Heinz Nixdorf Chair for Distributed Information Systems, Department of Mathematics and Computer Science, Friedrich Schiller University Jena, Jena, Germany.
Michael-Stifel-Center for Data-Driven and Simulation Science, Jena, Germany.
PLoS One. 2021 Mar 24;16(3):e0246099. doi: 10.1371/journal.pone.0246099. eCollection 2021.
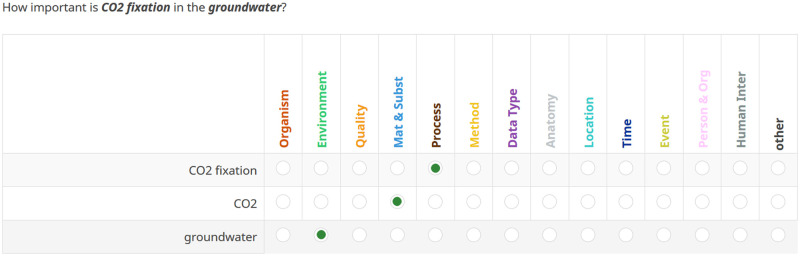
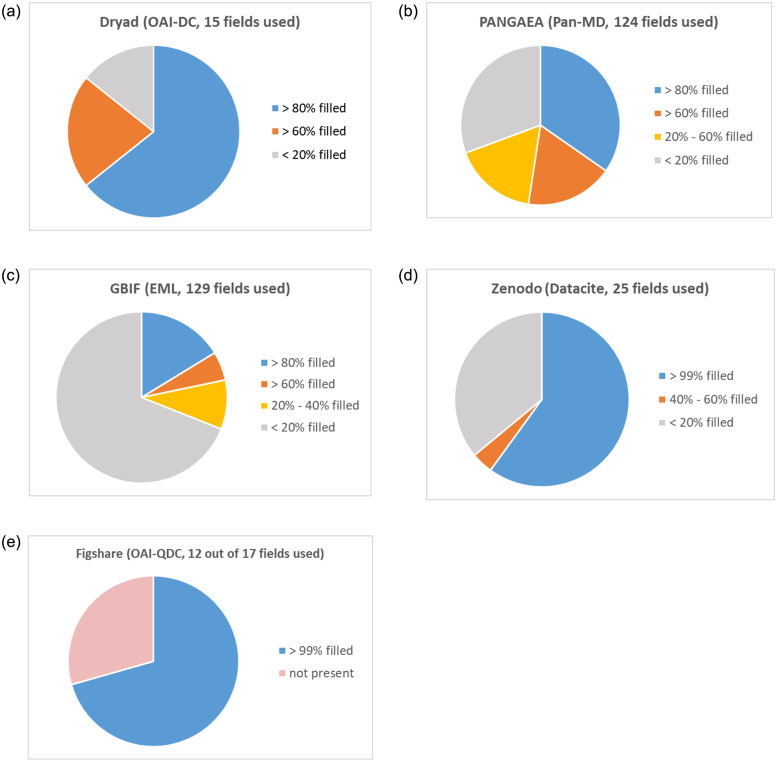
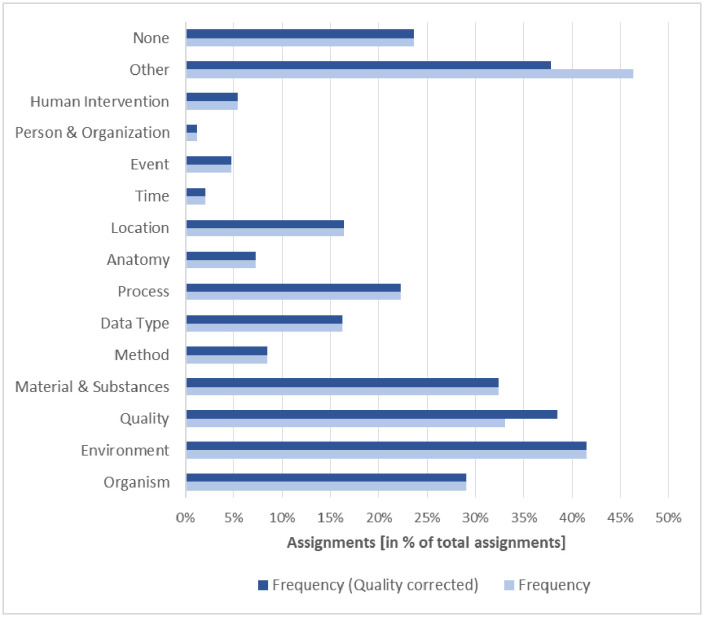
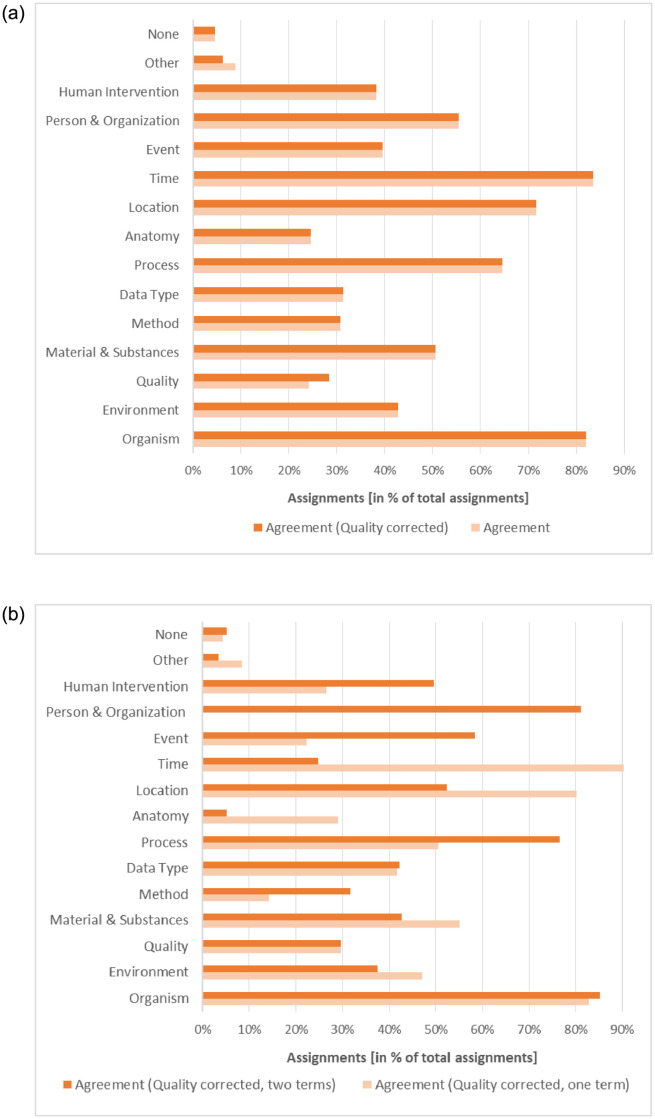
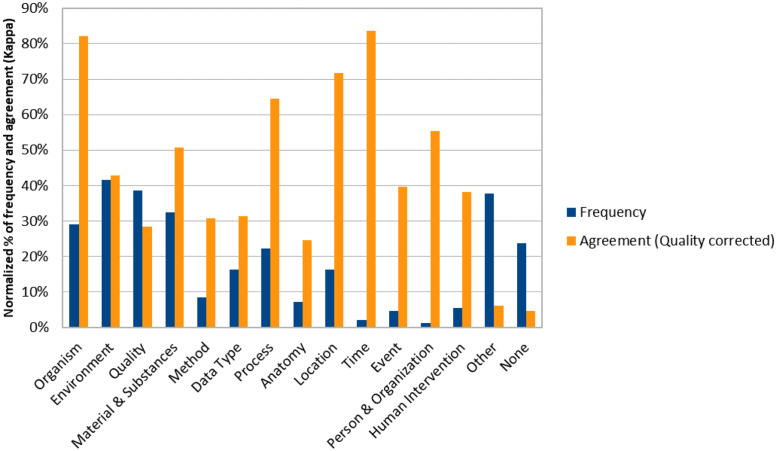
The increasing amount of publicly available research data provides the opportunity to link and integrate data in order to create and prove novel hypotheses, to repeat experiments or to compare recent data to data collected at a different time or place. However, recent studies have shown that retrieving relevant data for data reuse is a time-consuming task in daily research practice. In this study, we explore what hampers dataset retrieval in biodiversity research, a field that produces a large amount of heterogeneous data. In particular, we focus on scholarly search interests and metadata, the primary source of data in a dataset retrieval system. We show that existing metadata currently poorly reflect information needs and therefore are the biggest obstacle in retrieving relevant data. Our findings indicate that for data seekers in the biodiversity domain environments, materials and chemicals, species, biological and chemical processes, locations, data parameters and data types are important information categories. These interests are well covered in metadata elements of domain-specific standards. However, instead of utilizing these standards, large data repositories tend to use metadata standards with domain-independent metadata fields that cover search interests only to some extent. A second problem are arbitrary keywords utilized in descriptive fields such as title, description or subject. Keywords support scholars in a full text search only if the provided terms syntactically match or their semantic relationship to terms used in a user query is known.
越来越多的公开研究数据为数据链接和整合提供了机会,以便创建和验证新的假设、重复实验,或比较近期数据与不同时间或地点收集的数据。然而,最近的研究表明,在日常研究实践中,检索相关数据以进行数据再利用是一项耗时的任务。在这项研究中,我们探讨了在生物多样性研究中阻碍数据集检索的因素,该领域产生了大量异构数据。特别是,我们关注学术搜索兴趣和元数据,这是数据集检索系统的主要数据来源。我们发现,现有的元数据目前不能很好地反映信息需求,因此是检索相关数据的最大障碍。我们的研究结果表明,对于生物多样性领域的环境、材料和化学品、物种、生物和化学过程、位置、数据参数和数据类型等信息类别,数据搜索者非常关注。这些兴趣在特定领域标准的元数据元素中得到了很好的涵盖。然而,大型数据库往往没有利用这些标准,而是使用具有领域独立性的元数据字段的元数据标准,这些字段在一定程度上涵盖了搜索兴趣。第二个问题是在标题、描述或主题等描述性字段中使用任意关键字。只有在提供的术语在语法上匹配或其与用户查询中使用的术语的语义关系已知的情况下,关键字才能支持学者进行全文搜索。