Chen Xiaoling, Gururaj Anupama E, Ozyurt Burak, Liu Ruiling, Soysal Ergin, Cohen Trevor, Tiryaki Firat, Li Yueling, Zong Nansu, Jiang Min, Rogith Deevakar, Salimi Mandana, Kim Hyeon-Eui, Rocca-Serra Philippe, Gonzalez-Beltran Alejandra, Farcas Claudiu, Johnson Todd, Margolis Ron, Alter George, Sansone Susanna-Assunta, Fore Ian M, Ohno-Machado Lucila, Grethe Jeffrey S, Xu Hua
School of Biomedical Informatics, The University of Texas Health Science Center at Houston, Houston, TX, USA.
Center for Research in Biological Systems.
J Am Med Inform Assoc. 2018 Mar 1;25(3):300-308. doi: 10.1093/jamia/ocx121.
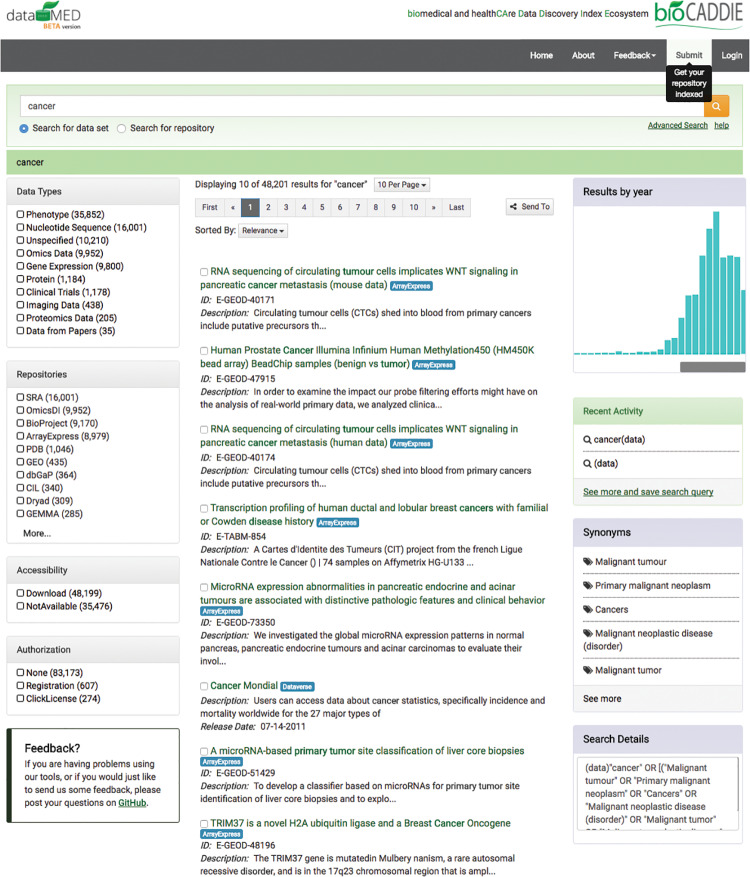
Finding relevant datasets is important for promoting data reuse in the biomedical domain, but it is challenging given the volume and complexity of biomedical data. Here we describe the development of an open source biomedical data discovery system called DataMed, with the goal of promoting the building of additional data indexes in the biomedical domain.
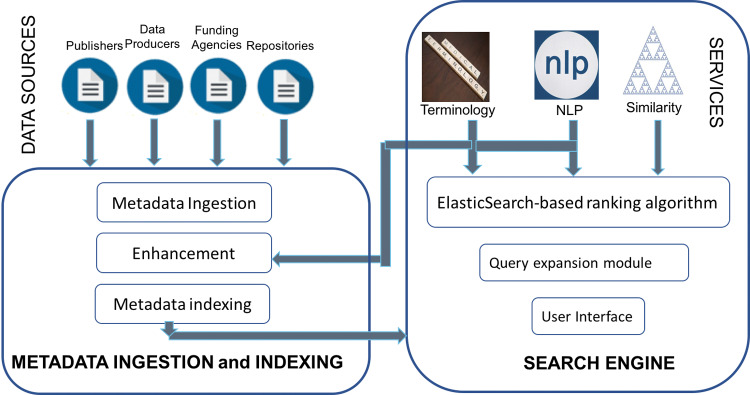
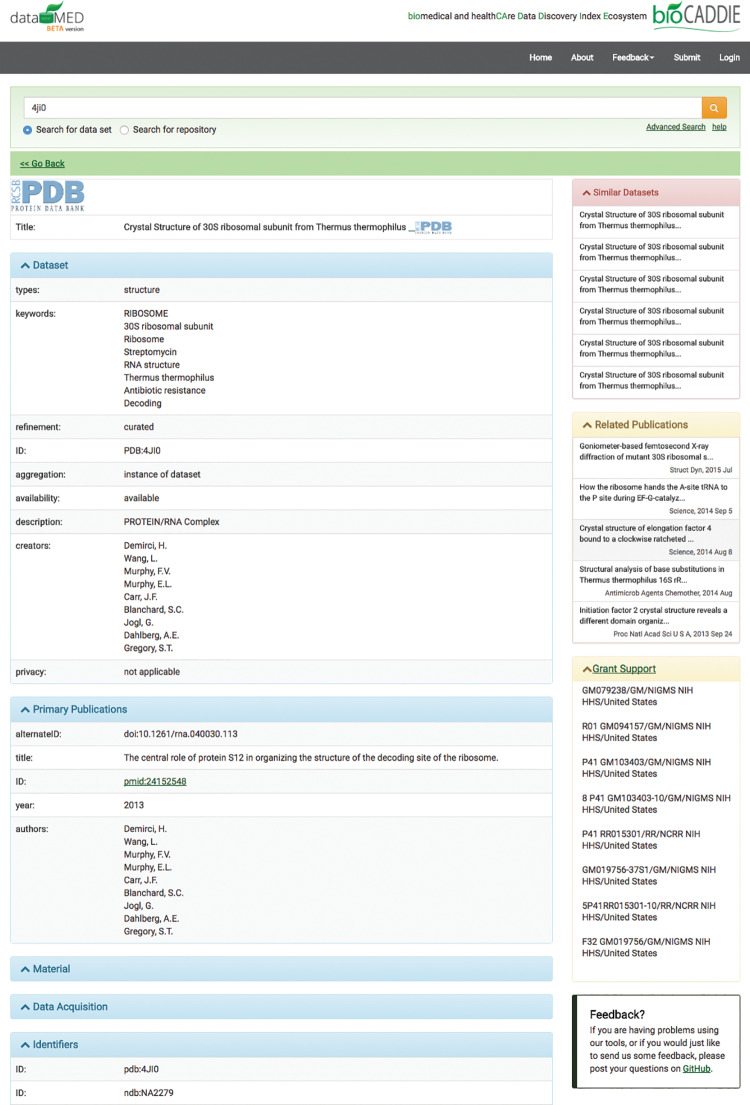
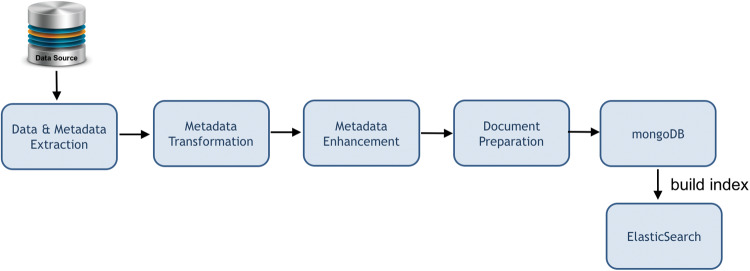
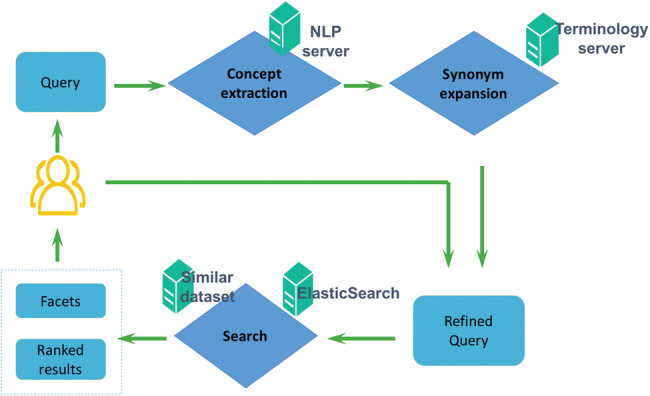
DataMed, which can efficiently index and search diverse types of biomedical datasets across repositories, is developed through the National Institutes of Health-funded biomedical and healthCAre Data Discovery Index Ecosystem (bioCADDIE) consortium. It consists of 2 main components: (1) a data ingestion pipeline that collects and transforms original metadata information to a unified metadata model, called DatA Tag Suite (DATS), and (2) a search engine that finds relevant datasets based on user-entered queries. In addition to describing its architecture and techniques, we evaluated individual components within DataMed, including the accuracy of the ingestion pipeline, the prevalence of the DATS model across repositories, and the overall performance of the dataset retrieval engine.
Our manual review shows that the ingestion pipeline could achieve an accuracy of 90% and core elements of DATS had varied frequency across repositories. On a manually curated benchmark dataset, the DataMed search engine achieved an inferred average precision of 0.2033 and a precision at 10 (P@10, the number of relevant results in the top 10 search results) of 0.6022, by implementing advanced natural language processing and terminology services. Currently, we have made the DataMed system publically available as an open source package for the biomedical community.
找到相关数据集对于促进生物医学领域的数据重用很重要,但鉴于生物医学数据的数量和复杂性,这具有挑战性。在此,我们描述了一个名为DataMed的开源生物医学数据发现系统的开发,其目标是促进生物医学领域中更多数据索引的构建。
DataMed由美国国立卫生研究院资助的生物医学与医疗保健数据发现索引生态系统(bioCADDIE)联盟开发,它可以跨存储库对各种类型的生物医学数据集进行高效索引和搜索。它由两个主要组件组成:(1)一个数据摄取管道,该管道收集原始元数据信息并将其转换为统一的元数据模型,称为数据标签套件(DATS);(2)一个搜索引擎,该引擎根据用户输入的查询查找相关数据集。除了描述其架构和技术外,我们还评估了DataMed中的各个组件,包括摄取管道的准确性、DATS模型在各存储库中的流行程度以及数据集检索引擎的整体性能。
我们的人工审核表明,摄取管道的准确率可达90%,且DATS的核心元素在各存储库中的出现频率各不相同。在一个人工整理的基准数据集上,通过实施先进的自然语言处理和术语服务,DataMed搜索引擎的推断平均精度达到0.2033,前10项结果的精度(P@10,前10个搜索结果中的相关结果数量)达到0.6022。目前,我们已将DataMed系统作为开源软件包向生物医学社区公开提供。