Chen Elizabeth S, Sarkar Indra Neil
Center for Clinical and Translational Science.
AMIA Jt Summits Transl Sci Proc. 2011;2011:6-10. Epub 2011 Mar 7.
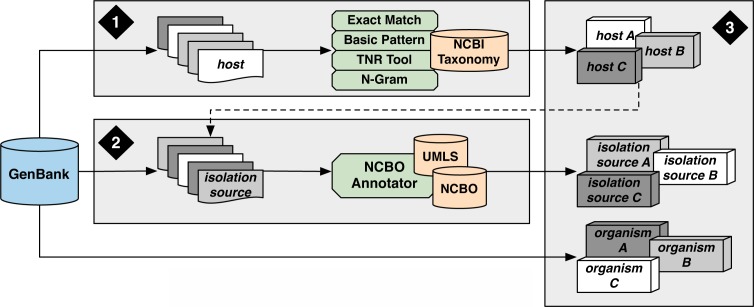
Within large sequence repositories such as GenBank there is a wealth of metadata providing contextual information that may enhance search and retrieval of relevant sequences for a range of subsequent analyses. One challenge is the use of free-text in these metadata fields where approaches are needed to extract, structure, and encode essential information. The goal of the present study was to explore the feasibility of using a combination of existing resources for annotating unstructured GenBank metadata, initially focusing on the "host" and "isolation_source" fields. This paper summarizes early results for 10 host organisms that include a characterization of associated isolation sources with respect to biomedical ontologies and semantic types. The findings from this preliminary study provide insights to the rich amount of information captured within these unstructured metadata, guidance for addressing the challenges and issues encountered, and highlight the potential value for enriching comparative biological studies towards improving human health.
在诸如GenBank这样的大型序列数据库中,有大量的元数据提供上下文信息,这些信息可能会增强对一系列后续分析相关序列的搜索和检索。一个挑战是在这些元数据字段中使用自由文本,需要采用方法来提取、构建和编码基本信息。本研究的目的是探讨使用现有资源组合注释非结构化GenBank元数据的可行性,最初重点关注“宿主”和“分离源”字段。本文总结了10种宿主生物的早期结果,包括根据生物医学本体和语义类型对相关分离源的特征描述。这项初步研究的结果为这些非结构化元数据中捕获的丰富信息提供了见解,为应对遇到的挑战和问题提供了指导,并突出了丰富比较生物学研究以改善人类健康的潜在价值。