工具包 (CDK) 或怀卡托知识分析环境 (WEKA))构建一个免费的开源化学生物信息学流水线解决方案。最近,CDK-Taverna 的第一个集成版本 1.0 已向公众发布。
CDK-Taverna 项目已迁移到其基础软件库的最新版本,并对其工作人员架构(版本 2.0)进行了全面的重新设计。现在支持 64 位计算和多核心使用并行线程,以便对大量分子进行快速内存处理和分析。早期的缺陷,如迭代数据读取的解决方法已被删除。组合化学相关的反应枚举功能得到了显著增强。为小分子计算天然产物相似性得分实现了额外的功能,以识别可能的药物候选物。最后,通过提供对开源 WEKA 库的访问,新的工作人员扩展了数据分析功能,用于聚类和机器学习以及培训和测试集分区。新功能结合使用场景进行了概述。
作为一个开源化学生物信息学工作流程解决方案,CDK-Taverna 2.0 已经成熟,成为生物科学领域自由可用且功能日益强大的工具。将新的 CDK-Taverna 工作人员系列与已经在 myexperiment.org 上发布的由活跃的 Taverna 社区开发的现有工作流程相结合,使分子科学家能够快速计算、处理和分析分子数据,这些数据通常可以在当今的系统生物学场景中找到。