Center for Research in Biological Systems, University of California San Diego, CA, USA.
Database (Oxford). 2012 Mar 20;2012:bas005. doi: 10.1093/database/bas005. Print 2012.
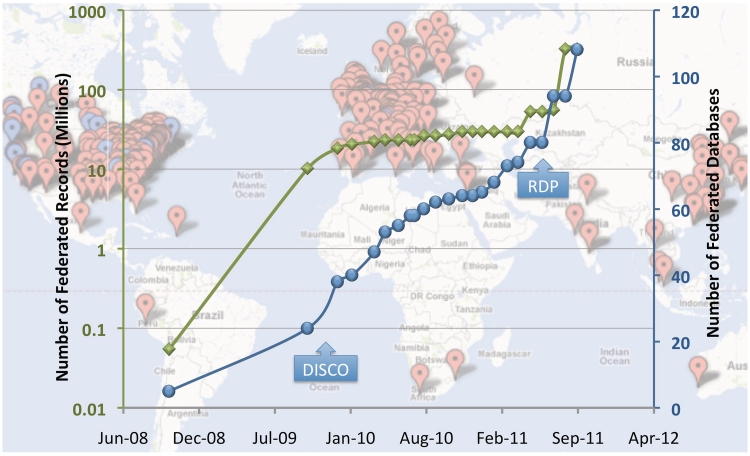
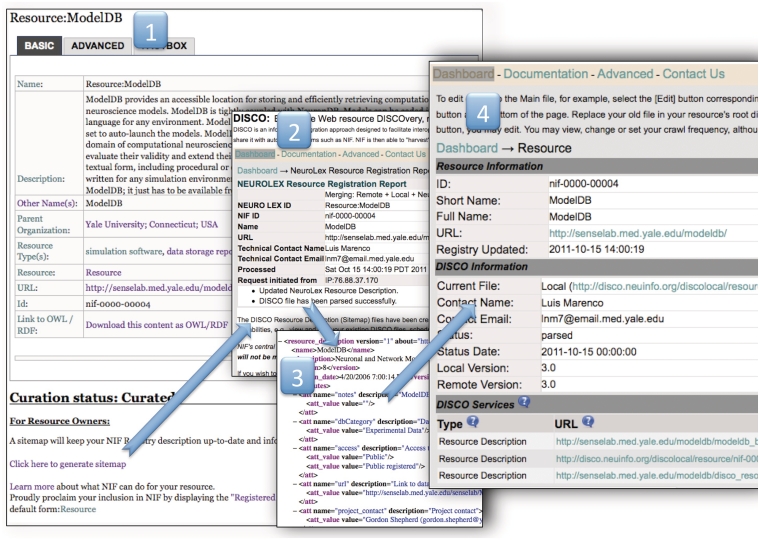
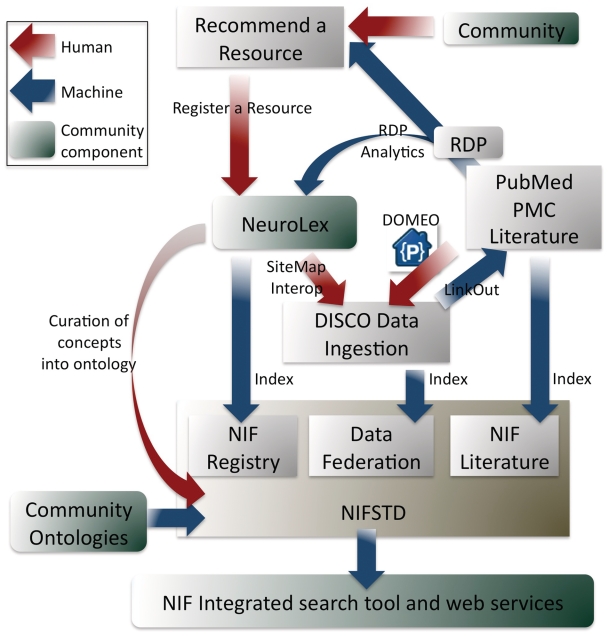
The breadth of information resources available to researchers on the Internet continues to expand, particularly in light of recently implemented data-sharing policies required by funding agencies. However, the nature of dense, multifaceted neuroscience data and the design of contemporary search engine systems makes efficient, reliable and relevant discovery of such information a significant challenge. This challenge is specifically pertinent for online databases, whose dynamic content is 'hidden' from search engines. The Neuroscience Information Framework (NIF; http://www.neuinfo.org) was funded by the NIH Blueprint for Neuroscience Research to address the problem of finding and utilizing neuroscience-relevant resources such as software tools, data sets, experimental animals and antibodies across the Internet. From the outset, NIF sought to provide an accounting of available resources, whereas developing technical solutions to finding, accessing and utilizing them. The curators therefore, are tasked with identifying and registering resources, examining data, writing configuration files to index and display data and keeping the contents current. In the initial phases of the project, all aspects of the registration and curation processes were manual. However, as the number of resources grew, manual curation became impractical. This report describes our experiences and successes with developing automated resource discovery and semiautomated type characterization with text-mining scripts that facilitate curation team efforts to discover, integrate and display new content. We also describe the DISCO framework, a suite of automated web services that significantly reduce manual curation efforts to periodically check for resource updates. Lastly, we discuss DOMEO, a semi-automated annotation tool that improves the discovery and curation of resources that are not necessarily website-based (i.e. reagents, software tools). Although the ultimate goal of automation was to reduce the workload of the curators, it has resulted in valuable analytic by-products that address accessibility, use and citation of resources that can now be shared with resource owners and the larger scientific community. DATABASE URL: http://neuinfo.org.
互联网上可向研究人员提供的信息资源不断增加,特别是在各资助机构最近实施了数据共享政策之后。然而,由于神经科学数据密集且多方面的特性以及当代搜索引擎系统的设计,高效、可靠和相关地发现这些信息仍然是一个重大挑战。这一挑战对于在线数据库而言尤为突出,因为这些数据库的动态内容对搜索引擎是“隐藏”的。由 NIH 神经科学研究蓝图资助的神经科学信息框架(NIF;http://www.neuinfo.org)旨在解决在互联网上查找和利用神经科学相关资源(如软件工具、数据集、实验动物和抗体)的问题。从一开始,NIF 就寻求提供现有资源的清单,同时开发查找、访问和利用这些资源的技术解决方案。因此,编目人员的任务是识别和注册资源、检查数据、编写配置文件以对数据进行索引和显示,并保持内容的最新。在项目的初始阶段,注册和编目过程的所有方面都是手动进行的。然而,随着资源数量的增加,手动编目变得不切实际。本报告介绍了我们在开发自动化资源发现和半自动化类型特征描述方面的经验和成功,使用文本挖掘脚本简化编目团队的工作,以发现、集成和显示新内容。我们还介绍了 DISCO 框架,这是一套自动化的 Web 服务,可以大大减少手动编目工作,以定期检查资源更新。最后,我们讨论了 DOMEO,这是一种半自动化的注释工具,可改善对非基于网站的资源(即试剂、软件工具)的发现和编目。尽管自动化的最终目标是减少编目人员的工作量,但它产生了有价值的分析副产品,解决了资源的可访问性、使用和引用问题,现在可以与资源所有者和更广泛的科学界共享这些副产品。数据库 URL:http://neuinfo.org。